Функция Sleep
Поток может сообщить системе не выделять ему процессорное время на определенный период, вызвав:
VOID Sleep(DWORD dwMilliseconds);
Эта функция приостанавливает поток па dwMilliseconds миллисекунд. Отметим несколько важных моментов, связанных с функцией Sleep.
Вызывая Sleep, поток добровольно отказывается от остатка выделенного ему кванта времени. Система прекращает выделять потоку процессорное время на период, примерно равный заданному. Все верно: если Вы укажете остановить поток на 100 мс, приблизительно на столько он и "заснет", хотя не исключено, что его сон продлится на несколько секунд или даже минут больше. Вспомните, Windows не является системой реального времени. Ваш поток может возобновиться в заданный момент, но это зависит от того, какая ситуация сложится в системе к тому времени. Вы можете вызвать Sleep и передать в dwMilliseconds значение INFINITE, вообще запретив планировать поток. Но это не очень практично — куда лучше корректно завершить поток, освободив его стек и объект ядра. Вы можете вызвать Sleep и передать в dwMilliseconds нулевое значение. Тогда Вы откажетесь от остатка своего кванта времени и заставите систему подключить к процессору другой поток. Однако система может снова запустить Ваш поток, если других планируемых потоков с тем же приоритетом нет.
Функция TerminateProcess
Вызов функции TerminateProcess тоже завершает процесс:
BOOL TerminateProcess( HANDLE hProcoss, UINT fuExitCode);
Главное отличие этой функции от ExitProcess в том, что ее может вызвать любой поток и завершить любой процесс. Параметр bProcess идентифицирует описатель завершаемого процесса, а в параметре fuExitCode возвращается код завершения про цесса.
Пользуйтесь TerminateProcess лишь в том случае, когда иным способом завершить процесс не удается. Процесс не получает абсолютно никаких уведомлений о том, что он завершается, и приложение не может ни выполнить очистку, ни предотвратить свое неожиданное завершение (если оно, конечно, не использует механизмы защиты). При этом теряются все данные, которые процесс не успел переписать из памяти на диск.
Процесс действительно не имеет ни малейшего шанса самому провести очистку, но операционная система высвобождает всс принадлежавшие ему ресурсы: возвраща ет себе выделенную им память, закрывает любые открытые файлы, уменьшает счет чики соответствующих объектов ядра и разрушает все его User- и GDI-объекты.
По завершении процесса (не важно каким способом) система гарантирует: после него ничего не останется — даже намеков на то, что он когда-то выполнялся. Завер шенный процесс не оставляет за собой никаких следов. Надеюсь, я сказал ясно.
NOTE
TerminateProcess — функция асинхронная, т. e. она сообщает системе, что Вы хотите завершить процесс, но к тому времени, когда она вернет управление, процесс может быть еще не уничтожен. Так что, если Вам нужно точно знать момент завершения процесса, используйте WaitForSingleObject (см. главу 9) или аналогичную функцию, передав ей описатель этого процесса.
Функция TerminateThread
Вызов этой функции также завершает поток:
BOOL TerminateThread( HANDLE hThread, DWORD dwExitCode);
В отличие от ExitThread, которая уничтожает только вызывающий поток, эта функция завершает поток, указанный в параметре hThread. В параметр dwExitCode Вы помещаете значение, которое система рассматривает как код завершения потока. После того как поток будет уничтожен, счетчик пользователей его объекта ядра "поток" уменьшится на 1.
NOTE:
TerminateThread — функция асинхронная, т.e. она сообщает системе, что Вы хотите завершить поток, но к тому времени, когда она вернет управление, поток может быть еще не уничтожен. Так что, если Вам нужно точно знать момент завершения потока, используйте WaitForSingleObject (см. главу 9) или аналогичную функцию, передав ей описатель этого потока
Корректно написанное приложение не должно вызывать эту функцию, поскольку поток не получает никакого уведомления о завершении; из-за этого он не может выполнить должную очистку ресурсов.
NOTE:
Уничтожение потока при вызове ExitThread или возврате управления из функции потока приводит к разрушению его стека. Но если он завершен функцией TerminateThread, система не уничтожает стек, пока не завершится и процесс, которому принадлежал этот поток Так сделано потому, что другие потоки могут использовать указатели, ссылающиеся на данные в стеке завершенного потока. Если бы они обратились к несуществующему стеку, произошло бы нарушение доступа.
Кроме того, при завершении потока система уведомляет об этом все DLL, подключенные к процессу — владельцу завершенного потока. Но при вызове TetminateThread такого не происходит, и процесс может быть завершен некорректно (Подробнее на этутему см. главу 20.)
Функция UnhandledExceptionFilter изнутри
Начав работать с исключениями, я решил, что можно извлечь массу информации, если детально вникнуть в механизм работы функции UnhandledExceptionFilter. Поэтому я тщательно его исследовал. Вот что делает функция UnhandledExceptionFilter.
1. Если возникло нарушение доступа и его причина связана с попыткой записи, система проверяет, не пытались ли Вы модифицировать ресурс в EXE- или DLL модуле. По умолчанию такие ресурсы предназначены только для чтения. Од нако 16-разрядная Windows разрешала модифицировать эти ресурсы, и из соображений обратной совместимости такие операции должны поддерживать ся как в 32-, так и в 64-разрядной Windows Поэтому, когда Вы пытаетесь мо дифицировать ресурс, UnhandledExeptionFilter вызывает VirtualProtect для из менения атрибута защиты страницы с этим ресурсом на PAGE_READWRTTE и возвpamae EXCEPTION_CONTINUE_EXECUTION.
2. Если Вы установили свой фильтр вызовом SetUnhandledExceptionFilter, функция UnhandledExceptionFilter обращается к Вашей функции фильтра. И если она возвращает EXCEPTION_EXECUTE_НANDLER или EXCEPTION_CONTINUE_EXE CUTION, UnhandledExceptionFilter передает его системе. Но, если Вы не устанав ливали свой фильтр необработанных исключений или если функция фильтра возрращает EXCEPTION_CONTINUE_SEARCH, UnhandledExceptionFilter перехо дит к операциям, описанным в п. 3
WINDOWS 98
Из-за ошибки в Windows 98 Ваша функция фильтра необработанных исклю чений вызывается, только если к процессу не подключен отладчик. По той же причине в Windows 98 невозможна отладка программы Spreadsheet, представ ленной в следующем разделе
3. Если Ваш процесс выполняется под управлением отладчика, то возвращается EXCEPTION_CONTINUE_SEARCH. Это может показаться странным, так как сис тема уже выполняет самый "верхний" блок try или except и другого фильтра выше по дереву вызовов просто нст lIo, обнаружив этот факт, система сооб щит отладчику о необработанном исключении в подопечном ему процессе. В ответ на это отладчик выведет окно, где предложит пачать отладку (Кстати, функция IsDebuggerPresent позволяет узнать, работает ли данный процесс под управлением очладчика.)
4. Если поток в Вашем процессе вызовет SetErrorMode с флагом SEM_NOGPFAUL TERRORBOX, то UnhandledExceptionFilter вернет EXCEPTION_EXECUTE_HANDLER.
5. Если процесс включен в задание (см. главу 5), на которое наложено ограниче ние JOB_OBJECT_LIMIT_DIE_ON_UNHANDLED_EXCEPTION, то UnhandledExcep tionFtlter также вернет EXCEPTION_EXECUTE_HANDLER
WINDOWS 98
Windows 98 не поддерживает задания, и в ней этот этап пропускается.
6. UnhandledExceptionFilter считывает в реестре значение параметра Auto. Если оно равно 1, происходит переход на этап 7, в ином случае выводится окно с информацией об исключении. Если в реестре присутствует и параметр Debug ger, в этом окне появляются кнопки OK и Cancel. A если этого параметра нет — только кнопка ОК. Как только пользователь щелкнет кнопку OK, функция UnbandledExceptionFilter вернет EXCEPTION_EXECUTE_HANDLER. Щелчок кноп ки Cancel (если она ссть) вызывает переход на следующий этап.
WINDOWS 98
В Windows 98 упомянутые параметры хранятся не в реестре, а в файле Win.ini.
7. На этом этапе UnhandledExceptionFilter запускает отладчик как дочерний про цесс. Но сначала создает событие со сбросом вручную в занятом состоянии и наследуемым описателем. Затем извлекает из реестра значение параметра Debugger и вызывает sprintf для вставки идентификатора процесса (получен ного через функцию GetCurrentProcessd) и описателя события в командную строку. Элементу lpDesktop структуры STARTUPINFO присваивается значение "Winsta0\\Default", чтобы отладчик был доступен в интерактивном рсжимс на рабочем столе. Далее вызывается CreateProcess со значением TRUE в парамет ре bInherttHandles, благодаря чему отладчик получает возможность наследовать описатель объекта "событие" После этого UnhandledExceptionFilter ждет завер шения инициализации отладчика, вызвав WaitForSingleObjectEx с передачей ей описателя события. Заметьте, что вместо WaitForSingleObject используется Wait ForSingleObjectEx Это заставляет поток ждать в "тревожном* состоянии, кото рое позволяет ему обрабатывать все поступающие AРС-вызовы.
8. Закончив инициализацию, отладчик освобождает- событие, и поток Unbandled ExceptionFilter пробуждается. Теперь, когда процесс находится под управлени ем отладчика, UnbandledExceptionFilter возвращает EXCEPTION_CONTINUE_ SEARCH. Обратите внимание: все, что здесь происходит, точно соответствует этапу 3.
Функция входа/выхода
В DI,T, может быть лишь одна функция входа/выхода Система вызывает ее в некоторых ситуациях (о чем речь еще впереди) сугубо в информационных целях, и обычно она используется ULL для инициализации и очистки ресурсов в конкретных процессах или потоках Если Вашей DLL подобные уведомления не нужны, Вы не обязаны реализовывать эту функцию. Пример — DLL, содержащая только ресурсы. Но если же уведомления необходимы, функция должна выглядеть так:
BOOL WINAPI DllMain(HINSTANCE hinstDll, DWORD fdwReason, PVOID fImpLoad)
{
switch (fdwReason)
{
case DLL_PROCESS_ATTACH:
// DLL проецируется на адресное пространство процесса
break;
case DLL_THREAD_ATTACH:
// создается поток
break;
case DLL_THREAD_DETACH:
// поток корректно завершается
break;
case DLL PROCESS_DETACH
// DLL отключается от адресного пространства процесса
break;
}
return(TRUE);
// используется только для DLL_PROCESS_ATTACH
}
NOTE:
При вызове DllMain надо учитывать регистр букв Многие случайно вызывают DLLMain, и это вполне объяснимо- термин DLL обычно пишется заглавными буквами. Если Вы назовете функцию входа/выхода не DllMain, а как-то иначе . (пусть даже только один символ будет набран в другом регистре), компиляция и компоновка Вашего кода пройдет без проблем, но система проигнорирует такую функцию входа/выхода, и Ваша DLL никогда не будет инициализирована.
Параметр hinstDll содержит описатель экземпляра DLL, Как и hinstExe функции (w)WinMain, это значение — виртуальный адрес проекции файла DLL на адресное пространство процесса. Обычно последнее значение сохраняется в глобальной переменной, чтобы его можно было использовать и при вызовах функций, загружающих ресурсы (типа DialogBox или LoadString), Последний параметр, fImpLoad, отличен от 0, если DLL загружена неявно, и равен 0, если она загружена явно.
Параметр fdwReason сообщает о причине, по которой система вызвала эту функцию. Он принимает одно из четырех значений: DLL_PROCESS_ATTACH, DLL_PROCESS_DETACH, DLL_THREAD_ATTACH или DLL_THREAD_DETACH.
Мы рассмотрим их в следующих разделах.
NOTE:
Не забывайте, что DLL инициализируют себя, используя функции DllMain. К моменту выполнения Вашей DllMain другие DLL в том же адресном пространстве могут не успеть выполнить свои функции DllMain, т. e. они окажутся неинициализированными. Поэтому Вы должны избегать обращений из DllMain к функциям, импортируемым из других DLL. Кроме того, не вызывайте из DllMain функции LoadLibrary(Ex) и FreeLibrary, так как это может привести к взаимной блокировке.
В документации Platform SDK утверждается, что DllMain должна выполнять лишь простые виды инициализации — настройку локальной памяти потока (см. главу 21), создание объектов ядра, открытие файлов и т. д. Избегайте обращений к функциям, связанным с User, Shell, ODBC, COM, RPC и сокетами (а также к функциям, которые их вызывают), потому что соответствующие DLL могут быть еще не инициализированы. Кроме того, подобные функции могут вызывать LoadLibrary(Ex) и тем самым приводить к взаимной блокировке.
Аналогичные проблемы возможны и при создании глобальных или статических С++-объектов, поскольку их конструктор или деструктор вызывается в то же время, что и Ваша DllMain.
Функция VMQuery
Начиная изучать архитектуру памяти в Windows, я пользовался функцией VirtualQuery как "поводырем". Если Вы читали первое издание моей книги, то заметите, что программа VMMap была гораздо проще ее нынешней версии, представленной в следующем разделе. Прежняя была построена на очень простом цикле, из которого периодически вызывалась функция VirtualQuery, и для каждого вызова я формировал одпу строку, содержавшую элементы структуры MEMORY_BASIC_INFORMATION. Изучая полученные дампы и сверяясь с документацией из SDK (в то время весьма неудачной), я пытался разобраться в архитектуре подсистемы управления памятью. Что ж, с тех пор я многому научился и теперь знаю, что функция VirtualQuery и структура MEMORY_BASIC_INFORMATION не дают полной картины.
Проблема в том, что в MEMORY_BASIC_INFORMATION возвращается отнюдь не вся информация, имеющаяся в распоряжении системы. Если Вам нужны простейшие данные о состоянии памяти по конкретному адресу, VirtualQuery действительно незаменима. Она отлично работает, если Вас интересует, передана ли по этому адресу физическая память и доступен ли он для операций чтения или записи. Но попробуйте с её помощью узнать общий размер зарезервированного региона и количество блоков в нем или выяснить, не содержит ли этот регион стек потока, — ничего не выйдет.
Чтобы получать более полную информацию о памяти, я создал собственную функцию и назвал ее VMQuery.
BOOL VMQuery( HANDLE hProcess, PVOID pvAddress, PVMQUERY pVMQ);
По аналогии с VirtualQueryEx она принимает в hProcess описатель процесса, в pvAddress - адрес памяти, а в pVMQ — указатель на структуру, заполняемую самой функцией. Структура VMQUERY (тоже определенная мной) представляет собой вот что.
typedef struct
{
// информация о регионе
PVOID pvRgnBaseAddress;
DWORD dwRgnProtection;
// PAGE_*
SIZE_T RgnSize;
DWORD dwRgnStorage;
// MEM_* Free. Irnage, Mapped, Private
DWORD dwRgnBlocks;
DWORD dwRgnGuardBlks; // если > 0, регион содержит стек потока
BOOL tRqnlsAStack; // TRUE, если регион содержит стек потока
// информация о блоке
PVOID pvBlkBaseAddress;
DWORD dwBlkProtection;
// PAGE_*
SIZE_T BlkSize;
DWORD dwBlkStorage;
// MEM_* Free, Reserve, Image, Mapped, Private
} VMQUERY, *PVMQUERY;
С первого взгляда заметно, что моя структура VMQUERY содержит куда больше информации, чем MEMORY_BASIC_INFORMATION. Она разбита (условно, конечно) на две части: в одной — информация и регионе, в другой — информация о блоке (адрес которого указан в параметре pvAddress). Элементы этой структуры описываются в следующей таблице.
| Элемент | Описание |
| pvRgnBaseAddress | Идентифицирует базовый адрес региона виртуального адресного про странства, включающего адрес, указанный в параметре pvAddress |
| dwRgnProtection | Сообщает атрибут защиты, присвоенный региону при его резервиро вании. |
| RgnSize | Указывает размер (в байтах) зарезернириванного о региона. |
| dwRgnStorage | Идентифицирует тип физической памяти, используемой группой бло ков данного peгиона: MEM_FREE, MEM_IMAGE, MEM_MAPPED или MEM PRIVATE. Поскольку Windows 98 не различает типы памяти, в этой операционной системе данный элемент содержит либо MEM_FREE, либо MEM_PRIVATE |
| dwRgnBlocks | Содержит значение — число блоков в указанном регионе |
| dwRgnGuardBlks | Указывает число блоков с установленным флагом атрибутов защиты PAGE GUARD. Обычно это значение либо 0, либо 1. Если оно равно 1, то регион скорее всего зарезервирован под стек потока В Windows 98 этот элемент всегда равен 0 |
| fRgnIsAStack | Сообщает, есть ли в данном регионе стек потока Результат определяется на основе взвешенной оценки, так как невозможно дать стопроцентной гарантии тому, что в регионе содержится стек. |
| pvBlkBaseAddress | Идентифицирует базовый адрес блока, включающего адрес, указанный в параметре pvAddress, |
| dwBlkProtection | Идентифицирует атрибут защиты блока, включающего адрес, указанный в параметре pvAddress. |
| BlkSize | Содержит значение — размер блока (в байтах), включающего адрес, указанный в параметре pvAddress. |
| dwBlkStorage | Идентифицирует содержимое блока, включающего адрес, указанный в параметре pvAddress. Принимает одно из значений: MEM_FREE, MEM_RESERVE, MEM_IMAGE, MEM_MAPPED или MEM_PRIVATE. В Windows 98 этот элемент никогда не содержит значения MEM_IMAGE и MEM_MAPPED |
Чтобы получить всю эту информацию, VMQuery, естественно, приходится выполнять гораздо болыше операций (в том числе многократно вызывать VirtualQueryEx), а потому она работает значительно медленнее VirtualQueryEx. Так что Вы должны все тщательно взвесить, прежде чем остановить свой выбор на одной из этих функций. Если Вам не нужна дополнительная информация, возвращаемая VMQuery, используйте VirtualQuery или VirtualQueryEx.
Листинг файла VMQuery.cpp (рис. 14-3) показывает, как я получаю и обрабатываю данные, необходимые для инициализации элементов структуры VMQUERY. (Файлы VMQuery.cpp и VMQueryh содержатся в каталоге 14-VMMap на компакт-диске, прилагаемом к книге.) Чтобы не объяснять подробности обработки данных "на пальцах", я снабдил тексты программ массой комментариев, вольно разбросанных по всему коду.

Функция WaitForDebugEvent
В Windows встроены богатейшие отладочные средства Начиная исполнение, отлад чик подключает себя к отлаживаемой программе, а потом просто ждет, когда опера ционная система уведомит его о каком-нибудь событии отладки, связанном с этой программой Ожидание таких событий осуществляется через вызов
BOOL WaitForDebugEvent( PDEBLIG_F_VENT pde, DWORD dwMimseconds);
Когда отладчик вызывает WaitForDebugEvent, его поток приостанавливается Сис тема уведомит поток о событии отладки, разрешив функции WaitForDebugEvent вер нуть управление. Структура, на которую указывает параметр pdе, заполняется систе мой перед пробуждением потока отладчика В ней содержится информация, касаю щаяся только что произошедшего события отладки.
Функция WaitForlnputldle
Поток может приостановить себя и вызовом WaitForlnputIdle:
DWORD WaitForInputIdle( HANDLE hProcess, DWORD dwMilliseconds);
Эта функция ждет, пока у процесса, идентифицируемого описателем bProcess, не опустеет очередь ввода в потоке, создавшем первое окно приложения. WaitForlnputldle полезна для применения, например, в родительском процессе, который порождает дочерний для выполнения какой-либо нужной ему работы. Когда один из потоков родительского процесса вызывает CreateProcess, он продолжает выполнение и в то время, пока дочерний процесс инициализируется. Этому потоку может понадобить ся описатель окна, создаваемого дочерним процессом. Единственная возможность узнать о моменте окончания инициализации дочернего процесса — дождаться, когда тот прекратит обработку любого ввода Поэтому после вызова CreateProcess поток родительского процесса должен вызвать WaitForInputIdle.
Эту функцию можно применить и в том случае, когда Вы хотите имитировать в программе нажатие каких-либо клавиш. Допустим, Вы асинхронно отправили в глав ное окно приложения следующие сообщения:
WM_KEYDOWN с виртуальной клавишей VK_MENU
WM_KEYDOWN с виртуальной клавишей VK_F
WM_KEYUP с вирчуальной клавишей VK_F
WM_KEYUP с виртуальной клавишей VK_MENU
WM_KEYDOWN с виртуальной клавишей VK_O
WM_KEYUP с виртуальной клавишей VK_O
Эта последовательность дает тот же эффект, что и нажатие клавиш Alt+F, О, — в большинстве англоязычных приложений это вызывает команду Open из меню File. Выбор данной команды открывает диалоговое окно; но, прежде чем оно появится на экране, Windows должна загрузить шаблон диалогового окна из файла и "пройтись" по всем элементам управления в шаблоне, вызывая для каждого из них функцию CreateWindow. Разумеется, на это уходит какое-то время. Поэтому приложение, асин хронно отправившее сообщения типа WM_KEY*, теперь может вызвать WaitForlnput ldle и таким образом перейти в режим ожидания до того момента, как Windows за кончит создание диалогового окна и оно будет готово к приему данных от пользова теля. Далее программа может передать диалоговому окну и сго элементам управле ния сообщения о еще каких-то клавишах, что заставит диалоговое окно проделать те илииныеоперации.
С этой проблемой, кстати, сталкивались многие разработчики приложений для 16 разрядной Windows Программам нужно было асинхронно передавать сообщения в окно, но получить точной информации о том, создано ли это окно и готово ли к работе, они не могли. Функция WaitForlnputldle решает эту проблему
Unicode
Глава 2 - Unicode
Microsoft Windows становится все популярнее, и нам, разработчикам, надо больше ориентироваться на международные рынки. Раньше считалось нормальным, что локализованные версии программных продуктов выходят спустя полгода после их появления в США. Но расширение поддержки в операционной системе множества самых разных языков упрощает выпуск программ, рассчитанных на международные рынки, и тем самым сокращает задержки с началом их дистрибуции.
В Windows всегда были средства, помогающие разработчикам локализовать свои приложения. Программа получает специфичную для конкретной страны информацию (региональные стандарты), вызывая различные функции Windows, и узнает предпочтения пользователя, анализируя параметры, заданные в Control Panel. Кроме того, Windows поддерживает массу всевозможных шрифтов.
Я решил переместить эту главу в начало книги, потому что вопрос о поддержке Unicode стал одним из основных при разработке любого приложения. Проблемы, связанные с Unicode, обсуждаются почти в каждой главе; все программы-примеры в моей книге "готовы к Unicode". Тот, кто пишет программы для Microsoft Windows 2000 или Microsoft Windows CE, просто обязан использовать Unicode, и точка. Но если Вы разрабатываете приложения для Microsoft Windows 98, у Вас еще есть выбор. В этой главе мы поговорим и о применении Unicode в Windows 98.
Объекты ядра
Глава 3 - Объекты ядра
Изучение Windows API мы начнем с объектов ядра и их описателей (handles). Эта глава посвящена сравнительно абстрактным концепциям, т. e. мы, не углубляясь в специфику тех или иных объектов ядра, рассмотрим их общие свойства.
Я бы предпочел начать с чего-то более конкретного, но без четкого понимания объектов ядра Вам не стать настоящим профессионалом в области разработки Windows-программ. Эти объекты используются системой и нашими приложениями для управления множеством самых разных ресурсов процессами, потоками, файлами и т.д. Концепции, представленные здесь, будут встречаться на протяжении всей книги. Однако я прекрасно понимаю, что часть материалов не уляжется у Вас в голове до тех пор, пока Вы не приступите к работе с объектами ядра, используя реальные функции. И при чтении последующих глав книги Вы, наверное, будете время от времени возвращаться к этой главе.
Процессы
Часть II - Начинаем работать
Глава 4 - Процессы
Эта глава о том, как система управляет выполняемыми приложениями. Сначала я определю понятие "процесс" и объясню, как система создает объект ядра "процесс". Затем я покажу, как управлять процессом, используя сопоставленный с ним объект ядра. Далее мы обсудим атрибуты (или свойства) процесса и поговорим о нескольких функциях, позволяющих обращаться к этим свойствам и изменять их. Я расскажу также о функциях, которые создают (порождают) в системе дополнительные процессы. Ну и, конечно, описание процессов было бы неполным, если бы я не рассмотрел механизм их завершения. О'кэй, приступим.
Процесс обычно определяют как экземпляр выполняемой программы, и он состоит из двух компонентов:
объекта ядра, через который операционная система управляет процессом. Там же хранится статистическая информация о процессе; адресного пространства, в котором содержится код и данные всех EXE- и DLL модулей. Именно в нем находятся области памяти, динамически распределяемой для стеков потоков и других нужд.
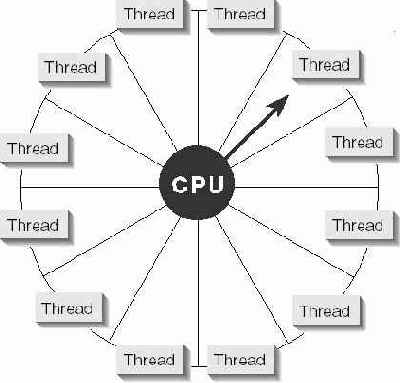
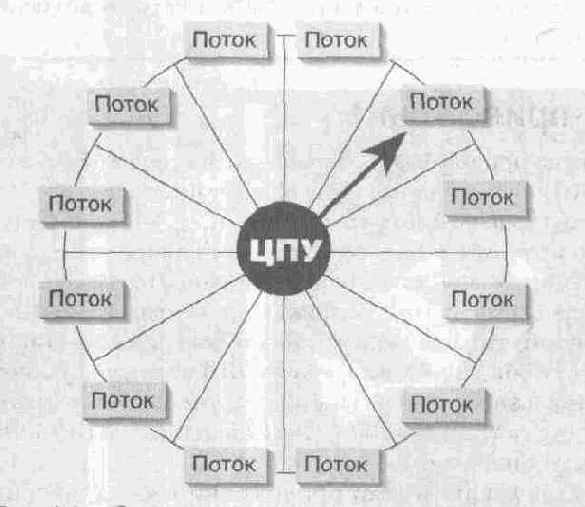
Рис. 4-1. Операционная система выделяет потокам кванты времени по принципу карусели
Процессы инертны. Чтобы процесс что-нибудь выполнил, в нем нужно создать поток. Именно потоки отвечаю за исполнение кода, содержащегося в адресном пространстве процесса В принципе, один процесс может владеть несколькими потоками, и тогда они "одновременно" исполняют код в адресном пространстве процесса.
Для этого каждый поток должен располагать собственным набором регистров процессора и собственным стеком. В каждом процессе есть минимум один поток. Если бы у процесса не было ни одного потока, ему нечего было бы делать на этом свете, и система автоматически уничтожила бы его вместе с выделенным ему адресным пространством.
Чтобы все эти потоки работали, операционная система отводит каждому из них определенное процессорное время. Выделяя потокам отрезки времени (называемые квантами) по принципу карусели, она создает тем самым иллюзию одновременного выполнения потоков.
Рис 4- 1 иллюстрирует распределение процессорного времени между потоками на машине с одним процессором. Если в машине установлено более одного процессора, алгоритм работы операционной системы значительно усложняется (в этом случае система стремится сбалансировать нагрузку между процессорами).
При создании процесса первый (точнее, первичный) поток создается системой автоматически. Далее этот поток может породить другие потоки, те в свою очередь — новые и т.д.
WINDOWS 2000
Windows 2000 в полной мере использует возможности машин с несколькими процессорами. Например, эту книгу я писал, сидя за машиной с двумя процессорами. Windows 2000 способна закрепить каждый поток за отдельным процессором, и тогда два потока исполняются действительно одновременно. Ядро Windows 2000 полностью поддерживает распределение процессорного времени между потоками и управление ими на таких системах. Вам не придется делать ничего особенного в своем коде, чтобы задействовать преимущества многопроцессорной машины.
WINDOWS 98
Windows 98 работает только с одним процессором. Даже если у компьютера несколько процессоров, под управлением Windows 98 действует лишь один из них — остальные простаивают.
Задания
Глава 5 - Задания
Гpynny процессов зачастую нужно рассматривать как единую сущность. Например, когда Вы командуете Microsoft Developer Studio собрать проект, он порождает процесс Ct.exe, а тот в свою очередь может создать другие процессы (скажем, для дополнительных проходов компилятора). Но, если Вы пожелаете прервать сборку, Developer Studio должен каким-то образом завершить C1.exe и все его дочерние процессы. Решение этой простой (и распространенной) проблемы в Windows было весьма затруднительно, поскольку она не отслеживает родственные связи между процессами. В частности, выполнение дочерних процессов продолжается даже после завершения родительского.
При разработке сервера тоже бывает полезно группировать процессы. Допустим, клиентская программа просит сервер выполнить приложение (которое создает ряд дочерних процессов) и сообщить результаты. Поскольку к серверу может обратиться сразу несколько клиентов, было бы неплохо, если бы он умел как-то ограничивать ресурсы, выделяемые каждому клиенту, и тем самым не давал бы одному клиенту монопольно использовать все серверные ресурсы. Под ограничения могли бы подпадать такие ресурсы, как процессорное время, выделяемое на обработку клиентского запроса, и размеры рабочего набора (working set). Кроме того, у клиентской программы не должно быть возможности завершить работу сервера и т.д.
В Wmdows 2000 введен новый объект ядра — задание job). Он позволяет группировать процессы и помещать их в нечто вроде песочницы, которая определенным образом ограничивает их действия. Относитесь к этому объекту как к контейнеру процессов. Кстати, очень полезно создавать задание и с одним процессом — это позволяет налагать на процесс ограничения, которые иначе указать нельзя.
Взгляните на мою функцию StartRestrictedProcess (рис. 5-1). Она включает процесс в задание, которое ограничивает возможность выполнения определенных операций:
WININDOWS 98
Windows 98 не поддерживает задания.
void StartRestictedProcess() {
// создаем объект ядра "задание" HANDLE hjob = CreateJobObject(NULL, NULL);
// вводим oграничения для процессов в задании
// сначала определяем некоторые базовые ограничения
JOBOBJECT_BASIC_LIMIT_INFORMATION jobli = { 0 };
// процесс всегда выполняется с классом приоритета idle
jobli.PriontyClass = IDLE_PRIORITY_CLASS;
// задание не может использовать более одной секунды процессорного времени
jobli.PerJobUserTimeLimit.QuadPart = 10000000;
// 1 секунда, выраженная в 100-наносекундных интервалах
// два ограничения, которые я налагаю на задание (процесс)
jobli.LimitFlags = JOB_OBJECT_LIMIT_PRIORITY_CLASS | JOB_OBJECT_LIMIT_JOB_TIME;
SetInforrnationJobObject(hjob, JobOb]ectBasicLimitInformation, &jobli, sizeof(jobli));
// теперь вводим некоторые ограничения по пользовательскому интерфейсу
JOBOBJECT_BASIC_UI_RESTRICTIONS jobuir;
jobuir.UTRestrictionsClass = JOB_OBJECT_UILIMIT_NONE;
// "замысловатый" нуль
// процесс не имеет права останавливать систему
jobuir.UIRestrictionsClass |= JOB_OBJECT_UILIMIT_EXITWINDOWS;
// процесс не имеет права обращаться к USER-объектам в системе (например, к другим окнам)
jobuir.UIRestrictionsClass |= JOB_OBJECT_UILIMIT_HANDLES;
SetInrormationJobObject(hjob, JobObjectBasicUIRestrictions, &jobuir, sizeof(jobuir));
// Порождаем процесс, который будет размещен в задании.
// ПРИМЕЧАНИЕ: процесс нужно сначала создать и только потом поместить
// в задание А это значит, что поток процесса должен быть создан
// и тут же приостановлен, чтобы он не смог выполнить какой-нибудь код
// еще до введения ограничений,
STARTUPTNFO si = { sizeof(si) };
PROCESS_INFORMATION pi;
CreatePiocess(NULL, "CMD", NULL, NULL, FALSE, CREATE_SUSPENDED, NULL, NULL, &si, &pi);
// Включаем процесс в задание
// ПРИМЕЧАНИЕ, дочерние процессы, порождаемые этим процессом,
// автоматически становятся частью того же задания.
AssignProcessToJobObject(hjob, pi hProcess);
// теперь потоки дочерних процессов могут выполнять код
ResumeThread(pi.hThread);
CloseHandle(pi.hThread);
// ждем, когда процесс завершится или будет исчерпан
// лимит процессорного времени, указанный для задания
HANDLE h[2];
h[0] = pi.hProcess;
h[1] = hjob;
DWORD dw = WaitForMultipleObjects(2, h, FALSE, INFINITE);
switch (dw - WAIT_OBJECT_0){
case 0: // процесс завершился.,
break;
case 1:
// лимит процессорного времени исчерпан
break;
}
// проводим очистку
CloseHandle(pi hProcess), CloseHandle(hjob);
}
Рис. 5-1. Функция StartRestrictedProcess
А теперь я объясню, как работает StartRestrictedProcess. Сначала я создаю новый объект ядра "задание", вызывая:
HANDLE CreateJobObject( PSECURITY_ATTRIBUTES psa, PCTSTR pszName);
Как и любая функция, создающая объекты ядра, CreateJobObject принимает в первом параметре информацию о защите и сообщает системе, должна ли она вернуть наследуемый описатель. Параметр pszName позволяет присвоить заданию имя, что бы к нему могли обращаться другие процессы через функцию OpenJobObject.
HANDLE OpenJobObject( DWORD dwDesiredAccess, BOOL bInheritHandle, PCTSTR pszName);
Закончив работу с объектом-заданием, закройте сго описатель, вызвав, как всегда, CloseHandle. Именно так я и делаю в конце своей функции StartRestrictedProcess. Имейте в виду, что закрытие объекта-задания не приводит к автоматическому завершению всех его процессов. На самом деле этот объект просто помечается как подлежащий разрушению, и система уничтожает его только после завершения всех включенных в него процессов.
Заметьте, что после закрытия описателя объект-задание становится недоступным для процессов, даже несмотря на то, что объект все еще существует. Этот факт иллюстрирует следующий код:
// создаем именованный объект-задание
HANDlF hjob = CreateJobObject(NULL, TEXT("Jeff"));
// включаем в него наш процесс
AssignProcessToJobObject(hjob, GetCurrentProcess());
// закрытие обьекта-задания не убивает ни наш процесс, ни само задание,
// но присвоенное ему имя ('Jeff') моментально удаляется
CloseHandle(hjob);
// пробуем открыть существующее задание
hjob = OpenJobObject(JOB_OBJECT_ALL_ACCESS, FALSE, TEXT("Jeff"));
// OpenJobOb]ect терпит неудачу и возвращает NULL, поскольку имя ('Jeff")
// уже не указывает на объект-задание после вызова CloseHandle; // получить описатель этого объекта больше нельзя
Базовые сведения о потоках
Глава 6 - Базовые сведения о потоках
Тема, связанная потоками, очень важна, потому что в любом процессе должен быть хотя бы один поток. В этой гпаве концепции потоков будут рассмотрены гopaздо подробнее. В частности, я объясню, в чем разница между процессами и потоками и для чего они предназначены. Также я расскажу о том, как система использует объекты ядра "поток" для управления потоками. Подобно процессам, потоки обладают определенными свойствами, поэтому мы поговорим о функциях, позволяющих обращаться к этим свойствам и при необходимости модифицировать их. Кроме того, Вы узнаете о функциях, предназначенных для создания (порождения) дополнительных потоков в системе.
В главе 4 я говорил, что процесс фактически состоит из двух компонентов объекта ядра "процесс" и адресного пространства. Так вот, любой поток тожс состоит из двух компонентов:
объекта ядра, через который операционная система управляет потоком. Там же хранится статистическая информация о потоке; стека потока, который содержит параметры всех функций и локальные переменные, необходимые потоку для выполнения кода. (О том, как система управляет стеком потока, я расскажу в главе 16)
В той же главе 4 я упомянул, что процессы инертны. Процесс ничего не исполняет, он просто служит контейнером потоков. Потоки всегда создаются в контексте какого-либо процесса, и вся их жизнь проходит только в его границах. На практике это означает, что потоки исполняют код и манипулируют данными в адресном пространстве процесса. Поэтому, если два и более потоков выполняется в контексте одного процесса, все они делят одно адресное пространство. Потоки могут исполнять один и тот же код и манипулировать одними и теми же данными, а также совместно использовать описатели объектов ядра, поскольку таблица описателей создается не в отдельных потоках, а в процессах.
Как видите, процессы используют куда больше системных ресурсов, чем потоки. Причина кроется в адресном пространстве. Создание виртуального адресного пространства для процесса требует значительных системных ресурсов. При этом ведется масса всяческой статистики, па что уходит немало памяти. В адресное пространство загружаются EXE- и DLL-файлы, а значит, нужны файловые ресурсы. С другой стороны, потоку требуются лишь соответствующий объект ядра и стек, объем статистических сведений о потоке невелик и много памяти не занимает.
Так как потоки расходуют существенно меньше ресурсов, чем процессы, старайтесь решать свои задачи за счет использования дополнительных потоков и избегайте создания новых процессов. Только не принимайте этот совет за жесткое правило — многие проекты как paз лучше реализовать на основе множества процессов. Нужно просто помнить об издержках и соразмерять цель и средства.
Прежде чем мы углубимся в скучные, но крайне важные концепции, давайте обсудим, как правильно пользоваться потоками, разрабатывая архитектуру приложения.
Планирование потоков, приоритет и привязка к процессорам
Глава 7 - Планирование потоков, приоритет и привязка к процессорам
Операционная система с вытесняющей многозадачностью должна использовать тот или иной алгоритм, позволяющий ей распределять процессорное время между потоками. Здесь мы рассмотрим алгоритмы, применяемые в Windows 98 и Windows 2000. В главе 6 мы уже обсудили структуру CONTEXT, поддерживаемую в объекте ядра "поток", и выяснили, что она отражает состояние регистров процессора на момент последнего выполнения потока процессором. Каждые 20 мс (или около того) Windows просматривает все существующие объекты ядра "поток" и отмечает те из них, которые могут получать процессорное время. Далее она выбирает один из таких объектов и загружает в регистры процессора значения из его контекста. Эта операция на зывается переключением контекста (context switching). По каждому потоку Windows ведет учет того, сколько раз он подключался к процессору. Этот показатель сообщают специальные утилиты вроде Microsoft Spy++. Например, на иллюстрации ниже показан список свойств одного из потоков. Обратите внимание, что этот поток подключался к процессору 37379 раз.
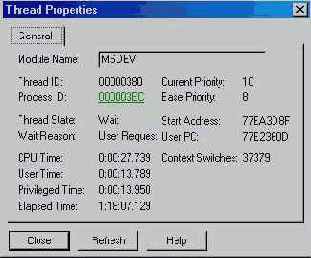
Поток выполняет код и манипулирует данными в адресном пространстве своего процесса Примерно через 20 мс Windows сохранит значения регистров процессора в контексте потока и приостановит его выполнение. Далее система просмотрит остальные объекты ядра "поток", подлежащие выполнению, выберет один из них, загрузит его контекст в регистры процессора, и все повторится. Этот цикл операций — выбор потока, загрузка его контекста, выполнение и сохранение контекста — начинается с момента запуска системы и продолжается до ее выключения.
Таков вкратце механизм планирования работы множества потоков. Детали мы обсудим позже, но главное я уже показал. Все очень просто, да? Windows потому и называется системой с вытесняющей многозадачностью, что в любой момент может приостановить любой поток и вместо него запустить другой. Как Вы еще увидите, этим механизмом можно управлять, правда, крайне ограниченно.
Всегда помните: Вы не в состоянии гарантировать, что Ваш поток будет выполняться непрерывно, что никакой другой поток не получит доступ к процессору и т.д.
NOTE:
Меня часто спрашивают, как сделать так, чтобы поток гарантированно запускался в течение определенного времени после какого-нибудь события — например, не позднее чем через миллисекунду после приема данных с последовательного порта? Ответ прост: никак. Такие требования можно предъявлять к операционным системам реального времени, но Windows к ним не относится. Лишь операционная система реального времени имеет полное представление о характеристиках аппаратных средств, на которых она работает (об интервалах запаздывания контроллеров жестких дисков, клавиатуры и т.д.). А создавая Windows, Microsoft ставила другую цель обеспечить поддержку максимально широкого спектра оборудования — различных процессоров, дисковых устройств, сетей и др. Короче говоря, Windows не является операционной системой реального времени.
Хочу особо подчеркнуть, что система планирует выполнение только тех потоков, которые могут получать процессорное время, но большинство потоков в системе к таковым не относится. Так, у некоторых объектов-потоков значение счетчика простоев (suspend count) больше 0, а значит, соответствующие потоки приостановлены и не получают процессорное время. Вы можете создать приостановленный поток вызовом CreateProcess или CreateThread с флагом CREATESUSPENDED. (В следующем разделе я расскажу и о таких функциях, как SuspendThread и ResumeThread.)
Кроме приостановленных, существуют и другие потоки, не участвующие в распределении процессорного времени, — они ожидают каких-либо событий. Например, если Вы запускаете Notepad и не работаете в нем с текстом, его поток бездействует, а система не выделяет процессорное время тем, кому нечего делать. Но стоит лишь сместить его окно, прокрутить в нем текст или что-то ввести, как система автоматически включит поток Notepad в число планируемых. Это вовсе не означает, что поток Notepad тут же начнет выполняться.Просто система учтет его при планировании потоков и когда-нибудь выделит ему время — по возможности в ближайшем будущем.
Синхронизация потоков в пользовательском режиме
Глава 8 - Синхронизация потоков в пользовательском режиме
Windows лучше всего работает, когда все потоки могут заниматься своим делом, не взаимодействуя друг с другом. Однако такая ситуация очень редка. Обычно поток создается для выполнения определенной работы, о завершении которой, вероятно, захочет узнать другой поток.
Все потоки в системе должны иметь доступ к системным ресурсам — кучам, последовательным портам, файлам, окнам и т.д. Если один из потоков запросит монопольный доступ к какому-либо ресурсу, другим погокам, которым тоже нужен этот ресурс, не удастся выполнить свои задачи. А с другой стороны, просто недопустимо, чтобы потоки бесконтрольно пользовались ресурсами. Иначе может получиться так, что один поток пишет в блок памяти, из которого другой что-то считывает. Представьте, Вы читаете книгу, а в это время кто-то переписывает текст на открытой Вами странице. Ничего хорошего из этого не выйдет.
Потоки должны взаимодействовать друг с другом в двух основных случаях:
совместно используя разделяемый ресурс (чтобы не разрушить его); когда нужно уведомлять другие потоки о завершении каких-либо операций.
Синхронизации потоков — тематика весьма обширная, и мы рассмотрим ее в этой и следующих главах. Одна новость Вас обрадует в Windows есть масса средств, упрощающих синхронизацию потоков. Но другая огорчит: точно спрогнозировать, в какой момент потоки будут делать то-то и то-то, крайне сложно. Наш мозг не умеет работать асинхронно, мы обдумываем свои мысли старым добрым способом — одну за другой по очереди. Однако многопоточная среда ведет себя иначе.
С программированием для многопоточной среды я впервые столкнулся в 1992 г. Поначалу я делал уйму ошибок, так что в главах моих книг и журнальных статьях хватало огрехов, связанных с синхронизацией потоков. Сегодня я намного опытнее и действительно считаю, что уж в этой-то книге все безукоризненно (хотя самонадеянности у меня вроде бы поубавилось). Единственный способ освоить синхронизацию потоков — заняться этим на практике. Здесь и в следующих главах я объясню, как работает система и как правильно синхронизировать потоки. Однако Вам придется стоически переносить трудности, приобретая опыт, ошибок не избежать.
ГЛАВA 9 Синхронизация потоков с использованием объектов ядра
ГЛАВA 9 Синхронизация потоков с использованием объектов ядра
В предыдущей главе мы обсудили, как синхронизировать потоки с применением механизмов, позволяющих Вашим потокам оставаться в пользовательском режиме. Самое удивительное, что эти механизмы работают очень быстро. Поэтому, если Вы озабочены быстродействием потока, сначала проверьте, нельзя ли обойтись синхронизацией в пользовательском режиме.
Хотя механизмы синхронизации в пользовательском режиме обеспечивают высокое быстродействие, им свойствен ряд ограничений, и во многих приложениях они просто не будут работать. Например, Intertocked-функции оперируют только с отдельными переменными и никогда не переводят поток в состояние ожидания Последнюю задачу можно решить с помощью критических секций, но они подходят лишь в тех случаях, когда требуется синхронизировать потоки в рамках одного процесса. Кроме того, при использовании критических секций легко попасть в ситуацию взаимной блокировки потоков, потому что задать предельное время ожидания входа в крити ческую секцию нельзя.
В этой главе мы рассмотрим, как синхронизировать потоки с помощью объектов ядра. Вы увидите, что такие объекты предоставляют куда больше возможностей, чем механизмы синхронизации в пользовательском режиме. В сущности, единственный их недостаток — меньшее быстродействие Дело в том, что при вызове любой из функций, упоминаемых в этой главе, поток должен перейти из пользовательского режима в режим ядра. А такой переход обходится очень дорого — в 1000 процессорных тактов на платформе x86. Прибавьте сюда еще и время, которое необходимо на выполнение кода этих функций в режиме ядра.
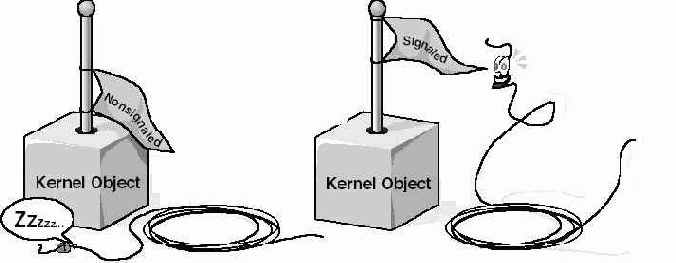
К этому моменту я уже рассказал Вам о нескольких объектах ядра, в том числе о процессах, потоках и заданиях. Почти все они годятся и для решения задач синхронизации. В случае синхронизации потоков о каждом из этих объектов говорят, что он находится либо в свободном (signaled state), либо в занятом состоянии (nonsignaled state) Переход из одного состояния в другое осуществляется по правилам, определенным Microsoft для каждого из объектов ядра Так, объекты ядра "процесс" сразу после создания всегда находятся в занятом состоянии.
В момент завершения процесса операционная система автоматически освобождает его объект ядра "процесс", и он навсегда остается в этом состоянии.
Объект ядра "процесс" пребывает в занятом состоянии, пока выполняется сопоставленный с ним процесс, и переходит в свободное состояние, когда процесс завершается. Внутри этого объекта поддерживается булева переменная, которая при создании объекта инициализируется как FALSE ("занято"). По окончании работы процесса операционная система меняет значение этой переменной на TRUE, сообщая тем самым, что объект свободен.
Если Вы пишете код, проверяющий, выполняется ли процесс в данный момент, Вам нужно лишь вызвать функцию, которая просит операционную систему проверить значение булевой переменной, принадлежащей объекту ядра "процесс". Тут нет ни чего сложного. Вы можете также сообщить системе, чтобы та перевела Ваш поток в состояние ожидания и автоматически пробудила его при изменении значения буле вой переменной с FALSE на TRUE. Тогда появляется возможность заставить поток в родительском процессе, ожидающий завершения дочернего процесса, просто заснуть до освобождения объекта ядра, идентифицирующего дочерний процесс. В дальнейшем Вы увидите, что в Windows есть ряд функций, позволяющих легко решать эту задачу.
Я только что описал правила, определенные Microsoft для объекта ядра "процесс". Точно такие же правила распространяются и на объекты ядра "поток". Они тоже сразу после создания находятся в занятом состоянии. Когда поток завершается, операционная система автоматически переводит объект ядра "поток" в свободное состояние. Таким образом, используя те же приемы, Вы можете определить, выполняется ли в данный момент тот или иной поток. Как и объект ядра "процесс", объект ядра "поток" никогда не возвращается в занятое состояние.
Следующие объекты ядра бывают в свободном или занятом состоянии:
процессы потоки задания файлы консольный ввод уведомления об изменении файлов события ожидаемые таймеры семафоры мьютексы
Потоки могут засыпать и в таком состоянии ждать освобождения какого-либо объекта. Правила, по которым объект переходит в свободное или занятое состояние, зависят от типа этого объекта. О правилах для объектов процессов и потоков я упоминал совсем недавно, а правила для заданий были описаны в главе 5.
В этой главе мы обсудим функции, которые позволяют потоку ждать перехода определенного объекта ядра в свободное состояние. Потом мы поговорим об объектах ядра, предоставляемых Windows специально для синхронизации потоков: событиях, ожидаемых таймерах, семафорах и мьютексах.
Когда я только начинал осваивать всю эту тематику, я предпочитал рассматривать понятия "свободен-занят" по аналогии с обыкновенным флажком. Когда объект свободен, флажок поднят, а когда он занят, флажок опущен.
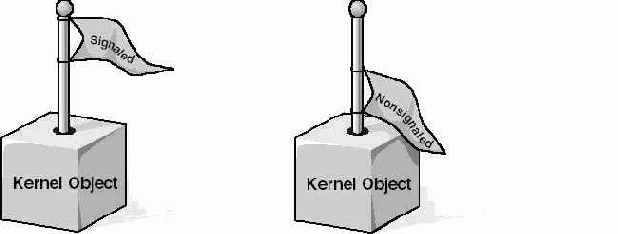
Потоки спят, пока ожидаемыеими объекты заняты (флажок опущен). Как только объект освободился (флажок поднят), спящий поток замечает это, просыпается и возобновляет выполнение.
Полезные средства для синхронизации потоков
Глава 10 - Полезные средства для синхронизации потоков
Зa годы своей практики я часто сталкивался с проблемами синхронизации потоков и поэтому написал ряд С++-классов и компонентов, которыми я поделюсь с Вами в этой главе. Надеюсь, этот код Вам пригодится и сэкономит массу времени при разработке приложений — или по крайней мере чему-нибудь научит.
Я начну главу с того, что расскажу о реализации критической секции и расширении ее функциональности. В частности, Вы узнаете, как пользоваться одной критической секцией в нескольких процессах. Далее Вы увидите, как сделать объекты безопасными для применения в многопоточной среде, создав для собственных типов данных оболочку из С++-класса. Используя такие классы, я попутно представлю объект, ведущий себя прямо противоположно семафору.
Потом мы рассмотрим одну из типичных задач программирования что делать, когда считывает какой-то ресурс несколько потоков, а записывает в него — только один. В Windows нет подходящего на этот случай синхронизирующего объекта, и я написал специальный С++-класс.
Наконец, я продемонстрирую свою функцию WaitForMultipleExpressions. Работая по аналогии с WaitForMultipleObjects, заставляющей ждать освобождения одного или всех объектов, она позволяет указывать более сложные условия пробуждения потока.
Пулы потоков
Глава 11 - Пулы потоков
В главе 8 мы обсудили синхронизацию потоков без перехода в режим ядра. Замечательная особенность такой синхронизации — высокое быстродействие. И если Вы озабочены быстродействием потока, сначала подумайте, нельзя ли обойтись синхронизацией в пользовательском режиме.
Вы уже знаете, что создание многопоточных приложений — дело трудное. Вас подстерегают две серьезные проблемы: управление созданием и уничтожением потоков и синхронизация их доступа к ресурсам. Для решения второй проблемы в Windows предусмотрено множество синхронизирующих примитивов: события, семафоры, мьютексы, критические секции и др. Все они довольно просты в использовании. Но если бы сисгема автоматически охраняла разделяемые ресурсы, вот тогда создавать многопоточные приложения было бы по-настоящему легко. Увы, операционной системе Windows до этого еще далеко.
Проблему того, как управлять созданием и уничтожением потоков, каждый решает по-своему. За прошедшие годы я создал несколько реализаций пулов потоков, рассчитанных на определенные сценарии. Однако в Windows 2000 появился ряд новых функций для операций с пулами потоков; эти функции упрощают создание, уничтожение и общий контроль за потоками. Конечно, встроенные в них механизмы носят общий характер и не годятся на все случаи жизни, но зачастую их вполне достаточно, и они позволяют экономить массу времени при разработке многопоточного приложения.
Эти функции дают возможность вызывать другие функции асинхронно, через определенные промежутки времени, при освобождении отдельных объектов ядра или при завершении запросов на асинхронный ввод-вывод.
Пул подразделяется на четыре компонента, которые описываются в таблице 11-1.
|
Компонент поддержки | |||||||||
|
ожидания |
ввода-вывода |
Других операций таймера | |||||||
|
Начальное число потоков |
Всегда 1 |
1 |
0 |
0 | |||||
|
Когда поток создается |
При вызове первой функции таймера пула потоков |
Один поток для каждых 63 зарегист рированных объектов |
В системе применяются эвристические методы, но на создание потока влияют следующие факторы | ||||||
|
Когда поток разрушается |
При завершении процесса |
При отсутст вии зарегист рированных объектов ожидания |
При отсутствии у потока текущих запросов на ввод-вывод и простое в течение определенного порогового времени (около минуты) |
При простое потока в течение определен ного порогового времени (около минусы) | |||||
|
Как поток ждет |
В "тревожном"состоянии |
WaitFor Multiple ObjectsEx |
В "тревожном" состоянии |
GetQueued CompletionStatus | |||||
|
Когда поток пробуждается |
При освобожде нии "ожидаемого таймера", кото рый посылает в очередь АРС-вызов |
При освобождении объекта ядра |
При посылке в очередь АРС-вызова или завершении запроса на ввод- вывод |
При поступлении запроса о статусе завершения или о завершении ввода вывода (порт завер шения требует, чтобы число потоков не превышало число процессоров более чем в 2 раза) | |||||
Таблица 11-1. Компоненты поддержки пула потоков
При инициализации процесса никаких издержек, связанных с перечисленными в таблице компоненчами поддержки, не возникает. Однако, как только вызывается одна из функций пула потоков, для процесса создается набор этих компонентов, и некоторые из них сохраняются до его завершения. Как видите, издержки от применения этих функций отнюдь не малые: частью Вашего процесса становится целый набор потоков и внутренних структур данных. Так что, прежде чем пользоваться ими, тщательно взвесьте все "за" и "против".
О'кэй, теперь, когда я Вас предупредил, посмотрим, как все это работает.
Волокна
ГЛАВА 12 Волокна
Microsoft добавила в Windows поддержку волокон (fibers), чтобы упростить портирование (перенос) существующих серверных приложений из UNIX в Windows. C точки зрения терминологии, принятой в Windows, такие серверные приложения следует считать однопоточпыми, но способными обслуживать множество клиентов. Иначе говоря, разработчики UNIX-приложений создали свою библиотску для организации многопоючности и с ее помощью эмулируют истинные потоки. Она создает набор стеков, сохраняет определенные регистры процессора и переключает контексты при обслуживании клиентских запросов.
Разумеется, чтобы добиться большей производительности от таких UNIX-приложений, их следует перепроектировать, заменив библиотеку, эмулирующую потоки, на настоящие потоки, используемые в Windows. Ho переработка может занять несколько месяцев, и поэтому компании сначала просто переносят существующий UNIX-код в Windows — это позволяет быстро предложить новый продукт на рынке Windows приложений.
Но при переносе UNIX-программ в Windows могут возникнуть проблемы. В частности, механизм управления стеком потока в Windows куда сложнее простого выделения памяти. В Windows стеки начинают работать, располагая сравнительно малым объемом физической памяти, и растут по мере необходимости (об этом я расскажу в разделе "Стек потока" главы l6). Перенос усложняется и наличием механизма структурной обработки исключений (см. главы 23, 24 и 25).
Стремясь помочь быстрее (и с меньшим числом ошибок) переносить UNIX-код в Windows, Microsoft добавила в операционную систему механизм поддержки волокон. В этой главе мы рассмотрим концепцию волокон и функции, предназначенные для операций с ними. Кроме того, я покажу, как эффективнее работать с такими функциями. Но, конечно, при разработке новых приложений следует использовать настоящие потоки
Исследование виртуальной памяти
Глава 14 - Исследование виртуальной памяти
В предыдущей главе мы выяснили, как система управляет виртуальной памятью, как процесс получает свое адресное пространство и что оно собой представляет. А сейчас мы перейдем от теории к практике и рассмотрим некоторые Windows-функции, сообщающие о состоянии системной памяти и виртуального адресного пространства в том или ином процессе.
Использование виртуальной памяти в приложениях
Глава 15 - Использование виртуальной памяти в приложениях
В Windows три механизма работы с памятью:
виртуальная память — наиболее подходящая для операций с большими массивами обьектов или структур; проецируемые в память файлы — наиболее подходящие для операций с большими потоками данных (обычно из файлов) и для совместного использования данных несколькими процессами на одном компьютере; кучи — наиболее подходящие для работы с множеством малых объектов.
Б этой главе мы обсудим первый метод — виртуальную память. Остальные два метода (проецируемые в память файлы и кучи) рассматриваются соответственно в главах 17 и 18.
Функции, работающие с виртуальной памятью, позволяют напрямую резервировать регион адресного пространова, передавать ему физическую память (из страничного файла) и присваивать любые допустимые атрибуты защиты.
Стек потока
Глава 16 - Стек потока
Иногда система сама резервирует какие-то регионы в адресном пространстве Вашего процесса. Я уже упоминал в главе 13, что это делается для размещения блоков переменных окружения процесса и его потоков. Еще один случай резервирования региона самой системой — создание стека потока.
Всякий раз, когда в процессе создается поток, система резервирует регион адресного пространства для стека потока (у каждого потока свой стек) и передает этому региону какой-то объем физической памяти. По умолчанию система резервирует 1 Мб адресного пространства и передает ему всего две страницы памяти. Но стандартные значения можно изменить, указав при сборке программы параметр компоновщика /STACK:
/STACK. reserve [, commit]
Тогда при создании стека потока система зарезервирует регион адресного пространства, размер которого указан в параметре /STACK компоновщика. Кроме того, объем изначально передаваемой памяти можно переопределить вызовом CreateThread или _beginthreadex. У обеих функций есть параметр, который позволяет изменять объем памяти, изначально передаваемой региону стека. Если в нем передать 0, система будет использовать значение, указанное в параметре /STACK. Далее я исхожу из того, что стек создается со стандартными параметрами.
На рис. 16-1 показано, как может выглядеть регион стека (зарезервированный по адресу 0x08000000) в системе с размером страниц no 4 Кб Регион стека и вся переданная ему память имеют атрибут защиты PAGE_READWRITE.
Зарезервировав регион, система передает физическую память двум верхним его страницам. Непосредственно перед тем, как приступить к выполнению потока, система устанавливает регистр указателя стека на конец верхней страницы региона стека (адрес, очень близкий к 0x08100000). Это та страница, с которой поток начнет использовать свой стек. Вторая страница сверху называется сторожевой (guard page).
По мере разрастания дерева вызовов (одновременного обращения ко все большему числу функций) потоку, естественно, требуется и больший объем стека.
Как только поток обращается к следующей странице (а она сторожевая), система уведомляется об этой попытке. Тогда система передает память еще одной странице, расположенной как раз за сторожевой. После чего флаг PAGE_GUARD, как эстафетная палочка, переходит от текущей сторожевой к той странице, которой только что передана память. Благодаря такому механизму объем памяти, занимаемой стеком, увеличивается только по необходимости. Если дерево вызовов у потока будет расти и дальше, регион стека будет выглядеть примерно так, как показано на рис. l6-2.
Допустим, стек потока практически заполнен (как па рис. l6-2) и регистр указателя стека указывает на адрес 0x08003004. Тогда, как только поток вызовет еще одну функцию, система, по идее, должна передать дополнительную физическую память. Но когда система передает! память странице по адресу 0x08001000, она делает это уже по-другому. Регион стека теперь выглядит, как на рис l6-3.
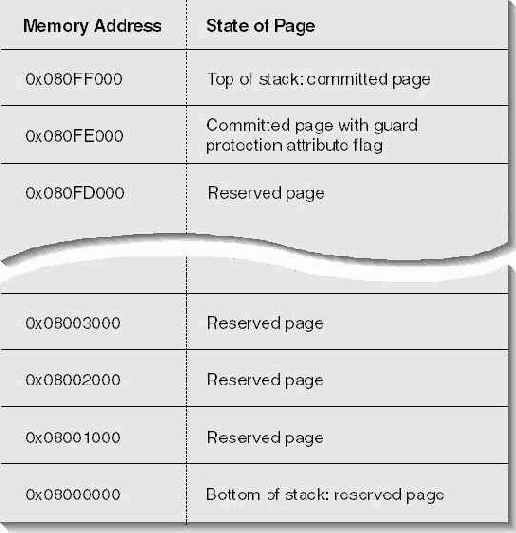
Рис. 16-1. Так выглядит регион стека потока сразу после его создания
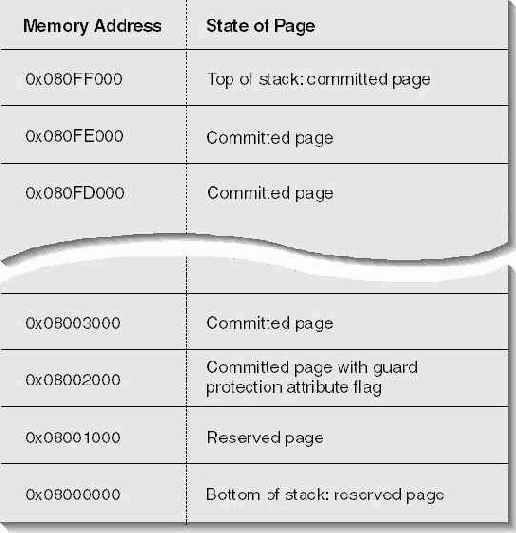
Рис. 16-2. Почти заполненный регион стека потока
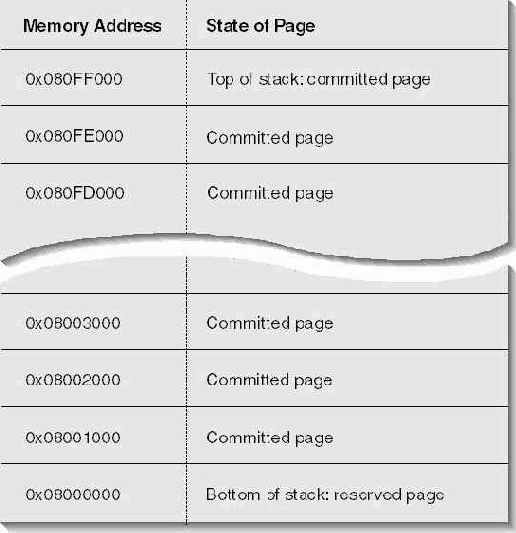
Рис. 16-3. Целиком заполненный регион стека потока
Как и можно было предполагать, флаг PAGE_GUARD со страницы по адресу 0x08002000 удаляется, а странице по адресу 0x08001000 передается физическая память. Но этой странице не присваивается флаг PAGE_GUARD. Это значит, что региону адресного пространства, зарезервированному под стек потока, теперь передана вся физическая память, которая могла быть ему передана. Самая нижняя страница остается зарезервированной, физическая память ей никогда не передается. Чуть позже я поясню, зачем это сделано.
Передавая физическую память странице по адресу 0x08001000, система выполняет еще одну операцию генерирует исключение EXCEPTION_STACK_OVERFLOW (в файле WinNT.h оно определено как 0xC00000FD). При использовании структурной обработки исключений (SEH). Ваша программа получит уведомление об этой ситуации и сможет корректно обработать ее. Подробнее о SEH см. главы 23, 24 и 25, а так же листинг программы Summation, приведенный в конце этой главы.
Если поток продолжит использовать стек даже после исключения, связанного с переполнением стека, будет задействована вся память на странице по адресу 0x08001000, и поток попытается получить доступ к странице по адресу 0x08000000. Поскольку эта страница лишь зарезервирована (но не передана), возникнет исключение — нарушение доступа. Если это произойдет в момент обращения потока к стеку, Вас ждут крупные неприятности. Система возьмет управление на себя и завершит не только данный поток, но и весь процесс И даже не сообщит об этом пользователю; процесс просто исчезнет!
Теперь объясню, почему нижняя страница стека всегда остается зарезервированной. Это позволяет защищать другие данные процесса от случайной перезаписи. Видите ли, по адресу 0x07FFF000 (па 1 страницу ниже, чем 0x08000000) может быть передана физическая память для другого региона адресного пространства. Если бы странице по адресу 0x08000000 была передана физическая память, система не сумела бы перехватить попытку потока расширить стек за прелелы зарезервированного региона. А если бы стек расползся за пределы этого региона, поток мог бы перезаписать другие даипые в адресном пространстве своего процесса — такого *жучка" выловить очень сложно.
Проецируемые в память файлы
ГЛАВА 17 Проецируемые в память файлы
Операции с файлами — это то, что рапо или поздно приходится делать практичес ки во всех программах, и всегда это вызывает массу проблем. Должно ли приложение просто открыть файл, считать и закрыть его, или открыть, считать фрагмент в буфер и перезаписать его в другую часть файла? В Windows многие из этих проблем реша ются очень изящно — с помощью проецируемых в память файлов (memory-mapped files)
Как и виртуальная память, проецируемые файлы позволяют резервировать реги он адресного пространства и передавать ему физическую память. Различие между этими механизмами состоит в том, что в последнем случае физическая память не выделяется из страничного файла, а берется из файла, уже находящегося на диске. Как только файл спроецирован в память, к нему можно обращаться так, будто он цели ком в нее загружен.
Проецируемые файлы применяются для:
загрузки и выполнения EXE- и DLL-файлов Это позволяет существенно эконо мить как на размере страничного файла, так и на времени, необходимом для подготовки приложения к выполнению,
доступа к файлу данных, размещенному на диске Это позволяет обойтись без операций файлового ввода-вывода и буферизации его содержимого,
разделения данных между несколькими процессами, выполняемыми па одной машине (В Windows есть и другие методы для совместного доступа разных процессов к одним данным — но все они так или иначе реализованы на осно ве проецируемых в память файлов.)
Эти области применения проецируемых файлов мы и рассмотрим в данной главе.
Динамически распределяемая память
ГЛАВА 18 Динамически распределяемая память
Третий, и последний, мехянизм управления памятью — динамически распределяемые области памяти, или кучи (heaps). Они весьма удобны при создании множества не больших блоков данных. Например, связанными списками и деревьями проще манипулировать, используя именно кучи, а не виртуальную память (глава 15) или файлы, проецируемые в память (глава 17). Преимущество динамически распределяемой памяти в том, что она позволяет Вам игнорировать гранулярность выделения памяти и размер страниц и сосредоточиться непосредственно на своей задаче. А недостаток — выделение и освобождение блоков памяти проходит медленнее, чсм при использовании других механизмов, и, кроме того, Вы теряете прямой контроль над передачей физической памяти и ее возвратом системе.
Куча — это регион зарезервированного адресного пространства. Первоначально большей его части физическая память не передается. По мере того, как программа занимает эту область под данные, специальный диспетчер, управляющий кучами (heap manager), постранично передаст ей физическую память (из страничного файла). А при освобождении блоков в куче диспетчер возвращает системе соответствующие страницы физической памяти.
Microsoft не документирует правила, по которым диспетчер передает или отбирает физическую память. Эти правила различны в Windows 98 и Windows 2000. Могу сказать Вам лишь следующее; Windows. 98 больше озабочена эффективностью использования памяти и поэтому старается как можно быстрее отобрать у куч физическую память. Однако Windows 2000 нацелена главным образом на максимальное быстродействие, в связи с чем возвращает физическую память в страничный файл, только если страницы не используются в течение определенного времени. Microsoft постоянно проводит стрессовое тестирование своих операционных систем и прогоняет разные сценарии, чтобы определить, какие правила в большинстве случаев работают лучше. Их приходится менять по мере появления как нового программного обеспечения, так и оборудования. Если эти правила важны Вашим программам, использовать динамически распределяемую память пе стоит — работайте с функциями виртуальной памяти (т.e. VirtualAlloc и VirtualFree), и тогда Вы сможете сами контролировать эти правила.
DLL: основы
Часть IV: Динамически подключаемые библиотеки
Глава 19 - DLL: основы
Динамически подключаемые библиотеки (dynamic-link libraries, DLL) — краеугольный камень операционной системы Windows, начиная с самой первой ec версии. В DLL содержатся все функции Windows API. Три самые важные DLL: Kernel32.dll (управление памятью, процессами и потоками), User32.dll (поддержка пользовательского интерфейса, в том числе функции, связанные с созданием окон и передачей сообщений) и GDI32.dll (графика и вывод текста).
В Windows есть и другие DLL, функции которых предназначены для более специализированных задач. Например, в AdvAPI32.dll содержатся функции для защиты объектов, работы с реестром и регистрации событий, в ComDlg32.dll ~ стандартные диалоговые окна (вроде File Open и File Save), a ComCrl32 dll поддерживает стандартные элементы управления.
В этой главе я расскажу, как создавать DLL-модули в Ваших приложениях. Вот лишь некоторые из причин, по которым нужно применять DLL:
Расширение функциональности приложения. DLL можно загружать в адресное пространство процесса динамически, что позволяет приложению, определив, какие действия от него требуются, подгружать нужный код. Поэтому одна компания, создав какое-то приложение, может предусмотреть расширение его функциональности за счет DLL от других компаний. Возможность использования разных языков программирования. У Вас есть выбор, на каком языке писать ту или иную часть приложения. Так, пользовательский интерфейс приложения Вы скорее всего будете создавать на Microsoft Visual Basic, но прикладную логику лучше всего реализовать на С++. Программа на Visual Basic может загружать DLL, написанные на С++, Коболе, Фортране и др. Более простое управление проектом. Если в процессе разработки программного продукта отдельные его модули создаются разными группами, то при использовании DLL таким проектом управлять гораздо проще. Однако конечная версия приложения должна включать как можно меньше файлов (Знал я одну компанию, которая поставляла свой продукт с сотней DLL.
Их приложение запускалось ужасающе долго — перед началом работы ему приходилось открывать сотню файлов на диске.) Экономия памяти. Если одну и ту же DLL использует несколько приложений, в оперативной памяти может храниться только один ее экземпляр, доступный этим приложениям. Пример — DLL-версия библиотеки С/С++. Ею пользуются многие приложения. Если всех их скомпоновать со статически подключаемой версией этой библиотеки, то код таких функций, как sprintf, strcpy, malloc и др., будет многократно дублироваться в памяти. Но ссли они компонуются с DLL-версией библиотеки С/С++, в памяти будет присутствовать лишь одна копия кода этих функций, что позволит гораздо эффективнее использовать оперативную память. Разделение ресурсов. DLL могут содержать такие ресурсы, как шаблоны диалоговых окон, строки, значки и битовые карты (растровые изображения). Эти ресурсы доступны любым программам. Упрощение локализации. DLL нередко применяются для локализации приложений. Например, приложение, содержащее только код без всяких компонентов пользовательского интерфейса, может загружать DLL с компонентами локализованного интерфейса. Решение проблем, связанных с особенностями различных платформ. В разных версиях Windows содержатся разные наборы функций. Зачастую разработчикам нужны новые функции, существующие в той версии системы, которой они пользуются. Если Ваша версия Windows не поддерживает эти функции, Вам не удастся запустить такое приложение: загрузчик попросту откажется его запускать. Но если эти функции будут находиться в отдельной DLL, Вы загрузите программу даже в более ранних версиях Windows, хотя воспользоваться ими Вы все равно не сможете. Реализация специфических возможностей. Определенная функциональность в Windows доступна только при использовании DLL Например, отдельные виды ловушек (устанавливаемых вызовом SetWindowsHookEx и SetWinEventHook можно задействовать при том условии, что функция уведомления ловушки размещена в DLL. Кроме того, расширение функциональности оболочки Windows возможно лишь за счет создания СОМ-объектов, существование которых допустимо только в DLL.Это же относится и к загружаемым Web-браузером ActiveX-элементам, позволяющим создавать Web-страницы с более богатой функциональностью.
ГЛАВA 20 DLL: более сложные методы программирования
Г Л А В A 20 DLL: более сложные методы программирования
О предыдущей главе мы говорили в основном о неявном связывании, поскольку это самый популярный метод Представленной там информации вполне достаточно для создания большинства приложений. Однако DLL открывают нам гораздо больше возможностей, и в этой главе Вас ждет целый "букет" новых методов, относящихся к программированию DLL. Во многих приложениях эти методы скорее всего не понадобятся, тем не менее они очень полезны, и познакомиться с ними стоит Я бы посоветовал, как минимум, прочесть разделы "Модификация базовых адресов модулей" и "Связывание модулей", подходы, изложенные в них, помогут существенно повысить быстродействие всей системы.
Локальная память потока
Глава 21 - Локальная память потока
Когда данные удобно связывать с экземпляром какого-либо объекта, например, чтобы сопоставить какие-то дополнительные данные с окном, применяют функции SetWindowWord и SetWindowLong. Локальная память потока (thread-local storage, TLS) позволяет связать данные и с определенным потоком (скажем, сопоставить с ним время его создания), а по завершении этого потока вычислить время его жизни.
TLS также используется в библиотеке С/С++. Но эту библиотеку разработали задолго до появления многопоточных приложений, и большая часть содержащихся в ней функций рассчитана на однопоточные программы. Наглядный пример — функция strtok. При первом вызове она получает адрес строки и зяпоминаст сго в собственной статической переменной. Когда при следующих вызовах strtok Вы передаете ей NULL, она оперирует с адресом, записанным в своей переменной.
В многопоточной среде вероятна такая ситуация; один поток вызывает strtok, и, не успел он вызвать ёё повторно, как к ней уже обращается другой. Тогда второй поток заставит функцию занести в статическую переменную новый адрес, неизвестный первому. И в дальнейшем первый поток, вызывая strtok, будет использовать строку, принадлежащую второму. Вот Вам и "жучок", найти который очень трудно.
Чтобы устранить эту проблему, в библиотеке С/С++ теперь применяется механизм локальной памяти потока: за каждым потоком закрепляется свой строковый указатель, зарезервированный для strtok. Аналогичный механизм действует и для других библиотечных функций, в том числе asctime и gmtime.
Локальная память потока может быть той соломинкой, за которую придется ухватиться, если Ваша программа интенсивно использует глобальные или статические переменные. К счастью, сейчас наметилась тенденция отхода от применения таких переменных и перехода к автоматическим (размещаемым в стеке) переменным и передаче данных через параметры функций. И правильно, ведь расположенные в стеке переменные всегда связаны только с конкретным потоком.
Стандартная библиотека С существует уже долгие годы — это и хорошо, и плохо. Ее переделывали под многие компиляторы, и ни один из них без неё не стоил бы ломаного гроша. Программисты пользовались и будут пользоваться ею, а значит, прототипы и поведение функций вроде strtok останутся прежними, Но если бы эту библиотеку взялись перерабатывать сегодня, ее построили бы с учетом многопоточности и уж точно не стали бы применять глобальные и статические переменные.
В своих программах я стараюсь избегать глобальных переменных. Если же Вы используете глобальные и статические переменные, советую проанализировать каждую из них и подумать, нельзя ли заменить её переменной, размещаемой в стеке. Усилия окупятся сторицей, когда Вы решите создать в программе дополнительные потоки; впрочем, и однопоточное приложение лишь выиграет от этого.
Хотя два вида TLS-памяти, рассматриваемые в этой главе, применимы как в приложениях, так и в DLL, они все же полезнее при разработке DLL, поскольку именно в этом случае Вам не известна структура программы, с которой они будут связаны. Если же Вы пишете приложение, то обычно знаете, сколько потоков оно создаст для него. Поэтому здесь еще можно как-то вывернуться. Но разработчик DLL ничего этого не знает. Чтобы помочь ему, и был создан механизм локальной памяти потока. Однако сведения, изложенные в этой главе, пригодятся и разработчику приложений.
Внедрение DLL и перехват API-вызовов
ГЛАВА 22 Внедрение DLL и перехват API-вызовов
О среде Windows каждый процесс получает свое адресное пространство. Указатели, используемые Вами для ссылки на определенные участки памяти, — это адреса в адресном пространстве Вашего процесса, и в нем нельзя создать указатель, ссылающийся на память, принадлежащую другому процессу Так, если в Вашей программе есть "жучок", из-за которого происходит запись по случайному адресу, он не разрушит содержимое памяти, отведенной другим процессам.
WINDOWS 98
В Windows 98 процессы фактически совместно используют 2 Гб адресного пространства (от 0x80000000 до 0xFFFFFFFF). На этот регион отображаются только системные компоненты и файлы, проецируемые в память (подробнее на эту тему см. главы 1 3, 14 и 17)
Раздельные адресные пространства очень выгодны и разработчикам, и пользователям. Первым важно, что Windows перехватывает обращения к памяти по случайным адресам, вторым — что операционная система более устойчива и сбой одного приложения не приведет к краху другого или самой системы. Но, конечно, за надежность приходится платить: написать программу, способную взаимодействовать с другими программами или манипулировать другими процессами, теперь гораздо сложнее.
Вот ситуации, в которых требуется прорыв за границы процессов и доступ к адресному пространству другого процесса:
создание подкласса окна, порожденного другим процессом; получение информации для отладки (например, чтобы определить, какие DLL используются другим процессом); установка ловушек (hooks) в других процессах.
В этой главе я расскажу о нескольких механизмах, позволяющих внедрить (inject) какую-либо DLL в адресное пространство другого процесса. Ваш код, попав в чужое адресное пространство, можетустроить в нем настоящий хаос, поэтомухорошенько взвесьте, так ли Вам необходимо это внедрение.
Обработчики завершения
Часть V: Структурная обработка исключений
Глава 23 - Обработчики завершения
Закроем глаза и помечтаем, какие бы программы мы писали, если бы сбои в них были невозможны! Представляете, памяти навалом, неверных указателей никто не переда ет, нужные файлы всегда на месте Не программирование, а праздник, да? А код про грамм? Насколько он стал бы проще и понятнее! Без всех этих if и goto,
И если Вы давно мечтали о такой среде программирования, Вы сразу жс оцените структурную обработку исключений (structured exception handling, SEH). Преимуще ство SEH в том, что при написании кода можно сосредоточиться на решении своей задачи Если при выполнении программы возникнут неприятности, система сама обнаружит их и сообщит Вам.
Хотя полностью игнорировать ошибки в программе при использовании SEH нельзя, она всс жс позволяет отделить основную работу от рутинной обработки оши бок, к которой можно вернуться позже.
Главное, почему Microsoft ввела в Windows поддержку SEH, было ее стремление упростить разработку операционной системы и повысить ее надежность. А нам SЕН поможет сделать надежнее наши программы
Основная нагрузка по поддержке SEH ложится на компилятор, а не на операци онную систему. Он генерирует специальный код на входах и выходах блоков исклю чений (exception blorks), создает таблицы вспомогательных структур данных для поддержки SEH и предоставляет функции обратного вызова, к которым система мог ла бы обращаться для прохода по блокам исключений Компилятор отвечает и за формирование стековых фреймов (stack frames) и другой внутренней информации, используемой операционной системой. Добавить поддержку SEH в компилятор — задача не из легких, поэтому не удивляйтесь, когда увидите, что разные поставщики no-разному реализуют SEH в своих компиляторах К счастью, на детали реализации можно не обращать внимания, а просто задействовать возможности компилятора в поддержке SEH
Различия в реализации SEH разными компиляторами могли бы затруднить описа ние конкретных примеров использования SEH.
Но большинство поставщиков компи ляторов придерживается синтаксиса, рекомендованного Microsoft Синтаксис и клю чевые слова в моих примерах могут отличаться от применяемых в других компиля торах, по основные концепции SEH везде одинаковы В этой главе я использую син таксис компиляюра Microsoft Visual C++
NOTE:
Не путайте SEH с обработкой исключении в С++, которая представляет собой еще одну форму обработки исключений, построенную на применении ключе вых слов языка С++ catch и throw При этом Microsoft Visual C++ использует пре имущества поддержки SEH, уже обеспеченной компилятором и операционны ми сиоемдми Windows.
SEH предоставляет две основные возможности, обработку завершения (termination handling) и обработку исключений (exception handling). B этой главе мы рассмотрим обработку завершения.
Обработчик завершения гарантирует, что блок кода (собственно обработчик) будет выполнен независимо от того, как происходит выход из другого блока кода — защищенного участка программы. Синтаксис обработчика завершения при работе с компилятором Microsoft Visual C++ выглядит так:
__try
{
// защищенный блок
}
_finally
{
// обработчик завершения
}
Ключевые слова _try и __flnally обозначают два блока обработчика завершения, В предыдущем фрагменте кода совместные действия операционной системы и ком пилятора гарантируют, что код блока finаllу обработчика завершения будет выполнен независимо от того, как произойдет выход из защищенного блока. И неважно, разме стите Вы в защищенном блоке операторы return, goto или даже longjump — обработ чик завершения все равно будет вызван. Далее я покажу Вам несколько примеров ис пользования обработчиков завершения
Фильтры и обработчики исключений
Глава 24 - Фильтры и обработчики исключений
Исключение — это событие, которого Вы не ожидали. В хорошо написанной про грамме не предполагается попыток обращения по неверному адресу или деления на нуль И все же такие ошибки случаются За псрехват попыток обращения по неверно му адресу и деления на нуль отвечает центральный процессор, возбуждающий исклю чения в ответ на эти ошибки. Исключение, возбужденное процессором, называется аппаратным (hardware exception) Далее мы увидим, что операционная система и прикладные программы способны возбуждать собственные исключения — программ ные (software exceptions).
При возникновении аппаратного или программного исключения операционная система дает Вашему приложению шанс определить его тип и самостоятельно обра ботать Синтаксис обработчика исключений таков:
__try {
// защищенный блок
}
__except (фильтр исключений) {
// обработчик исключений
}
Обратите внимание на ключевое слово _ except За блоком try всегда должен сле довать либо блок finaly, либо блок except. Для данного блока try нельзя указать одно временно и блок finaly, и блок except: к тому же за try не может следовать несколько блок finaly или except Однако try-finally можно вложить в try-except, и наоборот.
Необработанные исключения и исключения С++
Глава 25 - Необработанные исключения и исключения С++
В предыдущей главе мы обсудили, что происходит, когда фильтр возвращает значе ние EXCEPTION_CONTШNUE_SEARCH. Оно заставляет систему искать дополнительные фильтры исключений, продвшаясь вверх по дереву вызовов. А что будет, если все фильтры вернут EXCEPTION_CONTINUE_SEARCH? Тогда мы получим необработанное исключение (unhandled exception).
Как Вы помните из главы 6, выполнение потока начинается с функции BaseProcess Start или BaseThreadStart в Kernel32.dll Единственная разница между этими функция ми в том, что первая используется для запуска первичного потока процесса, а вто рая — для запуска остальных потоков процесса.
VOID BaseProcessStart(PPROCESS_START_ROUTINE pfnStartAddr)
{
__try
{
ExitThread({pfnStartAddr)());
}
_except (UnhandledExceptionFilter(GetExceptionInformation()))
{
ExitProcess(GetExecptionCode());
}
// Примечание, сюда мы никогда не попадем
}
VOID BaseThreadStart(PTHREAD_START_ROUTINE pfnStartAddr, PVOID pvParam)
{
__try
{
ExitThread((pfnStartAddr)(pvParam));
}
_except (UnhandledExceptionFilter(GetExceptionInformation())}
{
ExitProcess(GetExceptionCode());
}
// Примечание, сюда мы никогда не попадем
}
Обратите внимание, что обе функции содержат SEH-фрейм: поток запускается из блока try. Если поток возбудит исключение, в ответ на которое все Ваши фильтры вер нут EXCEPTION_CONTINUE_SEARCH, будет вызвана особая функция фильтра, предос тавляемая операционной системой:
LONG UnhandledExceptionFilter(PEXCEPTION_POINTERS pExceptionInfo);
Она выводит окно, указывающее на то, что поток в процессе вызвал необрабаты ваемое им исключение, и предлагает либо закрыть процесс, либо начать его отладку. В Windows 98 это окно выглядит следующим образом.
А в Windows 2000 оно имеет другой вид.
В Windows 2000 первая часть текста в этом окне подсказывает тип исключения и адрес вызвавшей его инструкции в адресном пространстве процесса. У меня окно появилось из-за нарушения доступа к памяти, поэтому система сообщила адрес, по которому произошла ошибка, и тип доступа к памяти — чтение UnhandledException Filter получает эту информацию из элемента Exceptionlnformation структуры EXCEP TION_RECORD, инициализированной для этого исключения.
В данном окне можно сделать одно из двух. Во-первых, щелкнуть кнопку OK, и тогда UnhandledExceptionFilter вернет EXCEPTION_EXECUTE_HANDLER. Это приведет к глобальной раскрутке и соответственно к выполнению всех имеющихся блоков finally, а затем и к выполнению обработчика в BaseProcessStart или BaseThreadStart. Оба обработчика вызывают ExitProcess, поэтому-то Ваш процесс и закрывается Причем кодом завершения процесса становится код исключения. Кроме того, процесс закры вается его жe потоком, а не операционной системой!А это означает, что Вы можете вмешаться в ход завершения своего процесса.
Во-вторых, Вы можете щелкнуть кнопку Cancel (сбываются самые смелые мечты программистов). В этом случае UnbandledExceptionFilter попытается запустить отлад чик и подключить его к процессу Тогда Вы сможете просматривать состояние гло бальных, локальных и статических переменных, расставлять точки прерывания, пе резапускать процесс и вообще делать все, что делается при отладке процесса.
Но самое главное, что сбой в программе можно исследовать в момент его возник новения. В большинстве других операционных систем для отладки процесса сначала запускается отладчик. При генерации исключения в процессе, выполняемом в любой из таких систем, этот процесс надо завершить, запустить отладчик и прогнать про грамму уже под отладчиком Проблема, правда, в том, что ошибку надо сначала вос произвести; лишь потом можно попытаться ее исправить. А кто знает, какие значе ния были у переменных, когда Вы впервые заметили ошибку? Поэтому найти ее та
ким способом гораздо труднее Возможность динамически подключать отладчик к уже запущенному процессу — одно из лучших качеств Windows.
WINDOWS 2000
В этой книге рассматривается разработка приложений, работающих только в пользовательском режиме. Но, наверное, Вас интересует, что происходит, ког да необработанное исключение возникает в потоке, выполняемом в режиме ядра. Так вот, исключения в режиме ядра обрабатываются так же, как и исклю чения пользовательского режима.Если низкоуровневая функция для работы с виртуальной памятью возбуждает исключение, система проверяет, есть ли фильтр режима ядра, готовый обработать это исключение Если такого филь тра нет, оно остается необработанным В этом случае необработанное исклю чение окажется в операционной системе или (что вероятнее) в драйвере уст ройства, а не в приложении А это уже серьезно!
Так как дальнейшая работа системы после необработанного исключения в режиме ядра небезопасна, Windows не вызывает UnhandledExceptionFilter. Вме сто этого появляется так называемый "синий экран смерти" экран переклю чается в текстовый режим, окрашивается в синий фон, выводится информа ция о модуле, вызвавшем необработанное исключение, и система останавли вается Вам следует записать эту информацию и отправить ее в Microsoft или поставщику драйвера устройства. Прежде чем продолжить работу, придется перезагрузить машину; при этом все несохраненные данные теряются.
Оконные сообщения
Часть VI: Операции с окнами
Глава 26 - Оконные сообщения
В этой главе я расскажу, как работает подсистема передачи сообщений в Windows применительно к приложениям с графическим пользовательским интерфейсом Раз рабатывая подсистему управления окнами в Windows 2000 и Windows 98, Microsoft преследовала две основные цели
обратная совместимость с 16-разрядной Windows, облегчающая перенос суще ствующих 16-разрядных приложении,
отказоустойчивость подсистемы управления окнами, чтобы ни один поток не мог нарушить работу других потоков в системе
К сожалению, эти цели прямо противоречат друг другу В 16-разрядной Windows передача сообщения в окно всегда осуществляется синхронно отправитель не может продолжить работу, пока окно не обработает полученное сообщение Обычно так и нужно Но, если на обработку сообщения потребуется длительное время или если окно "зависнет", выполнение отправителя просто прекратится А значит, такая операцион ная система не вправе претендовать на устойчивость к сбоям
Это противоречие было серьезным вызовом для команды разработчиков из Micro soft В итоге было выбрано компромиссное решение, отвечающее двум вышеупомя нутым целям Помните о них, читая эту главу, и Вы поймете, почему Microsoft сделала именно такой выбор
Для начала рассмотрим некоторые базовые принципы Один процесс в Windows может создать до 10 000 User-объектов различных типов — значков, курсоров, окон ных классов, меню таблиц клавиш-акселераюров и т д Когда поток из какого-либо процесса вызывает функцию, создающую один из этих объектов последний перехо дит во владение процесса Поэтому, если процесс завершается, не уничтожив данный объект явным образом, операционная система делает этo за него Однако два User объектa (окна и ловушки) принадлежат только создавшему их потоку И вновь, если поток создает окно или устанавливает ловушку а потом завершается, операционная система автоматически уничтожает окно или удаляет ловушку
Этот принцип принадлежности окон и ловушек создавшему их потоку оказывает существенное влияние на механизм функционирования окон поток создавший окно, должен обрабатывать все его сообщения Поясню данный принцип на примере До пустим, поток создал окно, а затем прекратил работу Тогда его окно уже не получит сообщение WM_DESTROY или WM_NCDESTROY, потому что поток уже завершился и обрабатывать сообщения, посылаемые этому окну, больше некому
Это также означает, чю каждому потоку, создавшему хотя бы одно окно, система выделяет очередь сообщений, используемую для их диспетчеризации Чтобы окно в конечном счете получило эти сообщения поток должен иметь собственный цикл выборки сообщений В этой главе мы детально рассмотрим, что представляют собой
очереди сообщений потоков. В частности, я расскажу, как сообщения помещаются в эту очередь и как они извлекаются из нее, а потом обрабатываются.
Модель аппаратного ввода и локальное состояние ввода
Глава 27 - Модель аппаратного ввода и локальное состояние ввода
В этой главе мы рассмотрим модель аппаратного ввода. В частности, я расскажу, как события от клавиатуры и мыши попадают в систему и пересылаются соответствую щим оконным процедурам. Создавая модель ввода, Microsoft стремилась главным об разом к тому, чтобы ни один поток не мог нарушить работу других потоков. Вот при мер из 1б-разрядной Windows' задача (так в этой системе назывались выполняемые программы), зависшая в бесконечном цикле, приводила к тому, что зависали и осталь ные задачи — их дальнейшее выполнение становилось невозможным. Пользователю ничего не оставалось, как только перезагрузить компьютер А все потому, что опера ционная система слишком много разрешала отдельно взятой задаче. Отказоустойчи вые операционные системы вроде Windows 2000 и Windows 98 не дают зависшему потоку блокировать другим потокам прием аппаратного ввода
Глобальная раскрутка
Когда фильтр исключений возвращает EXCEPTION_EXECUTE_HANDLER, системе при ходится проводить глобальную раскрутку Она приводит к продолжению обработки всех незавершенных блоков try-finally, выполнение которых началось вслед за блоком try-except, обрабатывающим данное исключение. Блок-схема на рис. 24-2 поясняет, как система осуществляет глобальную раскрутку Посматривайте на эту схему, когда бу дете читать мои пояснения к следующему примеру
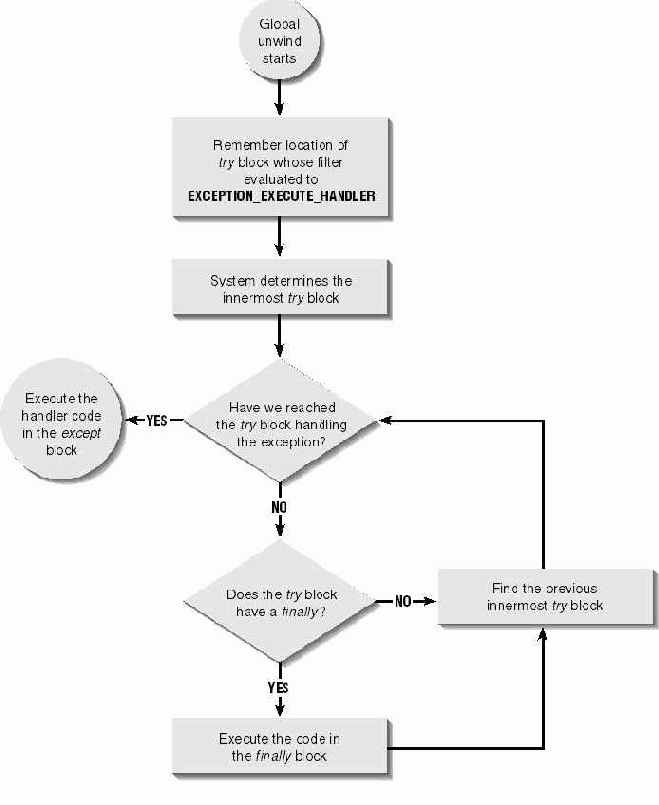
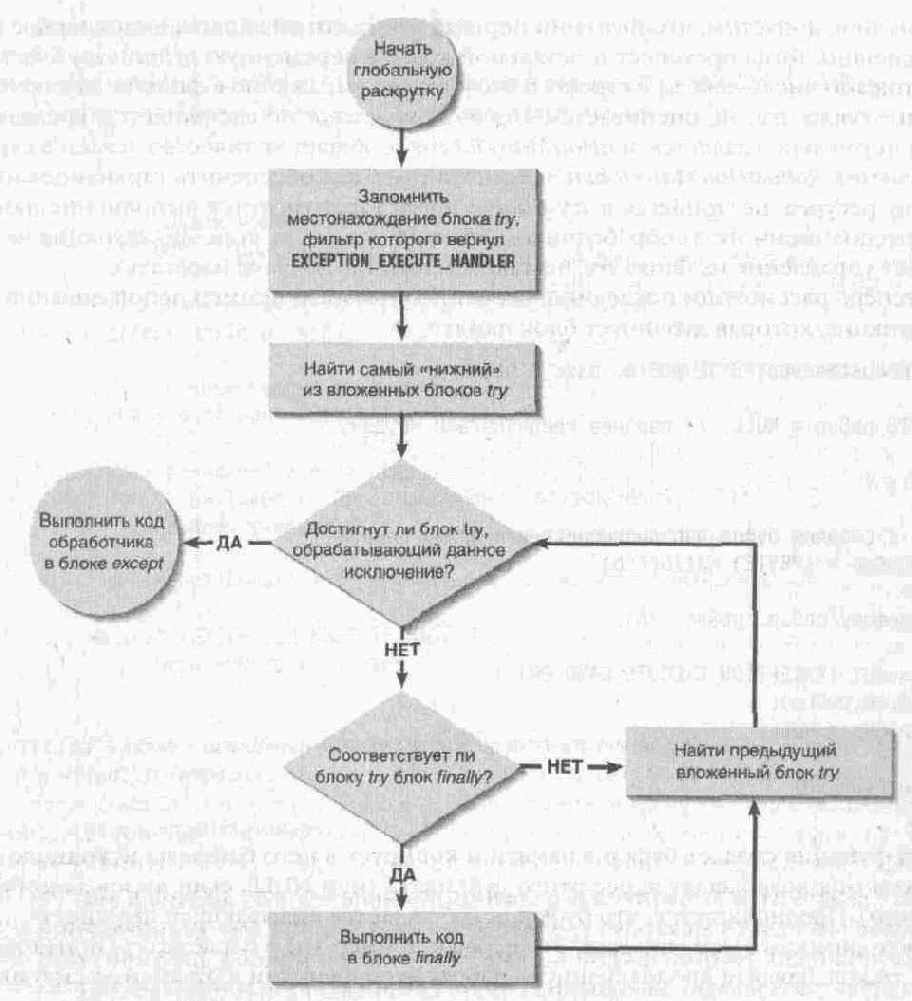
Рис. 24-2. Так система проводит глобальную раскрутку
void FuncOSTimpy1()
{
// 1 Что-то делаем здесь
...
__try
{
// 2 Вызываем другую функцию
FuncORen1();
// этот код никогда не выполняется
}
__except (/* 6 Проверяем фильтр исключений */ EXCEPTION_EXECUTE,HANDLER)
{
// 8 После раскрутки выполняется атот обработчик
MessageBox(....);
}
// 9 Исключение обработано - продолжаем выполнение ...
}
void FuncORen1()
{
DWORD dwTemp = 0;
// 3. Что-то делаем здесь
...
__try
{
// 4. Запрашиваем разрешение на доступ к защищенным данным
WaitForSingleObject(g_nSem, INFINITE);
// 5. Изменяем данные, и здесь генерируется исключение
g_dwProtectedData = 5 / dwTemp;
}
__finally
{
// 7. Происходит глобальная раскрутка, так как
// фильтр возвращает FXCFPTTON_EXECUTE_HANDLER
// Даем и другим попользоваться защищенными данными
ReleaseSemaphore(g_hScm, 1, NULL);
}
// сюда мы никогда не попадем
...
}
FuncOStimpyl и FuncORen1 иллюстрируют самые запутанные аспекты структурной обработки исключений. Номера в начале комментариев показывают порядок выпол нения, в котором сходу не разберешься, но возьмемся за руки и пойдем вместе.
FuncOStimpy1 начинает выполнение со входа в свой блок try и вызова FuncORen1. Последняя тоже начинает со входа в свой блок try и ждет освобождения семафора. Завладев им, она пытается изменить значение глобальной переменной g_dwProtected Data. Деление на нуль возбуждает исключение. Система, перехватив управление, ищет блок try, которому соответствует блок except. Поскольку блоку try функции FuncORenl соответствует 6лок finally, система продолжает поиск и находит блок try в FuncOStim py1, которому как раз и соответствует блок except.
Тогда система проверяет значение фильтра исключений в блоке except функции FuncOStimpy1. Обнаружив, что оно — EXCEPTION_EXECUTE_HANDLER, система начи нает глобальную раскрутку с блока finally в функции FuncORen1. Заметьте: раскрутка происходит до выполнения кода из блока except в FuncOStimpy1. Осуществляя глобаль ную раскрутку, система возвращается к последнему незавершенному блоку try и ищет теперь блоки try, которым соответствуют блоки finally. В нашем случае блок finally находится в функции FuncORen1.
Мощь SEH по-настоящему проявляется, когда система выполняет код finally в Func ORen1. Из-за его выполнения семафор освобождается, и поэтомудругой поток полу чает возможность продолжить работу. Если бы вызов ReleaseSemapbore в блоке finally отсутствовал, семафор никогда бы не освободился.
Завершив выполнение блока finally, система ищет другие незавершенные блоки finally. В нашем примере таких нет. Дойдя до блока except, обрабатывающего исклю чение, система прекращает восходящий проход по цепочке блоков. В этой точке гло бальная раскрутка завершается, и система может выполнить код в блоке except,
Вот тук и работает структурная обработка исключений. Вообще-то, SEH — штука весьма трудная для понимания: в выполнение Вашего кода вмешивается операцион ная система Код больше не выполняется последовательно, сверху вниз; система уста навливает свой порядок — сложный, но все же предсказуемый. Поэтому, следуя блок схемам на рис, 24-1 и 24-2, Вы сможете уверенно применять SEH.
Чтобы лучше разобраться в порядке выполнения кода, посмотрим на происходя щее под другим углом зрения. Возвращая EXCEPTION_EXECUTE_HANDLER, фильтр сообщает операционной системе, что регистр указателя команд данного потока дол жен быть установлен на код внутри блока except Однако зтот регистр указывал на код внутри блока try функции FuncORen1. А из главы 23 Вы должны помнить, что всякий раз, когда поток выходит из блока try, соответствующего блок finally, обязательно вы полняется код в этом блоке finally. Глобальная раскрутка как раз и является тем меха низмом, который гарантирует соблюдение этого правила при любом исключении.
Худшее, что можно сделать
Если бы синхронизирующих объектов не было, а операционная система не умела отслеживать особые собьпия, потоку пришлось бы самостоятельно синхронизировать себя с ними, применяя метод, который я как раз и собираюсь продемонстрировать Но поскольку в операционную систему встроена поддержка синхронизации объек тов, никогда не применяйте этот метод.
Суть его в том, что поток синхронизирует себя с завершением какой-либо задачи в другом потоке, постоянно просматривая значение переменной, доступной обоим потокам Возьмем пример:
volatile BOOL q_fFinishedCalculation = FALSE;
int WINAPI WinMain( )
{
CreateThread( , RecalcFunc, );
... // ждем завершения пересчета
while (!g_fFinishedCalculation)
...
}
DWORD WINAPI RecalcFunc(PVOID pvParam)
{ // выполняем пересчет
g_fFinishedCalculation = TRUE;
return(0);
}
Как видите, первичный поток (он исполняет функцию WinMain) при синхронизации по такому событию, как завершение функции RecalcFunc, никогда не впадает в спячку. Поэтому система по-прежнсму выделяет ему процессорное время за счет других потоков, занимающихся чем-то более полезным.
Другая проблема, связанная с подобным методом опроса, в том, что булева переменная g_fFinishedCalculation может не получить значения TRUE — например, если у первичного потока более высокий приоритет, чем у потока, выполняющего функцию RecalcFunc. В этом случае система никогда не предоставит процессорное время потоку RecalcFunc, а он никогда не выполнит оператор, присваивающий значение TRUE переменной g_fFinishedCalculation. Если бы мы не опрашивали поток, выполняющий функцию WinMain, а просто отправили в спячку, это позволило бы системе отдать его долю процессорного времени потокам с более низким приоритетом, в частности потоку RecalcFunc.
Вполне допускаю, что опрос иногда удобен. В конце концов, именно это и делается при спин-блокировке. Но есть два способа его реализации корректный и некорректный Общее правило таково- избегайте применения спин-блокировки и опроса. Вместо этого пользуйтесь функциями, которые переводят Ваш поток в состояние ожидания до освобождения нужного ему ресурса.
Как это правильно сделать, я объясню в следующем разделе.
Прежде всего позвольте обратить Ваше внимание на одну вещь: в начале приведенного выше фрагмента кода я использовал спецификатор volatile - без него работa моей программы просто немыслима. Он сообщает компилятору, что переменная может быть изменена извне приложения — операционной системой, аппаратным устройством или другим потоком. Точнее, спецификатор volatile заставляет компилятор исключить эту переменную из оптимизации и всегда перезагружать ее значение из памяти. Представьте, что компилятор сгенерировал следующий псевдокод для оператора while из предыдущего фрагмента кода:
MOV RegO, [g__fFinishedCalculation] ; копируем значение в регистр
Label TEST RegO, 0 ; равно ли оно нулю9
JMP RegO == 0, Label ; в регистре находится 0, повторяем цикл
... ;в регистре находится ненулевое значение
; (выходим из цикла)
Если бы я не определил булеву переменную как volatile, компилятор мог бы оптимизировать наш код на С именно так. При этом компилятор загружал бы ее значение в регистр процессора только раз, а потом сравнивал бы искомое значение с содержимым регистра. Конечно, такая оптимизация повышает быстродействие, поскольку позволяет избежать постоянного считывания значения из памяти, оптимизирующий компилятор скорее всего сгенерирует код именно так, как я показал. Но тогда наш поток войдет в бесконечный цикл и никогда не проснется. Кстати, если структура определена как volatile, таковыми становятся и все ее элементы, т e. при каждом обращении они считываются из памяти.
Вас, наверное, заинтересовало, а не следует ли объявить как volatile и мою переменную g_fResourcelnUse в примере со спин-блокировкой. Отвечаю: нет, потому что она передается Interlocked-функции по ссылке, а не по значению. Передача перемен ной по ссылке всегда заставляет функцию считывать ее значение из памяти, и оптимизатор никак не влияет на это.
И еще кое-что о таймерах
Таймеры часто применяются в коммуникационных протоколах. Например, ссли кли ент делает запрос серверу и тот не отвечает в течение определенного времени, кли ент считает, что сервер не доступен. Сегодня клиентские машины взаимодействуют, как правило, со множеством серверов одновременно. Если бы объект ядра "таймер" создавался для каждого запроса, производительность системы снизилась бы весьма заметно. В большинстве приложений можно создавать единственный объект-таймер и по мере необходимости просто изменять время его срабатывания.
Постоянное отслеживание параметров таймера и его перенастройка довольно утомительны, из-за чего реализованы лишь в немногих приложениях. Однако в чис ле новых функций для операций с пулами потоков (о них — в главе 11) появилась CreateTimerQueueTimer — она как раз и берет на себя всю эту рутинную работу. При смотритесь к ней, если в Вашей программе приходится создавать несколько объек тов-таймеров и управлять ими.
Конечно, очень мило, что таймеры поддерживают АРС-очереди, но большинство современных приложений использует не APC, а порты завершения ввода-вывода. Как то раз мне понадобилось, чтобы один из потоков в пуле (управляемом через порт завершения ввода-вывода) пробуждался по таймеру через определенные интервалы времени К сожалению, такую функциональность ожидаемые таймеры yе поддержи вают. Для решения этой задачи мнс пришлось создать отдельный поток, который все го-то и делал, что настраивал ожидаемый таймер и ждал его освобождения Когда таймер переходил в свободное состояние, этот поток вызывал PostQueuedComplction Status, передавая соответствующее уведомление потоку в пуле.
Любой, мало-мальски опытный Windows-программист непременно поинтересу ется различиями ожидаемых таймеров и таймеров User (настраиваемых через функ цию SetTimer). Так вот, главное отличие в том, что ожидаемые таймеры реализованы в ядре, а значит, не столь тяжеловесны, как таймеры User. Кроме того, это означает, что ожидаемые таймеры — объекты защищенные.
Таймеры User генерируют сообщения WM_TIMER, посылаемые тому потоку, кото рый вызвал SetTimer (в случае таймеров с обратной связью) или создал определенное
окно (в случае оконных таймеров). Таким образом, о срабатывании таймера User уве домляется только один поток А ожидаемый таймер позволяет ждять любому числу потоков, и, если это таймер со сбросом вручную, при его освобождении может про буждаться сразу несколько потоков.
Если в ответ на срабатывание таймера Вы собираетесь выполнять какие-то опе рации, связанные с пользовательским интерфейсом, то, по-видимому, будет легче структурировать код под таймеры User, поскольку применение ожидаемых таймеров требует от потоков ожидания не только сообщений, но и объектов ядра (Если у Вас есть желание переделать свой код, используйте функцию MsgWaitForMultipleObjects, которая как раз и рассчитана на такие ситуации.) Наконец, в случае ожидаемых тай меров Вы с большей вероятностью будете получать уведомления именно no истече нии заданного интервала. Как поясняется в главе 26, сообщения WM_TIMER всегда имеют наименьший приоритет и принимаются, только когда в очереди потока нет других сообщений Но ожидаемый таймср обрабатывястся так же, как и любой дру гой объект ядра, если он сработал, ждущий поток немедленно пробуждается
И еще о блоке finally
Пока нам с Вами удалось четко выделить только два сценария, которые приводят к выполнению блока finаllу:
• нормальная передача управления от блока try блоку finаllу;
• локальная раскрутка — преждевременный выход из блока try (из-за операто ров goto, longjump, continue, break, return и т. д.), вызывающий принудительную передачу управления блоку finаllу.
Третий сценарий — глобалъная раскрутка (global unwind) — протекает не столь выраженно. Вспомним Funcfurterl. Ее блок try содержал вызов функции Funcinator. При неверном доступе к памяти в Funcinator глобальная раскрутка приводила к вы полиению блока finаllу в Funcfurter1 Но подробнее о глобальной раскрутке мы пого ворим в следующей главе.
Выполнение кода в блоке finаllу всегда начинается в результате возникновения одной из этих трех ситуаций. Чтобы определить, какая из них вызвала выполнение блока finаllу, вызовите встраиваемую функцию AbnormalTermination
BOOL AbnormalTermination();
Еe можно вызвать только из блока finаllу; она возвращает булево значение, кото рое сообщает, был ли преждевременный выход из блока try, связанного с данным блоком finаllу. Иначе говоря, если управление естественным образом передано из try в ftnally, AbnormalTermination возвращает FALSE. А ссли выход был преждевременным — обычно либо из-за локальной раскрутки, вызванной оператором goto, return, break или continue, либо из-за глобальной раскрутки, вызванной нарушением доступа к памя ти, — то вызов AbnormalTermination дает TRUE Но, когда она возвращяет TRUE, разли чить, вызвано выполнение блока finаllу глобальной или локалыюй раскруткой, нельзя. Впрочем, это не проблема, так как Вы должны избегать кода, приводящего к локаль ной раскрутке
И в каких случаях потоки не создаются
До сих пор я пел одни дифирамбы многопоточным приложениям. Но, несмотря на все преимущества, у них есть и свои недостатки. Некоторые разработчики почему-то считают, будто любую проблему можно решить, разбив программу на отдельные потоки. Трудно совершить большую ошибку!
Потоки - вещь невероятно полезная, когда ими пользуются с умом. Увы, решая старые проблемы, можно создать себе новые. Допустим, Вы разрабатываете текстовый процессор и хотите выделить функциональный блок, отвечающий за распечатку, в отдельный поток. Идея вроде неплоха: пользователь, отправив документ на распечатку, может сразу вернуться к редактированию. Но задумайтесь вот над чем. значит, информация в документе может быть изменена при распечатке документа? Как видите, теперь перед Вами совершенно новая проблема, с которой прежде сталкиваться не приходилось. Тут-то и подумаешь, а стоит ли выделять печать в огдельный поток, зачем искать лишних приключений? Но давайте разрешим при распечатке редактирование любых документов, кроме того, который печатается в данный момент. Или так, скопируем документ во временный файл и отправим па печать именно его, а пользователь пусть редактирует оригинал в свое удовольствие. Когда распечатка временного файла закончится, мы его удалим — вот и все.
Еще одно узкое место, где неправильное применение потоков может привести к появлению проблем, — разработка пользовательского интерфейса в приложении. В подавляющем большинстве программ все компоненты пользовательского интерфейca (окна) обрабатываются одним и тем же потоком. И дочерние окна любого окна определенно должен создавать только один поток. Создание разных окон в разных потоках иногда имеет смысл, но такие случаи действительно редки.
Обычно в приложении существует один поток, отвечающий за поддержку пользовательского интерфейса, — он создает все окна и содержит цикл GetMessage. Любые другие потоки в процессе являются рабочими (т. e. отвечают за вычисления, ввод-вывод и другие операции) и не создают никаких окон, Поток пользовательского интерфейса, как правило, имеет более высокий приоритет, чем рабочие потоки, — это нужно для того, чтобы он всегда быстро реагировал на действия пользователя.
Несколько потоков пользовательского интерфейса в одном процессе можно обнаружить в таких приложениях, как Windows Explorer. Он создает отдельный поток для каждого окна папки. Это позволяет копировать файлы из одной папки в другую и попутно просматривать содержимое еще какой-то папки. Кроме того, если какая-то ошибка в Explorer приводит к краху одного из егo потоков, прочие потоки остаются работоспособны, и Вы можете пользоваться соответствующими окнами, пока не сделаете что-нибудь такое, из-за чего рухнут и они. (Подробнее о потоках и пользовательском интерфейсе см. главы 26 и 27.)
В общем, мораль этого вступления такова: многопоточность следует использовать разумно. Не создавайте несколько потоков только потому, что это возможно. Многие полезные и мощные программы по-прежнему строятся на основе одного первичного потока, принадлежащего процессу.
Именованные объекты
Второй способ, позволяющий нескольким процессам совместно использовать одни и те же объекты ядра, связан с именованием этих объектов. Именование допускают многие (но не все) объекты ядра. Например, следующие функции создают именованные объекты ядра.
HANDLE CreateMutex(
PSLCURITY_ATTRIBUTES psa,
BOOL bInitialOwner,
PCTSTR pszName);
HANDLE CreateEvent(
PSECURITY_ATTRIBUTES psa,
BOOL bManualReset,
BOOL bInitialState,
PCTSTR pszName);
HANDLE CreateSemaphore(
PSECURITY_ATTRIBUTES psa,
LONG lInitialCount,
LONG lMaximumCount,
PCTSTR pszNarne);
HANDLE CreateWaitableTimer(
PSLCURITY_ATTRIBUTES psa,
BOOL bManualReset,
PCTSTR pszName);
HANDLE CreateFileMapping(
HANDLE hFile,
PSECURITY_ATTRIBUTES psa,
DWORD flProtect,
DWORD dwMaximumSizeHigh,
DWORD dwMaximumSizeLow,
PCTSTR pszName);
HANDLE CreateJobObject(
PSECURITY_ATTRIBUTES psa,
PCTSTR pszName);
Последний параметр, pszName, у всех этих функций одинаков. Передавая в нем NULL, Вы создаете безымянный (анонимный) объект ядра. В этом случае Вы можете разделять объект между процессами либо через наследование (см. предыдущий раздел), либо с помощью DuplicateHandle (см. следующий раздел). А чтобы разделять объект по имени, Вы должны присвоить ему какое-нибудь имя. Тогда вместо NULL в параметре pszName нужно передать адрес строки с именем, завершаемой нулевым символом. Имя может быть длиной до MAX_PATH знаков (это значение определено как 260). К сожалению, Microsoft ничего не сообщает о правилах именования объектов ядра. Например, создавая объект с именем JeffObj, Вы никак не застрахованы от того, что в системе еще нет объекта ядра с таким именем. И что хуже, все эти объекты делят единое пространство имен. Из-за этого следующий вызов CreateSemaphore будет всегда возвращать NULL:
HANDLE hMutex = CreateMutex(NULL. FALSE, "JeffObj");
HANDLE hSem = CreateSemaphore(NULL, 1, 1, "JeffObj");
DWORD dwErrorCode = GetLastError();
После выполнения этого фрагмента значение dwErrorCode будет равно 6 (ERROR_INVALID_HANDLE).
Полученный код ошибки не слишком вразумителен, но другого не дано.
Теперь, когда Вы научились именовать объекты, рассмотрим, как разделять их между процессами по именам. Допустим, после запуска процесса А вызывается функция:
HANDLE hMutexPronessA = CreateMutex(NULL, FALSE, "JeffMutex");
Этот вызов заставляет систему создать новенький, как с иголочки, объект ядра "мьютекс" и присвоить ему имя JeffMutex. Заметьте, что описатель hMutexProcessA в процессе А не является наследуемым, — он и не должен быть таковым при простом именовании объектов.
Спустя какое-то время некий процесс порождает процесс В. Необязательно, что-бы последний был дочерним от процесса А; он может быть порожден Explorer или любым другим приложением. (В этом, кстати, и состоит преимущество механизма именования объектов перед наследованием.) Когда процесс В приступает к работе, исполняется код:
HANDLE hMutexProcessB = CreateMutex(NULL, FALSE, "JeffMutex");
При этом вызове система сначала проверяет, не существует ли уже объект ядра с таким именем. Если да, то ядро проверяет тип этого объекта. Поскольку мы пытаемся создать мьютекс и его имя тоже JeffMutex, система проверяет права доступа вызывающего процесса к этому объекту. Если у него есть все права, в таблице описателей, принадлежащей процессу В, создается новая запись, указывающая на существующий объект ядра. Если же вызывающий процесс не имеет полных прав на доступ к объекту или если типы двух объектов с одинаковыми именами не совпадают, вызов CreateMutex заканчивается неудачно и возвращается NULL.
Однако, хотя процесс В успешно вызвал CreateMutex, новый объект-мьютекс он не создал. Вместо этого он получил свой описатель существующего объекта-мьютекса. Счетчик объекта, конечно же, увеличился на 1, и теперь этот объект не разрушится, пока его описатели не закроют оба процесса — А и В. Заметьте, что значения описателей объекта в обоих процессах скорее всего разные, но так и должно быть, каждый процесс будет оперировать с данным объектом ядра, используя свой описатель.
NOTE:
Разделяя объекты ядра по именам, помните об одной крайне важной вещи.
Вызывая CreateMutex, процесс В передает ей атрибуты защиты и второй параметр. Так вот, эти параметры игнорируются, если объект с указанным именем уже существует! Приложение может определить, что оно делает: создает новый объект ядра или просто открывает уже существующий, — вызвав GetLastError сразу же после вызова одной из Create-функций:
HANDLE hMutex = CreateMutex(&sa, FALSE, "JeffObj");
if (GetLastError() == ERROR_ALREADY_EXISTS) {
// открыт описатель существующего объекта sa.lpSecurityDescriptor и второй параметр (FALSE) игнорируются
} else {
// создан совершенно новый объект sa.lpSecurityDescriptor и второй параметр (FALSE) используются при создании объекта
}
Есть и другой способ разделения объектов по именам. Вместо вызова Create-функции процесс может обратиться к одной из следующих Open-функций:
HANDLE OpenMutex(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
PCTSTR pszName);
HANDLE OpenEvent(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
PCTSTR pszName);
HANDLE OpenSemaphore(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
PCTSTR pszName),
HANDLE OpenWaitableTimer(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
PCTSTR pszName);
HANDLE OpenFileMapping(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
PCTSTR pszName);
HANDLE Openjob0bject(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
PCTSTR pszName);
Заметьте: все эти функции имеют один прототип. Последний параметр, pszName, определяет имя объекта ядра. В нем нельзя передать NULL — только адрес строки с нулевым символом в конце Эти функции просматривают единое пространство имен объектов ядра, пытаясь найти совпадение. Если объекта ядра с указанным именем нет, функции возвращают NULL, a GetLastError — код 2 (ERROR_FILE_NOT_FOUND). Но если объект ядра с заданным именем существует и если его тип идентичен тому, что Вы указали, система проверяет, разрешен ли к данному объекту доступ запрошенного вида (через параметр dwDesiredAccess).
Если такой вид доступа разрешен, таблица описателей в вызывающем процессе обновляется, и счетчик числа пользователей объекта возрастает на 1 Если Вы присвоили параметру bInheritHandle значение TRUE, то получше наследуемый описатель.
Главное отличие между вызовом Create- и Open-функций в том, что при отсутствии указанного объекта Create-функция создает его, а Open-функция просто уведомляет об ошибке.
Как я уже говорил, Microsoft ничего не сообщает о правилах именования объектов ядра Но представьте себе, что пользователь запускает две программы от разных компаний и каждая программа пытается создать объект с именем "MyObject". Ничего хорошего из этого не выйдет. Чтобы избежать такой ситуации, я бы посоветовал создавать GUID и использовать его строковое представление как имя объекта.
Именованные объекты часто применяются для того, чтобы не допустить запуска нескольких экземпляров одного приложения. Для этого Вы просто вызываете одну из Create-функций в своей функции main или WinMain и создаете некий именованный объект. Какой именно — не имеет ни малейшего значения. Сразу после Create-функции Вы должны вызвать GetLastError Если она вернет ERROR_ALREADY_EXISTS, значит, один экземпляр Вашего приложения уже выполняется и новый его экземпляр можно закрыть. Вот фрагмент кода, иллюстрирующий этот прием:
int WINAPI WinMain(HINSTANCE hinstExe, HINSTANCE, PSTR pszCmdLine, int nCmdShow} {
HANDLE h = CreateMutex(NULL, FALSE, "{FA531CC1-0497-11d3-A180-00105A276C3E}");
lf (GetLastError() == ERROR_ALREADY_EXISTS){
// экземпляр этого приложения уже выполняется
return(0),
}
// запущен первый экземпляр данного приложения
// перед выходом закрываем объект
CloseHandle(h),
return(0);
}
Пространства имен Terminal Server
Terminal Server несколько меняет описанный выше сценарий. На машине с Terminal Server существует множество пространств имен для объектов ядра. Объекты, которые должны быть доступны всем клиентам, используют одно глобальное пространство имен. (Такие объекты, как правило, связаны с сервисами, предоставляемыми клиентским программам.) В каждом клиентском сеансе формируется свое пространство имен, чтобы исключить конфликты между несколькими сеансами, в которых запускается одно и то же приложение.
Ни из какого сеанса нельзя получить доступ к объектам другого сеанса, даже если у их объектов идентичные имена.
Именованные объекты ядра, относящиеся к какому-либо сервису, всегда находятся в глобальном пространстве имен, а аналогичный объект, связанный с приложением, Terminal Server по умолчанию помещает в пространство имен киентского сеанca. Однако и его можно перевести в глобальное пространство имен, поставив перед именем объекта префикс "Global\", как в примере ниже.
HANDLE h = CreateEvenL(NULL, FALSE, FALSE, "Global\\MyName");
Если Вы хотите явно указать, что объект ядра должен находиться в пространстве имен клиентского сеанса, используйте префикс "Local\":
HANDLE h = CreateEvent(NULL, FALSE, FALSE, "Local\\MyName");
Microsoft рассматривает префиксы Global и Local как зарезервированные ключевые слова, которые не должны встречаться в самих именах объектов. К числу таких слов Microsoft относит и Session, хотя на сегодняшний день оно не связано ни с какой функциональностью. Также обратите внимание на две вещи, все эти ключевые слова чувствительны к регистру букв и игнорируются, если компьютер работает без Terminal Server.
Исключение издержек, связанных с синхронизацией потоков
Доступ к кучам упорядочивается по умолчанию, поэтому при одновременном обращении нескольких потоков к куче данные в ней никогда не повреждаются. Однако для этого функциям, работающим с кучами, приходится выполнять дополнительный код. Если Вы интенсивно манипулируете с динамически распределяемой памятью, выполнение дополнительного кода может заметно снизить быстродействие Вашей программы. Создавая новую кучу, Вы можете сообщить системе, что единовременно к этой куче обращается только один поток, и тогда дополнительный код выполняться не будет. Но береритесь: теперь Вы берете всю ответственность за целостность этой кучи на себя. Система не станет присматривать за Вами.
Исключения и отладчик
Отладчик Microsoft Visual C++ предоставляет фантастические возможности для отлад ки после исключений Когда поток процесса вызывает исключение, операционная система немедленно уведомляет об этом отладчик (если он, конечно, подключен). Это уведомление называется "первым предупреждением" (first-chance notification). Реаги руя на него, отладчик обычно заставляет поток искать фильтры исключений. Если все фильтры возвращают EXCEPTION_CONTINUE_SEARCH, операционная система вновь уведомляет отладчик, но на этот раз даст "последнее предупреждение" (last-chance notification). Существование этих двух типов предупреждений обеспечивает больший контроль за отладкой при исключениях
Чтобы сообщить отладчику, как реагировать на первое предупреждение, исполь зуйте диалоговое окно Exceptions отладчика.
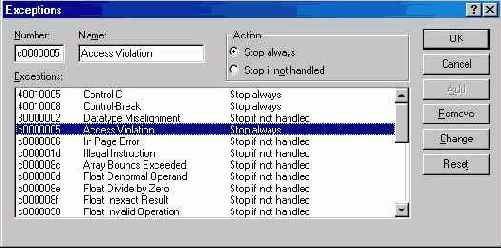
Как видите, оно содержит список всех исключений, определенных в системе. Для каждого из них сообщаются 32-битный код, текстовое описание и ответные действия отладчика. Я выбрал исключение Access Violation (нарушение доступа) и указал для него Stop Always. Теперь, если поток в отлаживаемом процессе вызовет это исключе ние, отладчик выведет при первом предупреждении следующее окно.
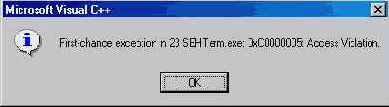
К этому моменту поток еще не получал шанса на поиск фильтров исключений Сейчас я могу поместить в исходный код точки прерывания, просмотреть значения переменных или проверить стек вызовов потока Пока ни один фильтр не выполнял ся — исключение произошло только что Когда я попытаюсь начать пошаговую от ладку программы, на экране появится новое окно
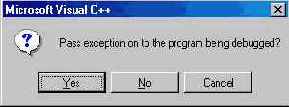
Кнопка Cancel вернст нас в отладчик Кнопка No заставит поток отлаживаемого процесса повторить выполнение неудавшейся машинной команды При большинстве исключений повторное выполнение команды ничего не даст, так как вновь вызовет исключение Однако, если исключение было сгенерировано с помощью функции RaiыeException, это позволит возобновить выполнение потока, и он продолжит рабо ту, как ни в чем ни бывало Данный метод может быть особенно полезен при отладке программ на С++ получится так, будто оператор throw никогда не выполнялся (К обработке исключений в С++ мы вернемся в конце главы)
И, наконец кнопка Yes разрешит потоку отлаживаемого процесса начать поиск фильтров исключений Если фильтр исключения, возвращающий EXCEPTION_EXE CUTE_HANDLER или EXCEPTION_CONTINUE_EXECUTION, найден, то все хорошо и поток продолжает работу Еспи же все фильтры вернут EXCEPTION_CONTINUE_ SEARCH, огладчик получит последнее предупреждение и выведет окно с сообщением, аналогичным тому, которое показано ниже
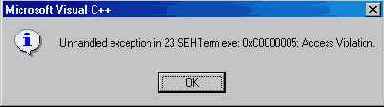
Здесь Вам придется либо начать отладку, либо закрыть приложение.
Я продемонстрировал Вам, что случится, ссли ответным действием отладчика выбран вариант Stop Always Но для большинства исключений по умолчанию предла гается варианг Stop If Not Handled B этом случае отладчик, получив первое предуп реждение, просто сообщает о нсм в своем окне Output.
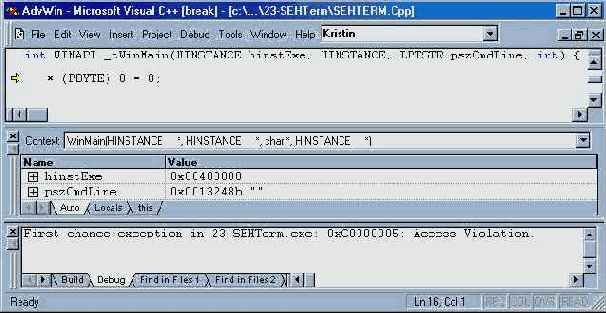
После этого отладчик разрешит потоку искать подходящие фильтры и, только если исключение не будет обработано, откроет следующее окно
NOTE
Очень важно помнить, что первое предупреждение вовсе не говорит о каких либо проблемах или "жучках" в приложении В сущности, оно появляется толь ко при отладке. Отладчик просто сообщает о возникновении исключения, и, если после эгого он не выводит уже известное Вам окно, это означает лишь одно фильтр обработал исключение, приложение продолжает нормально ра ботать. А вот последнее предупреждение говорит о том, что в Вашей програм ме есть некая проблема, которую надо устранить.
Прежде чем закончить обсуждение этой темы, хотелось бы упомянуть еще об од ной особенности диалогового окна Exceptions отладчика Оно полностью поддержи вает любые определяемые Вами программные исключения. От Вас требуется лишь указать уникальный числовой код исключения, сго название и ответное действие от ладчика, а затем, щелкнув киопку Add, добавить это повое исключение в список По смотрите, как это сделал я, определив собственное исключение.
Исключения С++ и структурные исключения
Разработчики часто спрашивают меня, что лучше использовать: SEH или исключения С++. Ответ на этот вопрос Вы найдете здесь.
Для начала позвольте напомнить, что SEH — механизм операционной системы, доступный в любом языке программирования, а исключения С++ поддерживаются только в С++. Создавая приложение на С++, Вы должны использовать средства имен но этого языка, а не SEH. Причина в том, что исключения С++ — часть самого языка и его компилятор автоматически создает код, который вызывает деструкторы объектов и тем самым обеспечивает корректную очистку ресурсов.
Однако Вы должны иметь в виду, что компилятор Microsoft Visual С++ реализует обработку исключений С++ на основе SEH операционной системы. Например, когда Вы создаете С++-блок try, компилятор генерирует SEH-блок _try. С++-блок catch ста новится SEH-фильтром исключений, а код блока catch — кодом SEH-блока __except. По сути, обрабатывая С++-оператор throw, компилятор генерирует вызов Windows функции RaiseException, и значение переменной, указанной в throw, передастся этой функции как дополнительный аргумент.
Сказанное мной поясняет фрагмент кода, показанный ниже. Функция слева ис пользует средства обработки исключений С++, а функция справа демонстрирует, как компилятор С++ создает соответствующие им SEH-эквиваленты.
void ChunkyFunky()
{
try
{
// тело блока try
...
throw 5;
}
catch (int x)
{
// тело блока catch
...
}
...
}
void ChunkyFunky()
{
__try
{
// тело блока try
...
RaiseException(Code=OxE06D7363, Flag=EXCEPTION_NONCONTINUABLE,Args=5);
}
_except ((ArgType == Integer) ? EXCEPTION_EXECUTE_HANDLER : EXCEPTION_CONTINUE_SFARCH)
{
// тело блока catch
...
}
}
Обратите внимание на несколько интересных особенностей этого кода. Во-пер вых, RaiseExeption вызывается с кодом исключения 0xE06D7363- Это код программ ного исключения, выбранный разработчиками Visual C++ на случай выталкивания (throwing) исключений С++ Вы можете сами в этом убедиться, открыв диалоговое окно Exceptions отладчика и прокрутив его список до конца, как на следующей ил люстрации.
Использование динамической TLS
Обычно, когда в DLL применяется механизм TLS-памяти, вызов DllMain со значением DLL_PROCESS_ATTACH заставляет DLL обратиться к TlsAlloc, а вызов DlIMain со значением DLL_PROCESS_DETACH — к TlsFree. Вызовы TlsSetVafae и TlsGetValue чаще всего происходят при обращении к функциям, содержащимся в DLL.
Вот один из способов работы с TLS-памятью: Вы создаете ее только по необходимости. Например, в DLL может быть функция, работающая аналогично strtok. При первом ее вызове поток передает этой функции указатель на 40-байтовую структуру, которую надо сохранить, чтобы ссылаться на нее при последующих вызовах. Поэтому Вы пишете свою функцию, скажем, так:
DWORD g_dwTlsIndex;
// считаем, что эта переменная инициализируется
// в результате вызова функции TlsAlloc
void MyFunction(PSOMFSTRUCT pSomeStruct)
{
if (pSomeStruct != NULL)
{
// вызывающий погок передает в функцию какие-то данные
// проверяем, не выделена ли уже область для хранения этих данных
if (TLsGetValue(g_dwTlsIndex) == NULL)
{
// еще не выделена, функция вызывается этим потоком впервые TlsSetValue(g_dwTlsIndex, HeapAlloc(GetProcessHeap(), 0, sizeof(*pSomeStruct));
}
// память уже выделена, сохраняем только что переданные значения memcpy(TlsGetValue(g_dwTlsIndex), pSomeStruct, sizeof(*pSomeStruct));
}
else
{
// вызывающий код уже передал функции данные;
// теперь что-то делаем с ними
// получаем адрес записанных данных
pSomeStruct = (PSOMESTRUCT) TlsGetValue(g_dwTlsIndex);
// на эти данные указывает pSomeStruct; используем ее
}
}
Если поток приложения никогда не вызовет MyFunction, то и блок памяти никогда не будет выделен.
Если Вам показалось, что 64 TLS-области — слишком много, напомню, приложение может динамически подключать несколько DLL. Одна DLL займет, допустим, 10 TLS-индсксов, вторая — 5 и т д. Так что это вовсе не много — напротив, стремитесь к тому, чтобы DLL использовала минимальное число TLS-индексов. И для этого лучше всего применять метод, показанный на примере функции MyFunction.
Конечно, я могу сохранить 40-байтовую структуру в 10 TLS-индексах, но тогда не только будет попусту расходоваться TLS-массив, но и затруднится работа с данными. Гораздо эффективнее выделить отдельный блок памяти для данных, сохранив указатель на него в одном TLS-индексе, — именно так и делается в MyFunction. Как я уже упомянул, в Windows 2000 количество TLS-областей увеличено до более чем 1000. Microsoft пошла на это из-за того, что многие разработчики слишком бесцеремонно использовали TLS-области и их не хватало другим DLL.
Теперь вернемсн к гому единственному проценту, о котором я обещал рассказать, рассматривая TlsAlloc. Взгляните на фрагмент кода:
DWORD dwTlsIntlex; PVOID pvSomeValue;
...
dwTlslndex = TlsAlloc();
TlsSetValue(dwTlsIndex, (PVOID) 12345);
TlsFree(dwTlsIndex);
// допустим, значение dwTlsIndex, возвращенное после этого вызова TlaAlloc,
// идентично индексу, полученному при предыдущем вызове TlsAlloc
dwTlsIndex = TlsAlloc();
pvSomeValue = TlsGetValue(dwTlsIndex);
Как Вы думаете, что содержится в pvSomeValue после выполнения этою кода? 12345? Нет — нуль. Прежде чем вернуть управление, TlsAlloc "проходит" по всем потокам в процессе и заносит 0 по только что выделенному индексу в массив каждого потока. И прекрасно1. Ведь не исключено, что приложение вызовет LoadLibrary, чтобы загрузить DLL, а последняя — TlsAlloc, чтобы зарезервировать какой-то индекс. Далее поток может обратиться к FreeLibrary и удалить DLL. Последняя должна освободить выделенный ей индекс, вызвав TlsFree, по кто знает, какие значения код DLL занес в тот или иной TLS-массив? В следующее мгновение поток вновь вызывает LoadLibrary и загружает другую DLL, которая тоже обращается к TlsAlloc и получает тот же индекс, что и предыдущая DLL. И если бы TlsAlloc не делала того, о чем я упомянул в самом начале, поток мог бы получить старое значение элемента, и программа стала бы работать некорректно.
Допустим, DLL, загруженная второй, решила проверить, выделена ли какому-то потоку локальная память, и вызвала TlsGetValue, как в предыдущем фрагменте кода.Если бы TlsAlloc не очищала соответствующий элемент в массиве каждого потока, то в этих элементах оставались бы старые данные от первой DLL. И тогда было бы вот что. Поток обращается к MyFunction, а та — в полной уверенности, что блок памяти уже выделен, — вызывает memcpy и таким образом копирует новые данные в ту область, которая, как ей кажется, и является выделенным блоком. Результат мог бы быть катастрофическим. К счастью, TlsAlloc инициализирует элементы массива, и такое просто немыслимо.
Использование куч в программах на С++
Чтобы в полной мере использовать преимущества динамически распределяемой памяти, следует включить ее поддержку в существующие программы, написанные па С++. В этом языке выделение памяти для объекта класса выполняется вызовом оператора new, а не функцией malloc, как в обычной библиотеке С. Когда необходимость в данном объекте класса отпадает, вместо библиотечной С-функции frее следует применять оператор delete. Скажем, у нас есть класс CSomeClasb, и мы хотим создать экземпляр этого класса. Для этого нужно написать что-то вроде.
CSomeClass* pSorneClass = new CSomeClass;
Дойдя до этой строки, компиляюр С++ сначала проверит, содержит ли класс CSomeClass функцию-член, переопределяющую оператор new. Если да, компилятор генерирует код для вызова этой функции Нет — создает код для вызова стандартного С++-оператора new.
Созданный объект уничтожается обращением к оператору delete
delete pSomeClass;
Переопределяя операторы new и delete для нашего C++ - класса, мы получаем возможность использовать преимущества функций, управляющих кучами. Для этого определим класс CSomeClass в заголовочном файле, скажем, так:
class CSomeClass
{
private
static HANDLE s_hHeap;
static UINT s_uNumAllocsInHeap;
// здесь располагаются закрытые данные и функции-члены
public:
void* operator new (size_t size);
void operator delete (void* p);
// здесь располагаются открытые данные и функции-члены
...
};
Я объявил два элемента данных, s_hHeap и s_uNumAllocsInHeap, как статические переменные А раз так, то компилятор С++ заставит все экземпляры класса CSomeClass использовать одни и те же переменные. Иначе говоря, он не станет выделять отдельные переменные s_hHeap и s_uNumAllocsInHeap для каждого создаваемого экземпля ра класса. Это очень важно: ведь мы хотим, чтобы все экземпляры класса CSomeClass были созданы в одной куче.
Переменная s_hHeap будет содержать описатель кучи, в которой создаются объекты CSomeClass. Переменная s_uNumAllocsInHeap - просто счетчик созданных в куче объектов CSomeClass.
Она увеличивается на 1 при создании в куче нового объекта CSomeClass и соответственно уменьшается при его уничтожении. Когда счетчик обнуляется, куча освобождается. Для управления кучей в СРР-файл следует включить примерно такой код:
HANDLE CSomeClass::s_hHeap = NULL;
UINT CSomeClass::s_uNumAllocsInHeap = 0;
void* CSomnClass::operator new (size_t size)
{
if (s_hHeap == NULL)
{
// куча не существует, создаем ее
s_hHeap = HeapCreate(HEAP_NO_SERIALIZE, 0, 0);
if (s_hHeap == NULL)
return(NULL);
}
// куча для объектов CSomeClass существует
void* p = HeapAlloc(s hHeap, 0, size);
if (p != NULL)
{
// память выделена успешно; увеличиваем счетчик объектов CSomeClass в куче
s_uNumAllocsInHeap++;
}
// возвращаем адрес созданного объекта CSomeClass
return(p);
}
Заметьте, что сначала я объявил два статических элемента данных, s_hHeap и s_uNumAllocsInHeap, а затем инициализировал их значениями NULL и 0 соответственно.
Оператор new принимает один параметр — size, указывающий число байтов, нужных для хранения CSomeClass Первым делом он создает кучу, если таковой нет. Для проверки анализируется значение переменной s_bHeap: если оно NULL, кучи нет, и тогда она создается функцией HeapCreate, а описатель, возвращаемый функцией, со храняется в переменной s_bHeap, чтобы при следующем вызове оператора new использовать существующую кучу, а не создавать еще одну.
Вызывая HeapCreate, я указал флаг HEAP_NO_SERIALIZE, потому что данная программа построена как однопоточная. Остальные параметры, указанные при вызове HeapCreate, определяют начальный и максимальный размер кучи. Я подставил на их место по нулю. Первый нуль означает, что у кучи нет начального размера, второй — что куча должна расширяться по мере необходимости.
Hе исключено, что Вам показалось, будто параметр size оператора new стоит передать в HeapCreatc как второй параметр. Вроде бы тогда можно инициализировать кучу так, чтобы она была достаточно большой для размещения одного экземпляра класса. И в таком случае функция HeapAlloc при первом вызове работала бы быстрее, так как не пришлось бы изменять размер кучи под экземпляр класса.
Увы, мир устроен не так, как хотелось бы. Из-за того, что с каждым выделенным внутри кучи блоком памяти связан свой заголовок, при вызове HeapAlloc все равно пришлось бы менять размер кучи, чтобы в нее поместился не только экземпляр класса, но и связанный с ним загловок.
После создания кучи из нее можно выделять память под новые объекты CSomeClass с помощью функции HeapAlloc. Первый параметр — описатель кучи, второй — раз мер объекта CSomeClass. Функция возвращает адрес выделенного блока.
Если выделение прошло успешно, я увеличиваю переменную-счетчик s_uNumAllocsInHeap, чтобы знать число выделенных блоков в куче. Наконец, оператор new возвращает адрес только что созданного объекта CSomeClass.
Вот так происходит создание нового объекта CSomeClasb. Теперь рассмотрим, как этот объект разрушается, — если он больше не нужен программе. Эта задача возлагается на функцию, переопределяющую оператор delete.
void CSomeClass::operator delete (void* p)
{
if (HeapFrce(s_hHcap, 0, p))
{
// объект удален успешно
s_uNumAllocsInKeap--;
}
if (s_uNumAllocsInHeap == 0)
{
// если в куче больше нет объектов, уничтожаем ее
if (HeapDestroy(s_hHeap))
{
// описатель кучи приравниваем NULL, чтобы оператор new
// мог создать новую кучу при создании нового объекта
CSomeClass s_hHeap = NULL;
}
}
}
Оператор delete принимает только один параметр: адрес удаляемого объекта. Сначала он вызывает HeapFree и передает ей описатель кучи и адрес высвобождаемого объекта. Если объект освобожден успешно, s_uNumAllocslnHeap уменьшается, показывая, что одним объектом CSomeClass в куче стало меньше. Далее оператор проверяет: не равна ли эта переменная 0, и, если да, вызывает HeapDestroy, передавая ей описа тель кучи. Если куча уничтожена, s_hHeap присваивается NULL. Это важно: ведь в будущем наша программа может попытаться создать другой объект CSomeClass. При этом будет вызван оператор new, который проверит значение s_hHeap, чтобы определить, нужно ли использовать существующую кучу или создать новую.
Данный пример иллюстрируеn очень удобную схему работы с несколькими кучами. Этот код легко подстроить и включить в Ваши классы. Но сначала, может быть, стоит поразмыслить над проблемой наследования. Если при создании нового класса Вы используете класс CSomeClass как базовый, то производный класс унаследует операторы new и delete, принадлежащие классу CSomeClass. Новый класс унаследует и его кучу, а это значит, что применение оператора new к производному классу повлечет выделение памяти для объекта этого класса из той же кучи, которую использует и класс CSomeClass. Хорошо это или нет, зависит от конкретной ситуации. Если объек ты сильно различаются размерами, это может привести к фрагментации кучи, что зятруднит выявление таких ошибок в коде, о которых я рассказывал в разделах "За щита компонентов" и "Более эффективное управление памятью".
Если Вы хотите использовать отдельную кучу для производных классов, нужно продублировать все, что я сделал для класса CSomeClass. И конкретнее - включить еще один набор переменных s_hHeap и s_uNumAllocsInHeap и повторить еще раз код для операторов new и delete. Компилятор увидит, что Вы переопределили в производном классе операторы new и delete, и сформирует обращение именно к ним, а не к тем, которые содержатся в базовом классе.
Если Вы не будете создавать отдельные кучи для каждого класса, то получите единственное преимущество: Вам не придется выделять память под каждую кучу и соответствующие заголовки. Но кучи и заголовки не занимают значительных объемов памяти, так что даже это преимущество весьма сомнительно. Неплохо, конечно, если каждый класс, используя свою кучу, в то же время имеет доступ к куче базового класса. Но делать так стоит лишь после полной отладки приложения. И, кстати, проблему фрагментации куч это не снимает.
Использование проецируемых в память файлов
Для этого нужно выполнить три операции:
1. Создать или открыть объект ядра "файл", идентифицирующий дисковый файл, который Вы хотите использовать как проецируемый в память.
2. Создать объект ядра "проекция файла", чтобы сообщить системе размер фай ла и способ доступа к нему.
3. Указать системе, как спроецировать в адресное пространство Вашего процес са объект "проекция файла" — целиком или частично.
Закончив работу с проецируемым в память файлом, следует выполнить тоже три операции:
1. Сообщить системе об отмене проецирования на адресное пространство про цесса объекта ядра "проекция файла".
2. Закрыть этот объект.
3. Закрыть объект ядра "файл".
Детальное рассмотрение этих операций — в следующих пяти разделах.
Изменение атрибутов защиты
Хоть это и не принято, но атрибуты защиты, присвоенные странице или страницам переданной физической памяти, можно изменять. Допустим, Вы разработали кол для управления связанным списком, узлы (вершины) которого хранятся в зарезервированном регионе. При желании можно написать функции, которые обрабатывали бы связанные списки и изменяли бы атрибуты защиты переданной памяти при старте на PAGE_READWRITE, а при завершении — обратно на PAGE_NOACCESS.
Сделав так, Вы защитите данные в связанном списке от возможных "жучков", скрытых в программе. Например, если какой то блок кода в Вашей программе из-за наличия "блуждающего" указателя обратится к данным в связанном списке, возникнет нарушение доступа. Поэтому такой подход иногда очень полезен — особенно когда пытаешься найти трудноуловимую ошибку в своей программе.
Атрибуты защиты страницы памяти можно изменить вызовом VirtualProtect.
BOOL VirtualProtect( PVOID pvAddress, SIZE_T dwSize, DWORD flNewProtect, PDWORD pflOldProtect);
Здесь pvAddress указывает на базовый адрес памяти (который должен находиться в пользовательском разделе Вашего процесса), dwSize определяет число байтов, для которых Вы изменяете атрибут защиты, а flNewProtect содержит один из идентифика торов PAGE_*, кроме PAGE_WRITECOPY и PAGE_EXECUTE_WRITECOPY.
Последний параметр, pftOldPrntect, содержит адрес переменной типа DWORD, в которую VirtualProtect заносит старое значение атрибута защиты для данной области памяти. В этом параметре (даже если Вас не интересует такая информация) нужно передать корректный адрес, иначе функция приведет к нарушению доступа
Естественно, атрибуты защиты связаны с целыми страницами памяти и не могут присваиваться отдельным байтам. Поэтому, если на процессоре с четырехкилобайто выми страницами вызвать VirtualProtect, например, так:
VirtualProtect(pvRgnBase + (3 * 1024), 2 * 1024, PAGE_NOACCESS, &flOldProtect);
то атрибут защиты PAGE_NOACCESS будет присвоен двум страницам памяти,
WINDOWS 98
Windows 98 поддерживает лишь атрибуты защиты PAGE_NOACCESS, PAGE_READ ONLY и PAGE_READWRITE. Попытка изменить атрибут защиты страницы на PAGEEXECUTE или PAGE_EXECUTE_READ приведет к тому, что эта область памяти получит атрибут PAGE_KEADONLY. А указав атрибут PAGE_EXECUTE_ READWRITE. Вы получите страницу с атрибутом PAGE_READWRITE.
Функцию VirtualProtect нельзя использовать для изменения атрибутов защиты стра ниц, диапазон которых охватывает разные зарезервированные регионы. В таких слу чаях VirtualProtect надо вызывать для каждого региона отдельно.
Изменение размера блока
Часто бывает необходимо изменить размер блока памяти. Некоторые приложения изначально выделяют больший, чем нужно, блок, а затем, разместив в нем данные, уменьшают его. Но некоторые, наоборот, сначала выделяют небольшой блок памяти и потом увеличивают его по мере записи новых данных. Для изменения размера блока памяти вызывается функция HeapReAlloc:
PVOID HeapReAlloc( HANDLE hHeap, DWORD fdwFlags, PVOID pvMem, SIZE_Т dwBytes);
Как всегда, параметр hHeap идентифицирует кучу, в которой содержится изменяемый блок. Параметр fdwFlags указывает флаги, используемые при изменении размеpa блока HEAP_GENERATE_EXCEPTIONS, HEAP_NO_SERIALIZE, HEAP_ZEROMEMORY или HEAP_REALLOC_IN_PLACE_ONLY.
Первые два флага имеют тот же смысл, что и при использовании с HeapAlloc. Флаг HEAPZEROMEMORY полезен только при увеличении размера блока памяти. В этом случае дополнительные байты, включаемые в блок, предварительно обнуляются. При уменьшении размера блока этот флаг не действует.
Флаг HEAP_REALLOC_IN_PLACE_ONLY сообщает HeapReAlloc, что данный блок памяти перемещать внутри кучи не разрешается (а именно это и может попытаться сделать функция при расширении блока). Если функция сможет расширить блок без его перемещения, она расширит его и вернет исходный адрес блока. С другой стороны, ссли для расширения блока его надо переместить, оня возвращает адрес нового, большего по размеру блока. Если блок затем снова уменьшается, функция вновь возвращает исходный адрес первоначального блока. Флаг HEAP_REALLOC_IN_PLACE_ ONLY имеет смысл указывать, когдя блок является частью связанного списка или дерева. В этом случае в других узлах списка или дерева могут содержаться указатели на данный узел, и его перемещение в куче непременно приведет к нарушению целостности связанного списка.
Остальные два параметра (pvMem и dwBytes) определяют текущий адрес изменяемого блока и его новый размер (в байтах). Функция HeapReAlloc возвращает либо адрес нового, измененного блока, либо NULL, ссли размер блока изменить не удалось.
Известные DLL
Некоторые DLL, поставляемые с операционной системой, обрабатываются по-особому. Они называются известными DLL (known DLLs) и ведут себя точно так же, кяк и любые другие DLL с тем исключением, что система всегда ищет их в одном и том же каталоге. D реестре есть раздел:
HKEY_LOCAL_MACHTNE\SYSTEM\CurrentControlSet\Control\Session Manager\KnownDLLs
Содержимое этого раздела может выглядеть примерно так, как показано ниже (при просмотре реестра с помощью утилиты RegEdit.exe).
Как видите, здесь содержится набор параметров, имена которых совпадают с именами известных DLL. Значения этих параметров представляют собой строки, идентичные именам параметров, но дополненные расширением .dll. (Впрочем, это не всегда так, и Вы сами убедитесь в этом на следующем примере) Когда Вы вызываете LoadLibrary или LoadLibraryEx, каждая из них сначала проверяет, указано ли имя DLL вместе с расширением .dll. Если нет, поиск DLL ведется по обычным правилам.
Если же расширение .dll указано, функция его отбрасывает и ищет в разделе реестра KnownDLLs параметр, имя которого совпадает с именем DLL. Если его нет, вновь применяются обычные правила поиска А если он есть, система считывает значение этого параметра и пытается загрузить заданную в нем DLL. При этом система ищет
DLL в каталоге, на который указывает значение, связанное с параметром реестра DllDirectory. По умолчанию в Windows 2000 параметру DllDirectory присваивается значение %SystemRoot%\System32
А теперь допустим, что мы добавили в раздел реестра KnownDLLs такой параметр
Имя параметра; SomeLib Значение параметра SomeOtherLib.dll
Когда мы вызовем следующую функцию, система будет искать файл по обычным правилам,
LoadLibrary("SomeLib");
Но если мы вызовем ее так, как показано ниже, система увидит, что в реестре есть параметр с идентичным именем (не забудьте она отбрасывает расширение .dll).
LoadLibrary("SomeLib dll");
Таким образом, система попытается загрузить SomeOtherLib.dll вместо SomcLib dll При этом она будет сначала искать SomeOtherLib.dll в каталоге %SystemRoot%\System32. Если нужный файл в этом каталоге есть, будет загружен именно он. Нет — LoadLibrary(Ex) вернет NULL, a GetLastError - ERROR_FILE_NOT_FOUND (2).
операционная система потребительского класса. Она
Windows 98 - операционная система потребительского класса. Она обладает многими возможностями Windows 2000, но некоторые ключевые из них не поддерживает. Так, Windows 98 не отнесешь к числу отказоустойчивых (приложение вполне способно привести к краху системы), она менее защищена, работает только с одним процессором (что ограничивает ее масштабируемость) и поддерживает Unicode лишь частично.
Microsoft намерена ликвидировать ядро Windows 98, поскольку его доработка до уровня ядра Windows 2000 потребовала бы слишком много усилий. Да и кому нужно еще одно ядро Windows 2000? Так что Windows 2000 - это вроде бы надолго, a Windows 98 проживет года два-три, если не меньше.
Но почему вообще существует ядро Wmdows 98? Ответ очень прост; Windows 98 более дружественна к пользователю, чем Windows 2000 Потребители не любят регистрироваться ня своих компьютерах, не хотят заниматься администрированием и т. д. Плюс ко всему в компьютерные игры они играют чаще, чем сотрудники корпораций в рабочее время (впрочем, это спорно). Многие старые игровые программы обращаются к оборудованию напрямую, что может приводить к зависанию компьютера. Windows 2000 - операционная система с отказоустойчивым ядром - такого не позволяет никому. Любая программа, которая пытается напрямую обратиться к оборудованию, немедленно завершается, не успев навредить ни себе, ни другим.
По этим причинам Windows 98 все еще с нами, и ее доля на рынке операционных систем весьма велика Microsoft активно работает над тем, чтобы Windows 2000 стала дружественнее к пользователю, - очень скоро появится потребительская версия ее ядра. Поскольку ядра Windows 98 и Windows 2000 имеют сходные наборы функциональных возможностей и поскольку они наиболее популярны, я решил сосредоточиться в этой книге именно на них.
Готовя книгу, я старался обращать внимание на отличия реализаций Win32 API в Windows 98 и Windows 2000. Материалы такого рода я обводил рамками и, как показано ниже, помечал соответствующими значками - чтобы привлечь внимание читателей к каким-то деталям, характерным для той или иной платформы.
WINDOWS 98
Здесь рассказывается об особенностях реализации на платформе Windows 98.
WINDOWS 2000
А тут - об особенностях реализации на платформе Windows 2000.
Windows 95 я особо не рассматриваю, но все, что относится к Windows 98, применимо и к ней, так как ядра у них совершенно одинаковые.
это операционная система Microsoft класса
Windows 2000 - это операционная система Microsoft класса "high-end" Список ее возможностей и особенностей займет не одну страницу. Вот лишь некоторые из них (в совершенно произвольном порядке).
Windows 2000 рассчитана на рабочие станции и серверы, а также на применение в центрах обработки данных Отказоустойчива - плохо написанные программы не могут привести к краху системы. Защищена - несанкционированный доступ к ресурсам (например, файлам или принтерам), управляемым этой системой, невозможен. Богатый набор средств и утилит для администрирования системы в масштабах организации. Ядро Windows 2000 написано в основном на С и С++, поэтому система легко портируется (переносится) на процессоры с другими архитектурами. Полностью поддерживает Unicode, что упрощает локализацию и работу с использованием различных языков. Имеет высокоэффективную подсистему управления памятью с чрезвычайно широкими возможностями. Поддерживает структурную обработку исключений (structured exception handling, SEH), облегчая восстановление после ошибок. Позволяет расширять функциональность зa счет динамически подключаемых библиотек (DLL). Поддерживает многопоточность и мультипроцессорную обработку, обеспечивая высокую масштабируемость системы, Файловая система Windows 2000 дает возможность отслеживать, как пользователи манипулируют с данными на своих машинах.
Ядро Windows CE
Windows CE - самое новое ядро Windows от Microsoft Оно рассчитано главным образом на карманные и автомобильные компьютеры, "интеллектуальные" терминалы, тостеры, микроволновые печи и торговые автоматы. Большинство таких устройств должно потреблять минимум электроэнергии, у них очень мало памяти, а дисков чаще всего просто нет. Из-за столь жестких ограничений Microsoft пришлось создать совершенно новое ядро операционной системы, намного менее требовательное к памяти, чем ядро Windows 98 или Windows 2000.
Как ни странно, Windows CE довольно мощная операционная система. Устройства, которыми она управляет, предназначены только для индивидуального использования, поэтому ее ядро не поддерживает администрирование, масштабирование и т. д. Тем не менее практически все концепции Win32 применимы и к данной платформе. Различия обычно проявляются там, где Windows CE накладывает ограничения на те или иные Win32-функции