Явная выгрузка DLL
Если необходимость в DLL отпадает, ее можно выгрузить из адресного пространства процесса, вызвав функцию.
BOOL FreeLibrary(HINSTANCE hinstDll);
Вы должны передать в FreeLibrary значение типа HINSTANCE, которое идентифицирует выгружаемую DLL. Это значение Вы получаете после вызова LoadLibrary(Ex).
DLL можно выгрузить и с помощью другой функции:
VOID FreeLibraryAndExitThread( HlNSTANCE hinstDll, DWORD dwExitCode);
Она реализована в Kernel32.dll так:
VOID FreeLibraryAndExitThread(HINSTANCE hinstDll, DWORD dwExitCode)
{
FreeLibrary(hinstDll);
ExitThread(dwExitCode);
}
На первый взгляд, в ней нет ничего особенного, и Вы, наверное, удивляетесь, с чего это Microsoft решила ее написать. Но представьте такой сценарий. Вы пишете DLL, которая при первом отображении на адресное пространство процесса создает поток. Последний, закончив свою работу, отключает DLL от адресного пространства процесса и завершается, вызывая сначала FreeLibrary, а потом ExttThread.
Если поток станет сам вызывать FreeLibrary и ExitThread, возникнет очень серьезная проблема: FreeI.ibrary тут же отключит DLL от адресного пространства процесса. После возврата из FreeLibrary код, содержащий вызов ExttThread, окажется недоступен, и поток попытается выполнить не известно что. Это приведет к нарушению доступа и завершению всего процесса!
С другой стороны, если поток обратится к FreeLibraryAndExitThread, она вызовет FreeLibrary, и та сразу же отключит DLL, Но следующая исполняемая инструкция находится в KerneI32.dlI, а нс в только что отключенной DLL. Значит, поток сможет продолжить выполнение и вызвать ExitThread, которая корректно завершит его, не возвращая управления.
Впрочем, FreeLibraryAndExitThread может и не понадобиться. Мне она пригодилась лишь раз, когда я занимался весьма нетипичной задачей. Да и код я писал под Windows NT 3-1, где этой функции не было. Наверное, поэтому я так обрадовался, обнаружив ее в более новых версиях Windows.
На самом деле LoadLibrary и LoadLibraryEx лишь увеличивают счетчик числа пользователей указанной библиотеки, a FreeLibrary и FreeLibraryAndExitThread его уменьшают Так, при первом вызове LoadLibrary дум загрузки DLL система проецирует образ DLL-файла иа адресное пространство вызывающего процесса и присваивает единицу счетчику числа пользователей этой DLL Если поток того же процесса вызывает LoadLibrary для той же DLL еще раз, DLL больше не проецируется; система просто увеличивает счетчик числа ее пользователей — вот и все.
Чтобы выгрузить DLL из адресного пространства процесса, FreeLibrary придется теперь вызывать дважды: первый вызов уменьшит счетчик до 1, второй — до 0. Обнаружив, что счетчик числа пользователей DLL обнулен, система отключит ее. После этого попытка вызова какой-либо функции из данной DLL приведет к нарушению доступа, так как код по указанному адресу уже не отображается на адресное пространство процесса.
Система поддерживает в каждом процессе свой счетчик DLL, т. e. если поток процесса А вызывает приведенную ниже функцию, а затем тот же вызов делает поток в процессе В, то MyLib.dll проецируется на адресное пространство обоих процессов, а счетчики числа пользователей DLL в каждом из них приравниваются 1.
HINSTANCE hinstDll = LoadLibrary("MyLib.dll");
Если же поток процесса В вызовет далее:
FreeLibrary(hinst011);
счетчик числа пользователей DLL в процессе В обнулится, что приведет к отключению DLL oт адресного пространства процесса В. Но проекция DLL на адресное пространство процесса А нс затрагивается, и счетчик числа пользователей DLL в нем остается прежним.
Чтобы определить, спроецирована ли DLL на адресное пространство процесса, поток может вызывать функцию GеtМоdu1еНапd1е:
HINSTANCE GetModuleHandle(PCTSTR pszModuleName);
Например, следующий код загружает MyLib.dll, только если она еще не спроецирована на адресное пространство процесса
HINSTANCE hinstDll = GetHoduleHandle("MyLib");
// подразумевается расширение .dll if (hinstDll == NULL)
{
hinstDll = LoadLibrary("MyLib");
// подразумевается расширение .dll
}
Если у Вас есть значение HINSTANCE для DLL, можно определить полное (вместе с путем) имя DLL или EXE с помощью GetModuleFileName
DWORD GetModuleFileName( HINSTANCE hinstModule, PTSTR pszPathName, DWORD cchPath);
Первый параметр этой функции — значение типа HINSTANCE нужной DLL (или EXE). Второй параметр, pszPathName, задает адрес буфера, в который она запишет полное имя файла Третий, и последний, параметр (cchPath) определяет размер буфера в символах.
Явная загрузка DLL
В любой момент поток может спроецировать DLL на адресное пространство процесca, вызвав одну из двух функций:
HINSTANCE LoadLibrary{PCTSTR pszDLLPathName);
HINSTANCE LoadLibraryEx( PCTSTR pszDLLPathName, HANDLE hFile, DWORD dwFlags);
Обе функции ищут образ DLL-файла (в каталогах, список которых приведен в предыдущей главе) и пытаются спроецировать его на адресное пространство вызывающего процесса. Значение типа HINSTANCE, возвращаемое этими функциями, сообщает адрес виртуальной памяти, но которому спроецирован образ файла. Если спроецировать DLL на адресное пространство процесса не удалось, функции возвращают NULL Дополнительную информацию об ошибке можно получить вызовом GetLastError.
Очевидно, Вы обратили внимание на два дополнительных параметра функции LoadLibraryEx, hFile и dwFlags. Первый зарезервирован для использования в будущих версиях и должен быть NULL Bo втором можно передать либо 0, либо комбинацию флагов DONT_RESOLVE_DLL_REFERENCES, LOAD_LIBRARY_AS_DATAFILE и LOAD_WITH_ALTERED_SEARCH_PATH, о которых мы сейчас и поговорим.
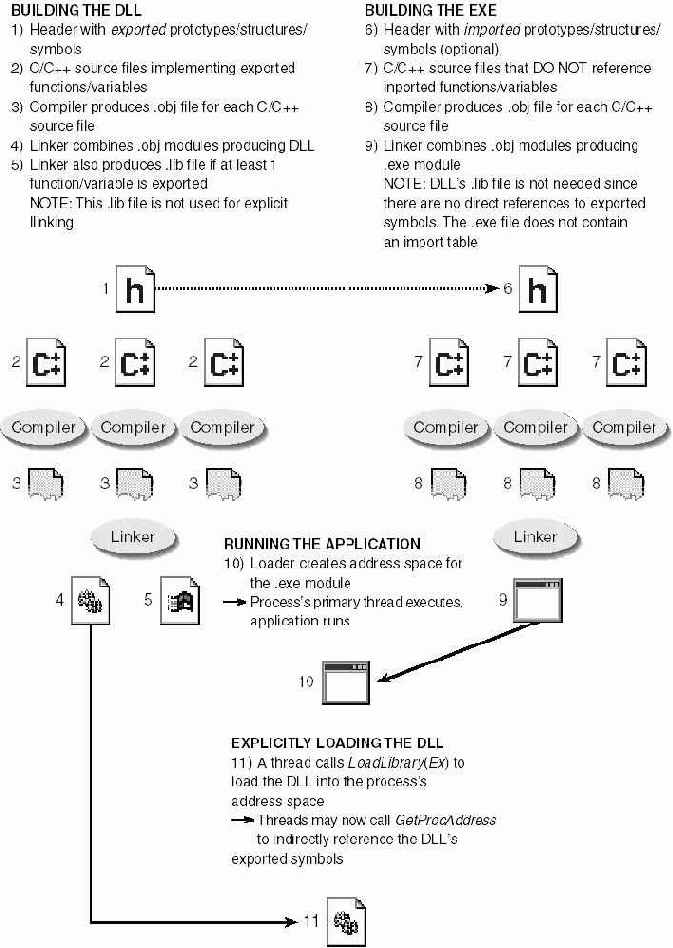
| СОЗДАНИЕ DLL
1 ) Заголовочный файл с экспортируемыми прототипами структурами и идентификаторами (символьными именами) 2) Исходные файлы С/С++ в которых реализованы экспортируемые функции и определены переменные 3) Компилятор создает OBJ-файл из каждого исходного файла С/С++ 4) Компоновщик собирает DLL из OBJ модулей 5) Если DLL экспортирует хотя бы одну переменную или функцию компоновщик создает и LIB-файл {при явном связывании этот файл не используется) | СОЗДАНИЕ ЕХЕ
6) Заголовочный файл с импортируемыми прототипами, структурами и идентификаторами 7) Исходные файлы С/С++ в которых нет ссылок на импортируемые функции и переменные 8) Компилятор создает OBJ файл из каждого исходного файла С/С++ 9) Компоновщик собирает ЕХЕ-модуль из OBJ-модулей (LIB файл DLL не нужен, так как нет прямых ссылок на экспортируемые идентификаторы, раздел импорта в ЕХЕ-модуле отсутствует) |
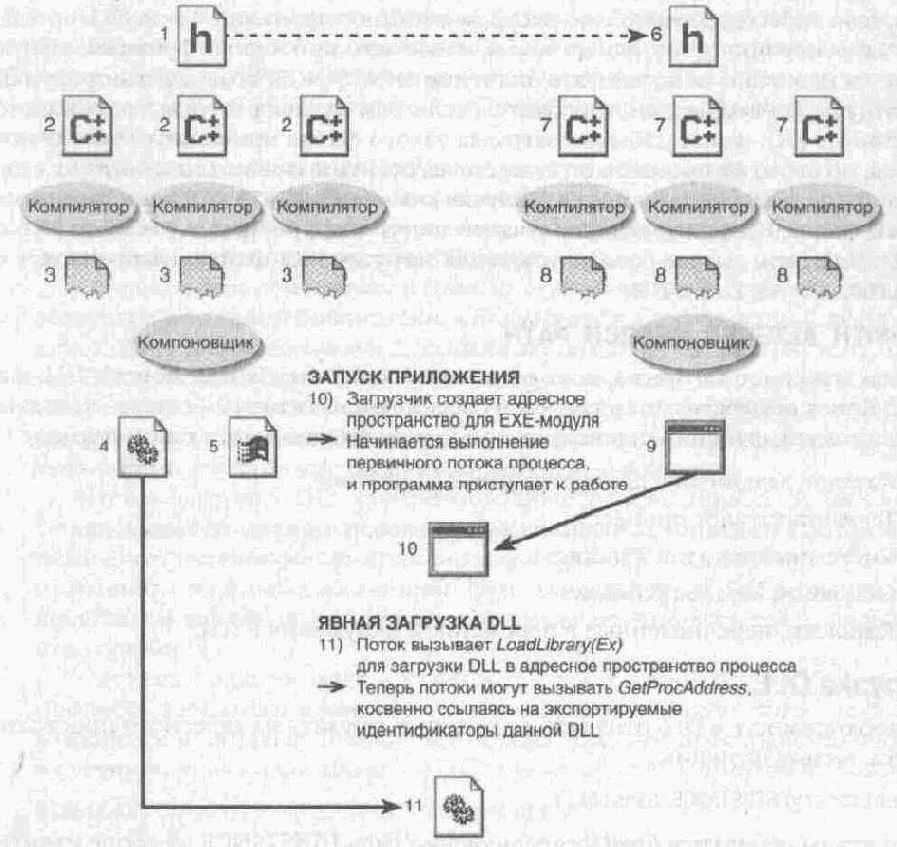
Рис. 20-1. Так DLL создается и явно связывается с приложением
DONT_RESOLVE_DLL_REFERENCES
Этот флаг указывает системе спроецировать DLL на адресное пространство вызывающего процесса. Проецируя DLL, система обычно вызывает из нее специальную функцию DllMain (о ней — чуть позже) и с ее помощью инициализирует библиотеку. Так вот, данный флаг заставляет систему проецировать DLL, не обращаясь к DllMain.
Кроме того, DLL может импортировать функции из других DLL. При загрузке библиотеки система проверяет, использует ли она другие DLL; если да, то загружает и их. При установке флага DONT_RESOLVE_DLL_REFERENCES дополнительные DLL автоматически не загружаются.
LOAD_LIBRARY_AS_DATAFILE
Этот флаг очень похож на предыдущий. DLL проецируется на адресное пространство процесса так, будто это файл данных. При этом система не тратит дополнительное время на подготовку к выполнению какого-либо кода из данного файла Например, когда DLL проецируется на адресное пространство, система считывает информацию из DLL-файла и на ее основе определяет, какие атрибуты защиты страниц следует присвоить разным частям файла. Если флаг LOAD_LIBRARY_AS_DATAFILE не указан, атрибуты защиты устанавливаются такими, чтобы код из данного файла можно было выполнять.
Этот флаг может понадобиться по нескольким причинам. Во-первых, его стоит указать, если DLL содержит только ресурсы и никаких функций. Тогда DLL проецируется на адресное пространство процесса, после чего при вызове функций, загружающих ресурсы, можно использовать значение HINSTANCE, возвращенное функцией LoadLibraryEx. Во-вторых, он пригодится, если Вам нужны ресурсы, содержащиеся в каком-нибудь ЕХЕ-файле. Обычно загрузка такого файла приводит к запуску нового процесса, но этого не произойдет, если его загрузить вызовом LoadLibraryEx в адресное пространство Вашего процесса. Получив значение HINSTANCE для спроецированного ЕХЕ-файла, Вы фактически получаете доступ к его ресурсам. Так как в ЕХЕ-файле нет DllMain, при вызове LoadLibraryEx для загрузки ЕХЕ-файла нужно указать флаг LOAD_LIBRARY_AS_DATAFILE.
LOAD_WITH_ALTERED_SEARCH_PATH
Этот флаг изменяет алгоритм, используемый LoadLibraryEx при поиске DLL-файла. Обычно поиск осуществляется так, как я рассказывал в главе 19 Однако, если данный флаг установлен, функция ищет файл, просматривая каталоги в таком порядке
Каталог, заданный в napaмeтре pszDLLPathName. Текущий каталог процесса. Системный каталог Windows. Основной каталог Windows. Каталоги, перечисленные в переменной окружения PATH
Явная загрузка DLL и связывание идентификаторов
Чтобы поток мог вызвать функцию из DLL-модуля, последний надо спроецировать на адресное пространство процесса, которому принадлежит этот поток. Делается это двумя способами. Первый состоит в том, что код Вашего приложения просто ссылается на идентификаторы, содержащиеся в DLL, и гем самым заставляет загрузчик неявно загружать (и связывать) нужную DLL при запуске приложения.
Второй способ — явная загрузка и связывание требуемой DLL в период выполнения приложения Иняче говоря, его поток явно загружает DLL в адресное пространство процесса, получает виртуальный адрес необходимой DLL-функции и вызывает ее по этому адресу. Изящество такого подхода в том, что все происходит в уже выполняемом приложении.
На рис 20-1 показано, как приложение явно загружает DLL и связывается с ней.
Явное подключение экспортируемого идентификатора
Поток получает адрес экспортируемого идентификатора из явно загруженной DLL вызовом GetProcAddress:
FARPROC GetProcAddress( HINSTANCE hinstDll, PCSTR pszSymbolName);
Параметр hinstDll — описатель, возвращенный LoadLibrary(Ex) или GetModuleHandle и относящийся к DLL, которая содержит нужный идентификатор. Параметр pszSymbolName разрешается указывать в двух формах. Во-первых, как адрес строки с нулевым символом в конце, содержащей имя интересующей Вас функции:
FARPROC pfn = GetProcAddress(hinstDll, "SomeFuncInDll");
Заметьте, тип параметра pszSymbolName — PCSTR, а не PCTSTR. Это значит, что функция GetProcAddress принимает только ANSI-строки — ей нельзя передать Unicodeстроку А причина в том, что идентификаторы функций и переменных в разделе экспорта DLL всегда хранятся как ANSI-строки.
Вторая форма пapaмeтpa pszSymbolName позволяет указывать порядковый номер нужной функции.
FARPROC pfn = GetProcAddress(hinstDll, MAKEINTRESOURCE(2));
Здесь подразумевается, что Вам известен порядковый номер (2) искомого идентификатора, присвоенный ему автором данной DLL И вновь повторю, что Microsoft
настоятельно не рекомендует пользоваться порядковыми номерами; поэтому Вы редко встретите второй вариант вызова GetProсAddress.
При любом способе Вы получаете адрес содержащегося в DLL идентификатора. Если идентификатор не найден, GetProcAddress возвращает NULL.
Учтите, что первый способ медленнее, так как системе приходится проводить поиск и сравнение строк. При втором способе, если Вы передаете порядковый номер, не присвоенный ни одной из экспортируемых функций, GetProcAddress может вернуть значение, отличное от NULL В итоге Ваша программа, ничео не подозревая, получит неправильный адрес. Попытка вызова функции по этому адресу почти наверняка приведет к нарушению доступа Я и сам — когда только начинал программировать под Windows и не очень четко понимал эти вещи — несколько раз попадал в эту ловушку. Так что будьте внимательны. (Вот Вам, кстати, и еще одна причина, почему от использования порядковых номеров следует отказаться в пользу символьных имен — идентификаторов.)
Явный вызов функции UnhandledExceptionFilter
Функция UnhandledExceptionFilter полностью задокументирована, и Вы можете сами вызывать ее в своих программах. Вот пример ее использования:
void Funcadelic()
{
__try
{
...
}
__except (ExpFltr(GetExceptionTnformation()))
{
...
}
}
LONG ExpFltr(PEXCEPTION_POINTERS pEP)
{
DWORD dwExceptionCode - pEP->ExceptionRecord.ExceptionCode;
if (dwExceptionCode == EXCEPTION_ACCESS_VIOLATION)
{
// что-то делаем здесь...
return(EXCEPTION_CONTINUE_EXFCUTION);
}
return(UnhandledExceptionFilter(pEP));
}
Исключение в блоке try функции Funcadelic приводит к вызову ExpFltr. Ей переда ется значение, возвращаемое GetExceptionlnformation. Внутри фильтра определяется код исключения и сравнивается с EXCEPTION_ACCESS_VIOLATION. Если было нару шение доступа, фильтр исправляет ситуацию и возвращает EXCEPTION_CONTI NUE_EXECUTION. Это значение заставляет систему возобновить выполнение програм мы с инструкции, вызвавшей исключение.
Если произошло какое-то другое исключение, ExpFltr вызывает UnhandledExcep tionFilter, передавая ей адрес структуры EXCEPTION_POINTERS. Функция Unhandled ExceptionFilter открывает окно, позволяющее завершить процесс или начать отладку. Ее возвращаемое значение становится и результатом функции ExpFltr.
Этап 2: создание объекта ядра "проекция файла"
Вызвав CreateFile, Вы указали операционной системе, где находится физическая па мять для проекции файла на жестком диске в сети, на CD-ROM или в другом месте Теперь сообщите системе, какой обьем физической памяти нужен проекции файла Для этого вызовите функцию CreateFileMapping
HANDLE CreateFileMapping( HANDLE hFile, PSECURITY_ATTRIBUTES psa, DWORD fdwProtect, DWOPD dwMaximumSizeHigh, DWORD dwMaximumSizcLow, PCSTR pszName);
Первый параметр, hFile, идентифицирует описатель файла, проецируемою на ад реснос пространство процесса этот описатель Вы получили после вызова CreateFile Параметр psa — указатель на структуру SECURITY_ATTRIBUTES, которая относится к обьекту ядра "проекция файла", для установки защиты по умолчанию ему присваива ется NULL
Как я уже говорил в начале этой главы, создание файла, проецируемого в память, аналогично резервированию региона адресного пространства с последующей пере дачей сму физической памяти Разница лишь в том, что физическая память для про ецируемого файла — сам файл на диске, и для него не нужно выделять пространство в страничном файле. При создании объекта "проекция файла" система не резервиру ет регион адресного пространства и не увязывает его с физической памятью из фай ла (кяк это сделать, я расскажу в следующем разделе). Но, как только дело дойдет до отображения физической памяти на адресное пространство процесса, системе пона добится точно знать атрибут защиты, присваиваемый страницам физической памя ти Поэтому в fdwProteсе надо указать желательные атрибуты защиты. Обычно ис пользуется один из перечисленных в следующей таблице.
|
Атрибут защиты |
Описание | ||
|
PAGE_READONLY |
Отобразив объект "проекция файла" на адресное пространство, можно считывать данные из файла. При этом Вы должны были пе редать в CreateFile флаг GENERIC_READ. | ||
|
PAGE_READWRITE |
Отобразив объект "проекция файла" на адресное пространство, можно считывать данные из файла и записывать их При этом Вы должны были передать в CreateFile комбинацию флагов GENERIC_READ | GENERIC_WRITE. | ||
|
PAGE_WRITECOPY |
Отобразив объект "проекция файла" на адресное пространство, можно считывать данные из файла и записывать их. Запись приве дет к созданию закрытой копии страницы При этом Вы должны были передать в CreateFile либо GENERIC_READ, либо GENERIC_READ | GENERIC_WRITE |
WINDOWS 98
Windows 98 функции CreateFileMapping можно передать флаг PAGE_WRITE COPY; тем самым Вы скажете системе передать физическую память из странич ного файла. Эта память резервируется для копии информации из файла дан ных, и лишь модифицированные страницы действительно записываются в страничный файл. Изменения не распространяются на исходный файл данных. Результат применения флага PAGE_WRITECOPY одинаков в Windows 2000 и в Windows 98
Кроме рассмотренных выше атрибутов защиты страницы, существует еще и че тыре атрибута раздела; их можно ввести в параметр fdwProtect функции CreateFile Mapping побитовой операцией OR. Раздел (section) — всего лишь еще одно название проекции памяти.
Первый из этих атрибутов, SEC_NOCACHE, сообщает системе, что никакие стря ницы файла, проецируемого в память, кэшировать не надо. В результате при записи данных в файл система будет обновлять данные на диске чаще обычного. Этот флаг, как и атрибут защиты PAGE_NOCACHE, предназначен для разработчиков драйверов устройств и обычно в приложениях пе используется.
WINDOWS 98
Windows 98 игнорирует флаг SEC_NOCACHE.
Второй атрибут, SEC_IMAGE, указывает системе, что данный файл является пере носимым исполняемым файлом (portable executable, PE). Отображая его на адресное пространство процесса, система просматривает содержимое файла, чтобы опреде лить, какие атрибуты защиты следует присвоить различным страницам проецируе
мого образа (mapped image). Например, раздел кода РЕ-файла (text) обычно проеци руется с атрибутом PAGE_EXECUTE_READ, тогда как раздел данных этого же файла (.data) — с атрибутом PAGE_READWRITE Атрибут SEC_IMAGE заставляет систему спро ецировать образ файла и автоматически подобрать подходящие атрибуты защиты страниц
WINDOWS 98
Windows 98 игнорирует флаг SEC_IMAGE.
Последние два атрибута (SEC_RESERVE и SEC_COMMIT) взаимоисключают друг друга и неприменимы для проецирования в память файла данных. Эти флаги мы рас смотрим ближе к концу главы. CreateFileMapping их игнорирует
Следующие два параметра этой функции (dwMaximumSizeHigh и dwMaximum SizeLow) самые важные.
Основное назначение CreateFileMapping — гарантировать, что объекту " проекция файла" доступен нужный объем физической памяти Через эти параметры мы сообщаем системе максимальный размер файла в байтах. Так как Win dows позволяет работать с файлами, размеры которых выражаются 64-разрядными числами, в параметре dwMaximumSizeHigh указываются старшие 32 бита, а в dwMaxi mumSizeI.ow - младшие 32 бита этого значения. Для файлов размером менее 4 Гб dwMaximumSizeHigh всегда равен 0. Наличие 64-разрядного значения подразумевает, что Windows способна обрабатывать файлы длиной до l6 экзабайтов
Для создания объекта "проекция файла" таким, чтобы он отражал текущий раз мер файла, передайте в обоих параметрах нули. Так же следует поступить, если Вы собираетесь ограничиться считыванием или как-то обработать файл, не меняя его раз мер Для дозаписи данных в файл выбирайте его размер максимальным, чтобы оста вить пространство "для маневра" Если в данный момент файл на диске имеет нуле вую длину, в параметрах dwMaximumSizeHigh и dwMaximumSizeLow нельзя передавать нули Иначе система решит, что Вам нужна проекция файла с объемом памяти, рав ным 0. А это ошибка, и CreateFileMapping вернет NULL
Если Вы еще следите за моими рассуждениями, то, должно быть, подумали: что-то тут нс все ладно. Очень, конечно, мило, что Windows поддерживает файлы и их про екции размером вплоть до 16 экзабайтов, но как, интересно, спроецировать такой файл на адресное пространство 32-разрядного процесса, ограниченное 4 Гб, из ко торых и использовать-то можно только 2 Гб? На этот вопрос я отвечу в следующем разделе. (Конечно, адресное пространство 64-разрядного процесса, размер которого составляет 16 экзабайтов, позволяет работать с еще большими проекциями файлов, но аналогичное ограничение существует и там)
Чтобы досконально разобраться, как работают функции CreateFtle и CreateFile Mapping, предлагаю один эксперимент Возьмите код, приведенный ниже, соберите его и запустите под отладчиком.
Пошагово выполняя операторы, переключитесь в окно командного процессора и запросите содержимое каталога "C:\" командой dir Обратите внимание на изменения, происходящие в каталоге при выполнении каждо го оператора.
int WINAPI _tWinMain(HINSIANCE hinstExe, HINSTANCE, PISTR pszCmdLine, int nCmdShow)
{
// перед выполнением этого оператора, в каталоге C:\
// еще нет файла "MMFTest.dat"
HANOLE hfile = CreateFile("C.\\MMFTest dat", GENERIC_READ | GENERIC_WRITE, FILE_SHARE_READ | FILE_SHARE_WRITE_, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
// перед выполнением этого оператора файл MMFTest.dat существует,
// но имеет нулевую длину
HANDLE htilemap = CreateFileMapping(hfile, NULL, PAGE_READWRITE, 0, 100, NULL);
// после выполнения предыдущею оператора размер файла MMFTest.dat
// возрастает до 100 байтов
// очистка
CloseHandle(hfilemap);
CloseHandle(hfile);
// по завершении процесса файл MMFTest.dat останется
// на диске и будет иметь длину 100 байтов
return(0);
}
Вызов CreateFileMapping с флагом PAGE_READWRITE заставляет систему проверять, чтобы размер соответствующего файла данных на диске был нс меньше, чем указано в параметрах dwMaximumSizeHigh и dwMaximumSizeLow. Если файл окажется меньше заданного, CreateFileMapping увеличит его размер до указанной величины. Это дела ется специально, чтобы выделить физическую память перед использованием файла в качестве проецируемого в память. Если объект "проекция файла" создан с флагом PAGE_READONLY или PAGE_WRITECOPY, то размер, переданный функции Create FileMapping, не должен превышать физический размер файла на диске (так как Вы не сможете что-то дописать в файл).
Последний параметр функции CreateFileMapping — pszName — строка с нулевым байтом в конце; в ней указывается имя объекта "проекция файла", которое использу ется для доступа к данному объекту из другого процесса (пример см, в главе 3). Но обычно совместное использование проецируемого в память файла не требуется, и поэтому в данном параметре передают NULL.
Система создает объект "проекция файла" и возвращает его описатель в вызвав ший функцию поток. Если объект создать не удалось, возвращается нулевой описа тель (NULL). И здесь еще раз обратите внимание на отличительную особенность фун кции CreateFile — при ошибке она возвращает не NULL, а идентификатор INVALID_ HANDLE_VALlJE (определенный как - 1).
Этап 3: проецирование файловых данных на адресное пространство процесса
Когда объект "проекция файла"создан, нужно, чтобы система, зарезервировав реги он адресного пространства под данные файла, передала их как физическую память, отображенную на регион. Это делает функция MapViewOfFile
PVOID MapViewOfFile( HANDLE hFileMappingObject, DWORD dwDesiredAccess, DWORD dwFileOffsetHigh, DWORD dwFileOffsetLow, SIZE_T dwNumberOfBytesToMap);
Параметр hFileMappingObject идентифицирует описатель объекта "проекция фай ла", возвращаемый предшествующим вызовом либо CreateFtleMapping, либо OpenFile Mapping (ее мы рассмотрим чуть позже) Параметр dwDesiredAccess идентифицирует вид доступа к данным Bce правильно придется опять указывать, как именно мы хо тим обращалься к файловым данным Можно задать одно из четырех значений, опи санных в следующей таблице
|
Значение |
Описание | ||
|
FILE_MAP_WRITE |
Файловые данные можно считывать и записывать, Вы должны были передать функции CreateFileMapping атрибут PAGE_READWRITE | ||
|
FILE MAF_READ |
Файловые данные можно только считывать Вы должны были вызвать CreateFileMapping с любым из следующих атрибутов PAGE_READONLY, PAGE_READWRITE или PAGE_WRITECOPY | ||
|
FILE_MAP_ALL_ACCESS |
То же, что и FILE_MAP_WRITE | ||
|
FILE_MAP_COPY |
Файловые данные можно считывать и записывать, но запись приводит к созданию закрытой копии страницы Вы должны были вызвать CrealeFileMapping с любым из следующих атрибу тов PAGE_READONIY, PAGE_READWRITE или РАСЕ_WRITECOPY (Windows 98 требует вызывать CreateFileMapping с атрибутом PACE_WRITECOPY) |
Кажется странным и немного раздражает, что Windows требует бесконечно ука зывать все эти атрибуты защиты Могу лишь предположить, что это сделано для того, чтобы приложение максимально полно контролировало защиту данных
Остальные три параметра относятся к резервированию региона адресного про странства и к отображению на него физической памяти При этом необязательно проецировать на адресное пространство весь файл сразу Напротив, можно спроеци ровать лишь малую его часть, которая в таком случае называется представлением (view) — теперь-то Вам, наверное, понятно, откуда произошло название функции MapViewOfFile
Проецируя на адресное пространство процесса представление файла, нужно сде лать двс вещи Во-первых, сообщить системе, какой байт файла данных считать в представлении первым Для этого предназначены параметры dwFileOffsetHigh и dwFile OffsetLow Поскольку Windows поддерживает файлы длиной до 16 экзабайтов, прихо дится определять смещение в файле как 64 разрядное число старшие 32 бита пере даются в параметре dwFileOffsetHigh, а младшие 32 бита — в параметре dwFileOffsetLow Заметьте, что смещение в файле должно быть кратно гранулярности выделения па мяти в данной системе (В настоящее время во всех реализациях Windows она состав ляет 64 Кб) О гранулярности выделения памяти см раздел "Системная информация" в ]лаве 14
Во-вторых, от Baс потребуется указать размер представления, т.e. сколько байтов файла данных должно быть спроецировано на адресное пространство Это равносиль но тому, как если бы Вы задали размер региона, резервируемого в адресном простран стве Размер указывается впараметре dwNumberOfBytesToMap Если этот параметр ра вен 0, система попытается спроецировать представление, начиная с указанного сме щения и до конца файла
WINDOWS 98
Windows 98, если MapViewOfFile не найдет регион, достаточно большой для размещения всего объекта "проекция файла", возвращается NULL — независи мо от того, какой размер представления был запрошен
WINDOWS 2000
B Windows 2000 функция MapViewOfFile ищет регион, достаточно большой для размещения запрошенного представления, не обращая внимания на размер самого объекта "проекция файла".
Если при вызове MapViewOfFile указан флаг FILE_MAP_COPY, система передает физическую память из страничного файла. Размер передаваемого пространства оп ределяется параметром dwNumberOfBytesToMap. Пока Вы лишь считываете данные из представления файла, страницы, переданные из страничного файла, пе используют ся, Но стоит какому-нибудь потоку в Вашем процессе совершить попытку записи по адресу, попадающему в границы представления файла, как система тут же берет из страничного файла одну из переданных страниц, копирует на нее исходные данные и проецирует ее на адресное пространство процесса.
Так что с этого момента пото ки Вашего процесса начинают обращаться к локальной копии данных и теряют дос туп к исходным данным.
Создав копию исходной страницы, система меняет ее атрибут защиты с PAGE_WRI TECOPY на PAGE_READWRITE. Рассмотрим пример:
// открываем файл, который мы собираемся спроецировать
HANDLE hFile = CreaTeFile(pszFileName, GENERIC_READ | GENERIC_WRITE, 0, NULL, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
// создаем для файла объект "проекция файла"
HANDLE hFileMapping = CreateFileMapping(hFile, NULL, PAGE_WRITECOPY, 0, 0, NULL);
// Проецируем представление файла с атрибутом "копирование при записи";
// система передаст столько физической памяти из сфаничного файла,
// сколько нужно для размещения всего файла. Первоначально все страницы
// в представлении получат атрибут PAGE_WRITECOPY.
PBYTE pbFile = (PBYTE) MapViewOfFile(hFileMapping, FILE_MAP_COPY, 0, 0, 0);
// считываем байт из представления файла
BYTE bSomeByte = pbFile[0];
// при чтении система не трогает страницы, переданные из страничного файла;
// страница сохраняет свой атрибут PAGE_WRITECOPY
// записываем байт в представление файла
pbFile[0] = 0;
// При первой записи система берет страницу, переданную из страничного файла,
// копирует исходное содержимое страницы, расположенной по запрашиваемому адресу
// в памяти, и проецирует новую страницу (копию) на адресное пространство процесса.
// Новая страница получает атрибут PAGE_READWRITE.
// записываем еще один байт в представление файла
pbFile[1] = 0;
// поскольку теперь байт располагается на странице с атрибутом PAGE_RFADWRITE,
// система просто записывает его на эту страницу (она связана со страничным файлом)
// закончив работу с представлением проецируемого файла, прекращаем проецирование;
// функция UnmapViewOfFile обсуждается в следующем разделе
UnmapViewOfFile(pbFile);
// вся физическая память, взятая из страничного файпа, возвращается системе;
// все, что было записано на эти страницы, теряется
// "уходя, гасите свет"
CloseHandle(hFileMapping);
CloseHandle(hFile);
WINDOWS 98
Как уже упоминалось, Windows 98 сначала передаст проецируемому файлу физическую память из страничного файла Однако запись модифицированных страниц в страничный файл происходит только при необходимости.
Этап 4: отключение файла данных от адресного пространства процесса
Когда необходимость в данных файла (спроецированного на регион адресного про странства процесса) отпадет, освободите регион вызовом:
BOOL UnmapViewOfFile(PVOID pvBaseAddress);
Ее единственный параметр, pvBaseAddress, указывает базовый адрес возвращаемо го системе региона. Он должен совпадать со значением, полученным после вызова MapViewOfFile. Вы обязаны вызывать функцию UnmapViewOfFile. Если Вы не сделаете этoro, регион не освободится до завершения Вашего процесса. И еще: повторный вызов MapVietvOfFile приводит к резервированию нового региона в пределах адрес ного пространства процесса, но ранее выделенные регионы не освобождаются.
Для повышения производительности при работе с представлением файла систе ма буферизует страницы данных в файле и не обновляет немедленно дисковый об раз файла. При необходимости можно заставить систему записать измененные дан ные (все или частично) в дисковый образ файла, вызвав функцию FlushViewOfFile
BOOL FlushViewOfFile( PVOID pvAddress, SIZE_T dwNuuiberOfBytesToFlush);
Ее первый параметр принимает адрес байта, который содержится в границах пред ставления файла, проецируемого в память. Переданный адрес округляется до значе ния, кратного размеру страниц, Второй параметр определяет количество байтов, ко торые надо записать в дисковый образ файла. Если FlusbViewOfFile вызывается в от сутствие измененных данных, она просто возвращает управление.
В случае проецируемых файлов, физическая память которых расположена на се тевом диске, FlushViewOfFile гарантирует, что файловые данные будут перекачаны с рабочей станции. Но она не гарантирует, что сервер, обеспечивающий доступ к это му файлу, запишет данные на удаленный диск, так как он может просто кэшировать их. Для подстраховки при создании объекта "проекция файла" и последующем про ецировании его представления используйте флаг FILE_FLAG_WRITE_THROUGH. При открытии файла с этим флагом функция FlushViewOfFile вернет управление только после сохранения на диске сервера всех файловых данных.
У функции UnmapViewOfFile есть одна особенность. Если первоначально представ ление было спроецировано с флагом FILE_MAP_COPY, любые изменения, внесенные Вами в файловые данные, на самом деле производятся над копией этих данных, хра нящихся в страничном файле. Вызванной в этом случае функции UnmapViewOfFile нечего обновлять в дисковом файле, и она просто инициирует возврат системе стра ниц физической памяти, выделенных из страничного файла. Все изменения в данных на этих страницах теряются.
Поэтому о сохранении измененных данных придется заботиться самостоятель но. Например, для уже спроецированного файла можно создать еще один объект "про
екция файла" с атрибутом PAGE_READWRITE и спроецировать его представление на адресное пространство процесса с флагом FILE_MAP_WRITE. Затем просмотреть пер вое представление, отыскивая страницы с атрибутом PAGE_READWRITE. Найдя стра ницу с таким атрибутом. Вы анализируете ее содержимое и решаете: записывать ее или нет Если обновлять файл не нужно, Вы продолжаете просмотр страниц. А для сохранения страницы с измененными данными достаточно вызвать MoveMemory и скопировать страницу из первого представления файля во второе. Поскольку второе представление создано с атрибутом PAGE_READWRITE, функция MoveMemory обновит содержимое дискового файла. Так что этот метод вполне пригоден для анализа изме нений и сохранения их в файле.
WINDOWS 98
Windows 98 нс поддерживает атрибут защиты "копирование при записи", по этому при просмотре первого представления файла, проецируемого в память, Вы не сможете проверить страницы по флагу PAGE_READWRITE Вам придется разработать свой метод.
Этап1: создание или открытие объекта ядра "файл"
Для этого Вы должны применять только функцию CreateFile
HANDLE CreateFile( PCSTR pszFileName, DWORD dwDesiredAccess, DWORD dwShareMode, PSECURITY_AIIRIBUTES psa, DWORD dwCreationDisposition, DWORD dwFlagsAndAttribules, HANDLE hTemplateFile);
Как видите, у функции CrealeFile довольно много параметров. Здесь я сосредото чусь только на первых трех: pszFileName, dwDesiredAccess и dwSbareMode.
Как Вы, наверное, догадались, первый параметр, pszFileName, идентифицирует имя создаваемого или открываемого файла (при необходимости вместе с путем). Второй параметр, dwDesiredAccess, указывает способ доступа к содержимому файла. Здесь за дастся одно из четырех значений, показанных в таблице ниже.
|
Значение |
Описание | ||
|
0 |
Содержимое файла нельзя считывать или записывать, указывайте это значение, если Вы хотите всею лишь получить афибуты файла | ||
|
GENERIC _READ |
Чтение файла разрешено | ||
|
GENERIC_WRITE |
Запись в файл разрешена | ||
|
GENERIC_READ | ENERIC_WRITE |
Разрешено и то и другое |
Создавая или открывая файл данных с намерением использовать его в качестве проецируемого в память, можно установить либо флаг GENERIC_READ (только для чтения), либо комбинированный флаг GENERIC_READ | GENУRIC_WRITE (чтение/ча пись)
Третий параметр, dwShareMode, указывает тип совместного доступа к данному файлу(см следующуютаблицу)
|
Значение |
Описание | ||
|
0 |
Другие попытки открыть файл закончатся неудачно | ||
|
FILE_SHARE_REAU |
Попытка постороннего процесса открыть файл с флагом GENERIC_WRITE не удается | ||
|
FILb_SHARF_WRlTE |
Попьлка постороннего процесса открыть файл с флагом GENERIC_READ не удается | ||
|
FILE SHARE RFAD | FILE_SHARE_WRTTE |
Посторонний процесс может открывать файл без ограничений |
Создав или открыв указанный файл, CreateFile возвращает его описатель, в ином случае — идентификатор INVALID_HANDLE_VALUE
NOTE:
Большинство функций Windows, возвращающих те или иные описатели, при неудачном вызове дает NULL Ho CreateFile — исключение и в таких случаях возвращает идентификатор INVALID_HANDIF_VALUE, определенный как ((HANDLE) -1)
Этапы 5 и 6: закрытие объектов "проекция файла" и "файл"
Закончив работу с любым открытым Вами объектом ядра, Вы должны его закрыть, иначе в процессе начнется утечка ресурсов. Конечно, по завершении процесса сис тема автоматически закроет объекты, оставленные открытыми Но, если процесс по работает еще какое-то время, может накопиться слишком много незакрытых описа телей. Поэтому старайтесь придерживаться правил хорошего тона и пишите код так, чтобы открытые объекты всегда закрывались, как только они станут не нужны. Для закрытия объектов "проекция файла" и "файл" дважды вызовите функцию CloseHandle. Рассмотрим это подробнее на фрагменте псевдокода.
HANDLE hFile = CreateFile(...);
HANDLE hFileMapping = CreateFileMapping(hFile,...);
PVOID pvFilfi = MapViewOfFile(hFileMapping, );
// работаем с файлом, спроецированным в память
UnmapViewOfFile(pvFile);
CloseHandle(hFileMapping);
CloseHandle(hFile);
Этот фрагмент иллюстрирует стандартный метод управления проецируемыми файлами. Но он не отражает того факта, что при вызове MapViewOfFile система уве личивает счетчики числа пользователей ибьектов "файл" и "проекция файла". Этот побочный эффект весьма важен, так как позволяет переписать показанный выше фрагмент кода следующим образом:
HANDLE hFile = CreateFile( . );
HANDLE hFileMapping = CreateFileMapping(hFile, );
CloseHandle(hFile);
PVOID pvFile = MapViewOfFile(hFileMapping,...);
CloseHandle(hFileMapping);
// работаем с файлом, спроецированным в память
UnmapViewOfFile(pvFile);
При операциях с проецируемыми файлами обычно открывают файл, создают объект "проекция файла" и с его помощью проецируют представление файловых
данных на адресное пространство процесса. Поскольку система увеличивает внутрен ние счетчики объектов "файл" и "проекция файла", их можно закрыть в начале кода, тем самым исключив возможную утечку ресурсов.
Если Вы будете создавать из одного файла несколько объектов "проекция файла" или проецировать несколько представлений этого объекта, применить функцию CloseHandle в начале кода не удается — описатели еще понадобятся Вам для дополни тельных вызовов CreateFileMapping и MapViewOfFile
Как адресное пространство разбивается на разделы
Виртуальное адресное пространство каждого процесса разбивается на разделы. Их размер и назначение в какой-то мере зависят от конкретного ядра Windows (таблица 13-1)
Как видите, ядра 32- и 64-разрядной Windows 2000 создают разделы, почти одинаковые по назначению, но отличающиеся по размеру и расположению. Однако ядро Windows 98 формирует другие разделы. Давайте рассмотрим, как система использует каждый из этих разделов.
|
Раздел |
32-разрядная Windows 2000 (на х86 и Alpha) |
32-разрядная Windows 2000 (на х86 с ключом /3GB) |
64-разрядная Windows 2000 (на Alpha и А-64) |
Windows 98 | |||||
|
Для выявления |
0x00000000 |
0x00000000 |
0x00000000 00000000 |
0x00000000 | |||||
|
нулевых указателей |
0x0000FFFF |
0x0000FFFF |
0x00000000 0000FFFF |
0x00000FFF | |||||
|
Для совместимости с программами DOS и 16-разрядной Windows |
Hет |
Нет |
Нет |
0x00001000 0x003FFFFF | |||||
|
Для кода и данных |
0x00010000 |
0x00010000 |
0x00000000 00010000 |
0x00400000 | |||||
|
пол ьзовател ьс кого режима |
0x7FFEFFFF |
0xBFFFFFFF |
0x000003FF FFFEFFFF |
0x7FFFFFFF | |||||
|
Закрытый, |
0x7FFF0000 |
0xBFFF0000 |
0x000003FF FFFF0000 |
Нет | |||||
|
размером 64 Кб |
0x7FFFFFFF |
0xBFFFFFFF |
0x000003FF FFFFFFFF | ||||||
|
Для общих MMF (файлов, проецируемых в память) |
Нет |
Нет |
Нет |
0x80000000 0xBFFFFFFF | |||||
|
Для кода и данных |
0x800000000 |
0xC0000000 |
0x00000400 00000000 |
0xC0000000 | |||||
|
режима ядра |
0xFFFFFFFF |
0xFFFFFFFF |
0xFFFFFFFF FFFFFFFF |
0xFFFFFFFF |
Таблица 13-1. Так адресное пространство процесса разбивается на разделы
NOTE:
Microsoft активно работает над 64-разрядной Windows 2000. На момент напиcания книги эта система все еще находилась в разработке. Информацию по 64разрядной Windows 2000 следует учитывать при проектировании и реализации текущих проектов Однако Вы должны понимать, что какие-то детали скорее всего изменятся к моменту выхода 64-разрядной Windows 2000. То же самое относится и к конкретным диапазонам разделов виртуального адресного пространства и размеру страниц памяти на процессорах IA-64 (64-разрядной архитектуры Intel).
Как писать программу с использованием Unicode
Microsoft разработала Windows API так, чтобы как можно меньше влиять на Ваш код. В самом деле, у Вас появилась возможность создать единственный файл с исходным кодом, компилируемый как с применением Unicode, так и без него, — достаточно определить два макроса (UNICODE и _UNICODE), которые отвечают за нужные изменения.
Как система упорядочивает вызовы DIIMain
Система упорядочивает вызовы функции DllMain. Чтобы понять, что я имею в виду, рассмотрим следующий сценарий Процесс А имеет два потока: А и В. На его адресное пространство проецируется DLL-модуль SomeDLL.dll. Оба потока собираются вызвать CreateThread, чтобы создать еще два потока: С и D.
Когда поток А вызывает для создания потока С функцию CreateThread, система обращается к DllMain из SomeDLL.dll со значением DLL_THREAD_АТТАСН. Пока поток С исполняет код DllMain, поток В вызывает CreateThread для создания потока D. Системе нужно вновь обратиться к DllMain со значением DLL_THREAD_ATTACH, и на этот раз код функции должен выполнять поток D. Но система упорядочивает вызовы DllMain. и поэтому приостановит выполнение потока D, пока поток С не завершит обработку кода DllMain и не выйдет из этой функции.
Закончив выполнение DllMain, поток С может начать выполнение своей функции потока. Теперь система возобновляет поток D и позволяет ему выполнить код DllMain, при возврате из которой он начнет обработку собственной функции потока
Обычно никто и не задумывается над тем, что вызовы DllMain упорядочиваются. Но я завел об этом разговор потому, что один мой коллега как-то раз написал код, в котором была ошибка, связанная именно с упорядочиванием вызовов DllMain, Его код выглядел примерно так:
BOOL WINAPI DllMain(HINSTANCE hinstDll, DWORD fdwReason, PVOID fImpLoad)
{
HANDLE hThread; DWORD dwThreadId;
switch (fdwReason)
{
case DLL_PROCESS_ATTACH:
// DLL проецируется на адресное пространство процесса
// создаем поток для выполнения какой-то работы
hThread = CreateThread(NULL, 0, SomeFunction, NULL, 0, &dwThreadId);
// задерживаем наш поток до завершения нового потока
WaitForSingleObject(hThread, INFINITE);
// доступ к новому потоку больше не нужен
CloseHandle(hThread);
break;
case DLL_THREAD_ATTACH:
// создается еще один поток
break;
case DLL_THREAD_DETACH:
// поток завершается корректно
break;
case DLL_PROCESS_DETACH:
// DLL выгружается из адресного пространства процесса
break;
}
return(TRUE);
}
Нашли "жучка"? Мы- то его искали несколько часов. Когда DllMain получаст уведомление DLL_PROCESS_ATTACH, создается новый поток. Системе нужно вновь вызвать эту же DllMain со значением DLL_THREAD_ATTACH Но выполнение нового потока приостанавливается ведь поток, из-за которого в DllMain было отправлено уведомление DLL_PROCFSS_ATTACH, свою работу еще не закончил. Проблема кроется в вызове WaitForSingleObject. Она приостанавливает выполнение текущего потока до тех пор, пока не завершится новый. Однако у нового потока нет ни единою шанса не только на завершение, но и на выполнение хоть какого-нибудь кода — он приостановлен в ожидании того, когда текущий поток выйдет из DllMain Вот Вам и взаимная блокировка — выполнение обоих потоков задержано навеки!
Впервые начав размышлять над этой проблемой, я обнаружил функцию DisableThreadLibraryCalls:
BOOl DisableThreadLibraryCalls(HINSTANCE hinstDll);
Вызывая ее, Вы сообщаете системе, что уведомления DLL_THREAD_ATTACH и DLL_ THREAD_DETACH не должны посылаться DllMain той библиотеки, которая указана в вызове Мне показалось логичным, что взаимной блокировки не будет, если система не стаиет посылать DLL уведомления. Но, проверив свое решение (см. ниже), я убедился, что это не выход.
BOOL WINAPI DllMain(HINSTANCE hinstDll, DWORD fdwReason, PVOID fImpLoad)
{
HANDLE hThread; DWORD dwThreadId;
switch (fdwReason)
{
case DLL_PROCESS_ATTACH.
// DLL проецируется на адресное пространство процесса
// предотвращаем вызов DllMain при создании
// или завершении потока
DisableThreadLibraryCalls(hinstDll);
// создаем поток для выполнения какой-то работы
hThread = CreateThread(NULL, 0, SomeFunction, NULL, 0, &dwThreadId);
// задерживаем наш поток до завершения нового потока
WaitForSingleObject(hThread, INFINITE);
// доступ к новому потоку больше не нужен
CloseHandle(hThread);
break;
саsе DLL_THREAD_ATTACH:
// создается сщс один поток
break;
case DLL_THREAD_DETACH:
// поток завершается корректно
break;
case DLL_PROCESS_DETACH:
// DLL выгружается из адресного пространства процесса
break;
}
return TRUE;
}
Потом я понял, в чем лело Создавая процесс, система создает и объект-мьютекс. У каждого процесса свой объект-мьютекс — он не разделяется между несколькими процессами. Его назначение — синхронизация всех потоков процесса при вызове ими функций DllMain из DLL, спроецированных на адресное пространство данного процесса.
Когда вызывается CreateThread, стстема создает сначала объект ядра "поток" и стек потока, затем обращается к WaitForSingleObject, передавая ей описатель объекта-мьютекса данного процесса. Как только поток захватит этот мьютекс, система заставит его вызвать DllMain из каждой DLL со значением DLL_THREAD_ATTACH. И лишь тогда система вызовет ReleaseMutex, чтобы освободить объект-мьютекс Вот из-за того, что система работает именно так, дополнительный вызов DisableThreadLibraryCalls и не предотвращает взаимной блокировки потоков. Единственное, что я смог придумать, — переделать эту часть исходного кода так, чтобы ни одна DllMain не вызывала WaitForSingleObject
Как узнать о себе
Потоки часто обращаются к Windows-функциям, которые меняют срсду выполнения. Например, потоку может понадобиться изменить свой приоритет или приоритет процесса. (Приоритеты рассматриваются в главе 7.) И поскольку это не редкость, когда поток модифицирует среду (собственную или процесса), в Windows предусмотрены функции, позволяющие легко ссылаться на объекты ядра текущего процесса и потока:
HANDLE GetCurrentProcess();
HANDLE GetCurrentThread();
Обе эти функции возвращают псевдоописатсль объекта ядра "процесс" или "поток". Они не создают новые описатели в таблице описателей, которая принадлежит вызывающему процессу, и не влияют на счетчики числа пользователей объектов ядра "процесс" и "поток". Поэтому, если вызвать CloseHandle и передать ей псевдоописатель, она проигнорирует вызов и просто вернет FALSE.
Псевдоописатели можно использовать при вызове функций, которым нужен описатель процесса. Так, поток может запросить все временные показатели своего процесса, вызвав GetProcessTimes:
FILETIME ftCreationTime, ftExitTime, ftKernelTime, ftUserTime;
GetProcessTimes(GetCurrentProcess(), &ftCreationTime, &ftExirTime, &ftKernelTime, &ftUserTime);
Аналогичным образом поток может выяснить собственные временные показатели, вызвав GetThreadTimes:
FILETIME ftCreationTime, ftExitTime, ftKernelTime, ftUserTime;
GetThreadTimes(GetCurrentThread(), &ftCreationTime, &ftExitTime, &ftKernelTime, &ftUserTime);
Некоторые Windows-функции позволяют указывать конкретный процесс или поток no его уникальному в рамках всей системы идентификатору. Вот функции, с помощью которых поток может выяснить такой идентификатор — собственный или своего процесса:
DWORD GetCurrentProcessId();
DWORD GelCurrentThreadId();
По сравнению с функциями, которые возвращают псевдоописатели, эти функции, как правило, не столь полезны, но когда-то и они могут пригодиться.
Как Windows манипулирует с ANSI/Unicode-символами и строками
WINDOWS 98
Windows 98 поддерживает классы и процедуры окон только в формате ANSI
Регисрируя новый класс окна, Вы должны сообщить системе адрес оконной проце дуры, которая отвечает за обработку сообщений для этого класса. В некоторых сооб щениях (например, WM_SETTEXT) параметр lParam является указателем на строку. Для корректной обработки сообщения система должна заранее знать, в каком формате оконная процедура принимает строки — ANSI или Unicode.
Выбирая конкретную функцию для регистрации класса окна, Вы сообщаете сис теме формат, приемлемый для Вашей оконной процедуры Если Вы создаете структу ру WNDCLASS и вызываете RegisterClassA, система считает, что процедура ожидает исключительно ANSI-строки и символы А регистрация класса окна через Rеgister ClassW заставит систему полагать, что процедуре нужен Unicode. И, конечно же, в за висимости от того, определен ли UNICODE при компиляции модуля исходного кода, макрос RegisterClass будет раскрыт либо в RegisterClassA, либо в RegisterClassW
Располагая описателем окна, Вы можете выяснить, какой формат символов и строк требует оконная процедура Для этого вызовите функцию:
BOOL IsWindowUnicode(HWND hwnd);
Если оконная процедура ожидает передачи данных только в Unicode, эта функция возвращает TRUE, в ином случае — FALSE.
Если Вы сформировали ANSI-строку и посылаете сообщение WM_SETTEXT окну, чья процедура принимает только Unicode-строки, то система перед отсылкой сооб щения автоматически преобразует его в нужный формат. Так что необходимость в вызове lsWindowUnicode возникает нечасто
Система автоматически выполняет все преобразования и при создании подклас ca окна. Допустим, что для заполнения своего поля ввода оконная процедура ожида ет передачи символов и строк в Unicode Кроме того, где-то в программе Вы создаете поле ввода и подкласс оконной процедуры, вызывая
LONG_PTR SetWindowLongPtrA( HWND hwnd, int nlndex, LONG_PTR dwNewLong);
или
LONG_PTR SetWindowLongPtrW( HWND bwnd, int nIndGx, LONG_PTR dwNewLong);
При этом Вы передаете в параметре nlndex значение GOLP_WNDPROC, а в пара мегре dwNewLong — адрес своей процедуры полкласса.
Но что будет, если Ваша про цедура ожидает передачи символов и строк в формате ANSI? B принципе, это чрева то проблемами. Система определяет, как преобразовывать строки и символы в зави симости от функции, вызванной Вами для создания подкласса Используя SetWmdow LongPtrA, Вы сообщаете Windows, что новая оконная процедура (Вашего подкласса) принимает строки и символы только в ANSI. (Вызвав IsWindowUnicode после SetWin dowLongPtrA, Вы получили бы FALSE, так как новая процедура не принимает строки и символы в Unicode.)
Но теперь у нас новая проблема: как сделать так, чтобы исходная процедура полу чала символы и строки в своем формате? Для корректного преобразования системе нужно знать две вещи. Во-первых, текущий формат символов и строк. Эту информа цию мы предоставляем, вызывая одну из двух функций — CallWindowProcA или CalWin dowProcW
LRESULT CallWindowProcA( WNDPROC wndprcPrev, HWND hwnd, UINT uMsg, WPARAM wParam, LPARAM lParam);
LRESULT CallWindowProcW( WNDPROC wndprcPrev, HWND hwnd, UINT uMsg, WPARAM wParam, LPARAM lParam);
При передаче исходной оконной процедуре ANSI-строк процедура подкласса дол жна вызывать CalWindowProcA, а при передаче Unicode-строк — CallWtndowProcW
Второе, о чем должна знать система, — тип символов и строк, ожидаемый исход ной оконной процедурой Система получает эту информацию по адресу этой проце дуры. Когда Вы вызываете SetWindowLongPtrA или SetWindowIongPtrW, система прове ряет, создаете ли Вы ANSI-подкласс Unicode-процедуры окна или наоборот. Если при создании подкласса тип строк нс меняется, SetWindowLongPtr просто возвращает ад рес исходной процедуры. В ином случае SetWmdowLongPtr вместо этого адреса воз вращает описатель внутренней структуры данных.
Эта структура содержит адрес исходной оконной процедуры и значение, которое указывает на ожидаемый ею формат строк При вызове CallWindowProc система про веряет, что Вы передаете — адрес оконной пропедуры или описатель внутренней структуры данных. В первом случае система сразу обращается к исходной оконной процедуре, так как никаких преобразований не требуется, а во втором случае систе ма сначала преобразует символы и строки в соответствующую кодировку и только потом вызывает исходную оконную процедуру.
Кэш-линии
Если Вы хотите создать высокоэффективное приложение, работающее на многопроцессорных машинах, то просто обязаны уметь пользоваться кэш-линиями процессора (CPU cache lines). Когда процессору нужно считать из памяти один байт, он извлекает не только его, но и столько смежных байтов, сколько требуется для заполнения кэш-линии. Такие линии состоят из 32 или 64 байтов (в зависимости от типа процессора) и всегда выравниваются по границам, кратным 32 или 64 байтам. Кэш-линии предназначены для повышения быстродействия процессора. Обычно приложение работает с набором смежных байтов, и, если эти байты уже находятся в кэше, процессору не приходится снова обращаться к шине памяти, что обеспечивает существенную экономию времени.
Однако кэш-линии сильно усложняют обновление памяти в многопроцессорной среде. Вот небольшой пример:
Процессор 1 считывает байт, извлекая этот и смежные байты в свою кэш-линию. Процессор 2 считывает тот же байт, а значит, и тот же набор байтов, что и процессор 1; извлеченные байты помещаются в кэш-линию процессора 2. Процессор 1 модифицирует байт памяти, и этот байт записывается в его кэш-линию. Но эти изменения еще не записаны в оперативную память. Процессор 2 повторно считывает тот же байт Поскольку он уже помещен в кэш-линию этого процессора, последний не обращается к памяти и, следова тельно, не "видит" новое значение данного байта.
Такой сценарий был бы настоящей катастрофой. Но разработчики чипов прекрасно осведомлены об этой проблеме и учитывают её при проектировании своих процессоров. В частности, когда один из процессоров модифицирует байты в своей кэш-линии, об этом оповещаются другие процессоры, и содержимое их кэш-линий объявляется недействительным. Таким образом, в примере, приведенном выше, после изменения байта процессором 1, кэш процессора 2 был бы объявлен недействительным. На этапе 4 процессор 1 должен сбросить содержимое своего кэша в оперативную память, а процессор 2 — повторно обратиться к памяти и вновь заполнить свою кэш-линию.
Как видите, кэш-линии, которые, как правило, увеличивают быстродействие процессора, в многопроцессорных машинах могут стать причиной снижения производительности.
Все это означает, что Вы должны группировать данные своего приложения в блоки размером с кэш-линии и выравнивать их по тем же правилам, которые применяются к кэш-линиям. Ваша цель — добиться того, чтобы различные процессоры обращались к разным адресам памяти, отделенным друг от друга по крайней мере границей кэш-линии. Кроме того, Вы должны отделить данные "только для чтения" (или редко используемые данные) от данных "для чтения и записи". И еще Вам придется позаботиться о группировании тех блоков данных, обращение к которым происходит примерно в одно и то же время.
Вот пример плохо продуманной структуры данных:
struct CUSTINFO
{
DWORD dwCustomerID;
// в основном "только для чтения1 int nBalanceDue,
// для чтения и записи char szName[100],
// в основном "только для чтения" FILETIME ttLastOrderDate;
// для чтения и записи
};
А это усовершенствованная версия той же структуры.
// определяем размер кэш-линии используемого процессора
#ifdef _X86_
#define CACHE_ALIGN 32
#endif
#ifdef _ALPHA_
#define CACHE_ALIGN 64
#endif
#ifdef _IA64_
#define CACHE_ALIGN ??
#endif
#define CACHE_PAD(Name, BytesSoFar) BYTE Name[CACHE_ALIGN - ((BytesSoFar) % CACHE_ALIGN)]
struct CUSTINFO
{
DWORD dwCustomerID;
// в осноеном "только для чтения"
char szName[100];
// в основном "только для чтения"
// принудительно помещаем следующие элементы в другую кэш-линию
CACHE_PAD(bPad1, sizeof(DWORD) + 100);
int nBalanceDue;
// для чтения и записи
FILETIME ftLastOrderDate;
// для чтения и записи
// принудительно помещаем следующую структуру в другую кэш-линию
CACHE_PAD(bPad2, sizeof(int) + sizeof(FILETIME));
};
Макрос CACHE_ALIGN неплох, но не идеален. Проблема в том, что байтовый размер каждого элемента придется вводить в макрос вручную, а при добавлении, перемещении или удалении элемента структуры — еще и модифицировать вызов макроса CACHE_PAD.В следующих версиях компилятор Microsoft C/C++ будет поддерживать новый синтаксис, упрощающий выравнивание элементов структур. Это будет что-то вроде __declepec(align(32)).
NOTE:
Лучше всего, когда данные используются единственным потоком (самый про стой способ добиться этого — применять параметры функций и локальные переменные) или одним процессором (это реализуется привязкой потока к определенному процессору). Если Бы пойдете по такому пути, можете вообще забыть о проблемах, связанных с кэш-линиями.
Кое-что о внутреннем устройстве потока
Я уже объяснил Вам, как реализовать функцию потока и как заставить систему создать поток, который выполнит эту функцию. Теперь мы попробуем разобраться, как система справляется с данной задачей.
На рис. 6-1 показано, что именно должна сделать система, чтобы создать и инициализировать поток. Давайте приглядимся к этой схеме повнимательнее. Вызов CreateThread заставляет систему создать объект ядра "поток". При этом счетчику числа его пользователей присваивается начальное значение, равное 2. (Объект ядра "поток" уничтожается только после того, как прекращается выполнение потока и закрывается описатель, возвращенный функцией CreateThread). Также инициализируются другие свойства этого объекта счетчик числа простоев (suspension count) получает значение 1, а код завершения — значение STILL_ACTIVE (0x103). И, наконец, объект переводится в состояние "занято".
Создав объект ядра "поток", система выделяет стеку потока память из адресного пространства процесса и записывает в его самую верхнюю часть два значения. (Стеки потоков всегда строятся от старших адресов памяти к младшим) Первое из них является значением параметра pvParam, переданного Вами функции CreateThread, а второе — это содержимое параметра pfnStartAddr, который Вы тоже передаете в Create Thread.
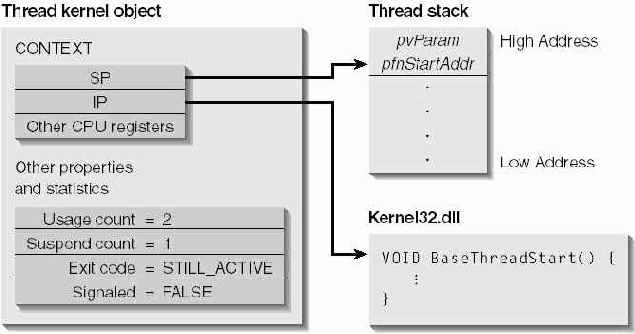
Рис. 6-1. Так создается и инициализируется поток
У каждого потока собсвенный набор регистров процессора, называемый контекстом потока. Контекст отражает состояние регистров процессора на момент последнего исполнения потока и записывается в структуру CONTEXT (она определена в заголовочном файле WinNT.h). Эта структура содержится в объекте ядра "поток".
Указатель команд (IP) и указатель стека (SP) — два самых важных регистра в контексте потока. Вспомните: потоки выполняются в контексте процесса. Соответственно эти регистры всегда указывают на адреса памяти в адресном пространстве процесса. Когда система инициализирует объект ядра "поток", указателю стека в структуре CONTEXT присваивается тот адрес, по которому в стек потока было записано значение pfnStartAddr, а указателю команд — адрес недокументированной (и неэкспортируемой) функции BaseThreadStart.
Эта функция содержится в модуле Kernel32.dll, где, кстати, реализована и функция CreateTbread.
Вот главное, что делает BaseThreadStart:
VOID BaseThreadStart(PTHREAD_START_ROUTINE pfnStartAddr, PVOID pvParam)
{
__try
{
ExitThread((pfnStartAddr)(pvParam));
}
_except(UnhandledExceptionFilter(GetExceptionInformation()))
{
ExitProcess(GetExceptionCode());
}
// ПРИМЕЧАНИЕ, мы никогда не попадем сюда
}
После инициализации потока система проверяет, был ли передан функции CreateThread флаг CREATE_SUSPENDED. Если нет, система обнуляет его счетчик числа простоев, и потоку может быть выделено процессорное время. Далее система загружает в регистры процессора значения, сохраненные в контексте потока. С этого момента поток может выполнять код и манипулировать данными в адресном пространстве своего процесса.
Поскольку указатель команд нового потока установлен на BaseThreadStart, именно с этой функции и начнется выполнение потока. Глядя на ее прототип, можно подумать, будто BaseThreadStart передаются два параметра, а значит, она вызывается из какой-то другой функции, но это не так. Новый поток просто начинает с нее свою работу. BaseThreadStart получает доступ к двум параметрам, которые появляются у нее потому, что операционная система записывает соответствующие значения в стек потока (а через него параметры как раз и передаются функциям). Правда, на некоторых аппаратных платформах параметры передаются не через стек, а с использованием определенных регистров процессора. Поэтому на таких аппаратных платформах система — прежде чем разрешить потоку выполнение функции BaseThreadStart — инициализирует нужные регистры процессора.
Когда новый поток выполняет BaseThreadStart, происходит следующее.
Ваша функция потока включается во фрейм структурной обработки исключений (далее для краткости — SEH-фрейм), благодаря чему любое исключение, если оно происходит в момент выполнения Вашего потока, получает хоть какую-то обработку, предлагаемую системой по умолчанию. Подробнее о структурной обработке исключений см.
главы 23, 24 и 25. Система обращается к Вашей функции потока, передавая ей параметр pvParam, который Вы ранее передали функции CreateTbread. Когда Ваша функция потока возвращает управление, BaseThreadStart вspывает ExitThread, передавая ей значение, возвращенное Вашей функцией. Счетчик числа пользователей объекта ядра "поток" уменьшается на 1, и выполнение потока прекращается.
Если Ваш поток вызывает необрабатываемое им исключение, его обрабатывает SEH-фрейм, построенный функцией BaseThreadStart. Обычно в результате этого появляется окно с каким-нибудь сообщением, и, когда пользователь закрывает его, BaseThreadStart вызывает ExitProcess и завершает весь процесс, а не только тот ноток, в котором произошло исключение.
Обратите внимание, что из BaseThreadStart поток вызывает либо ExitThread, либо ExitProcess. А это означает, что поток никогда не выходит из данной функции; он все гда уничтожается внутри нее. Вот почему BaseThreadStart нет возвращаемого значения — она просто ничего не возвращает.
Кстати, именно благодаря BaseThreadStartВаша функция потока получает возможность вернуть управление по окончании своей работы. BaseThteadSlart, вызывая функцию потока, заталкивает в стек свой адрес возврата и тем самым сообщает ей, куда надо вернуться. Но сама BaseThreadStart не возвращает управление. Иначе возникло бы нарушение доступа, так как в стеке потока нет ее адреса возврата.
При инициализации первичного потока его указатель команд устанавливается на другую недокументированную функцию — BaseProcessStart. Она почти идентична BaseThreadStart и выглядит примерно так:
VOID BaseProcessStart(PPROCESS_START_BOUTINE pfnStartAddr)
{
__try
{
ExitThread((pfnStartAdd r)());
}
_except(UnhandledFxceptionFilter(GetExceptionInformation()))
{
ExitProcess(GettxceptionCode());
}
// ПРИМЕЧАНИЕ, мы никогда не попадем сюда
}
Единственное различие между этими функциями в отсутствии ссылки на параметр pvParam. Функция BaseProcessStart обращается к стартовому коду библиотеки С/С++, который выполняет необходимую инициализацию, а затем вызывает Вaшy входную функцию main, wmain, WinMain или wWinMain.Когда входная функция возвращает управление, стартовый код библиотеки С/С++ вызываст ExitProcess. Поэтому первичный поток приложения, написанного на С/С++, никогда не возвращается в Base ProcessStart.
Когда все потоки процесса уходят
В такой ситуации (а она может возникнуть, если все потоки вызвали ExitTbread или их закрыли вызовом TermirmteTbread) операционная система больше не считает нуж ным "содержать" адресное пространство данного процесса. Обнаружив, что в процес се не исполняется ни один поток, она немедленно завершает его. При этом код за вершения процесса приравнивается коду завершения последнего потока.
Командная строка процесса
При создании новому процессу передается командная строка, которая почти никогда не бывает пустой — как минимум, она содержит имя исполняемого файла, использованного при создании этого процесса. Однако, как Вы увидите ниже (при обсуждении функции CreateProcess), возможны случаи, когда процесс получает командную строку, состоящую из единственного символа — нуля, завершающего строку. В момент запуска приложения стартовый код из библиотеки С/С++ считывает командную строку процесса, пропускает имя исполняемого файла и заносит в параметр pszCmdLine функции (w)WinMain указатель на оставшуюся часть командной строки.
Параметр pszCmdLine всегда указывает на ANSI-строку. Но, заменив WinMain на wWinMain, Вы получите доступ к Unicode-версии командной строки для своего про цесса
Программа может анализировать и интерпретировать командную строку как угодно. Поскольку pszCrndLine относится к типу PSTR, а не PCSTR, не стесняйтесь и записывайте строку прямо в буфер, на который указывает этот параметр, но ни при каких условиях не переступайте границу буфера. Лично я всегда рассматриваю этот буфер как "только для чтений". Если в командную строку нужно внести изменения, я сначала копирую буфер, содержащий командную строку, в локальный буфер (в своей программе), который затем и модифицирую.
Указатель на полную командную строку процесса можно получить и вызовом функции GetCommandLine.
PTSTR GetCommandLine();
Она возвращает указатель на буфер, содержащий полную командную строку, включая полное имя (вместе с путем) исполняемого файла.
Во многих приложениях безусловно удобнее использовать командную строку, предварительно разбитую на отдельные компоненты, доступ к которым приложение может получить через глобальные переменные _argc и _argv (или _wargu). Функция CommandLineToArgvW расщепляет Unicode-строку на отдельные компоненты:
PWSTR CommandLineToArgvW( PWSTR pszCmdLine, int pNumArgs);
Буква W в конце имени этой функции намекает на "широкие" (wide) символы и подсказывает, что функция существует только в Unicode-версии. Параметр pszCmdLine указывает на командную строку Его обычно получают предварительным вызовом GetCommandLineW. Параметр pNumArgs — это адрес целочисленной переменной, в которой задается количество аргументов в командной строке. Функция Command LineToArgvW возвращает адрес массива указателей на Unicode-строки.
CommandLineToArgvW выделает нужную память автоматически. Большинство при ложений не освобождает эту память, полагаясь на операционную систему, которая проводит очистку ресурсов по завершении процесса И такой подход вполне прием лем. Нo если Вы хотите сами освободить эту память, сделайте так:
int pNumArgs;
PWSTR *ppArgv = CommandLineToArgvW(GetCommandLineW(), &pNumArgs);
// используйте эти аргументы if (*ppArgv[1] == L x ) {
// освободите блок памяти HeapFree(GetProcessHeap() 0 ppArgv);
Критические секции
Критическая секция (critical section) — это небольшой участок кода, требующий монопольного доступа к каким-то общим данным. Она позволяет сделать так, чтобы единовременно только один поток получал доступ к определенному ресурсу. Естественно, система может в любой момент вытеснить Ваш поток и подключить к процессору другой, но ни один из потоков, которым нужен занятый Вами ресурс, не получит процессорное время до тех пор, пока Ваш поток не выйдет за границы критической секции.
Вот пример кода, который демонстрирует, что может произойти без критической секции:
const int MAX_TIMES = 1000,
int g_nIndex - 0,
DWORD g_dwTimes[MAX_TIMES];
DWORD WINAPI FirstThread(PVOID pvParam)
{
while (g_nIndex < MAX_TIMES)
{
g_dwTimes[g__nIndex] = GetTickCount();
g_nIndex++;
}
return(0),
}
DWORD WINAPI SecondThread(PVOID pvParam)
{
while Cg_nIndex < MAX_TIMES)
{
g_nIndex++;
g_dwTimes[g_nIndex - 1] = GetTickCount();
}
return(0);
}
Здесь предполагается, что функции обоих потоков дают одинаковый результат, хоть они и закодированы с небольшими различиями. Если бы исполнялась только функция FirstThread, она заполнила бы массив g_dwTimes набором чисел с возрастающими значениями. Это верно и в отношении SecondThread - если бы она тоже исполнялась независимо. В идеале обе функции даже при одновременном выполнении должны бы по-прежнему заполнять массив тем же набором чисел. Но в нашем коде возникает проблема: масив g_dwTimes не будет заполнен, как надо, потому что функции обоих потоков одновременно обращаются к одним и тем же глобальным переменным. Вот как это может произойти.
Допустим, мы только что начали исполнение обоих потоков в системе с одним процессором. Первым включился в работу второй поток, т e функция SecondThread (что вполне вероятно), и только она успела увеличить счетчик g_nIndex 1, как система вытеснила ее поток и перешла к исполнению FirstThread. Та заносит в g_dwTimes[1] показания системного времени, и процессор вновь переключается на исполнение второго потока. SecondThread теперь присваивает элементу g_dwTtmes[1 - 1] новые показания системного времени Поскольку эта операция выполняется позже, новые показания, естественно, выше, чем записанные в элемент g_dwTimes[1] фyнкцией FirstThread.
Отметьте также, что сначала заполняется первый элемент массива и только потом нулевой. Таким образом, данные в массиве оказываются ошибочными.
Согласен, пример довольно надуманный, но, чтобы привести реалистичный, нужно минимум несколько страниц кода, Важно другое теперь Вы легко представите, что может произойти в действительности. Возьмем пример с управлением связанным списком объектов. Если доступ к связанному списку не синхронизирован, один поток может добавить элемент в список в тот момент, когда другой поток пытается найти в нем какой-то элемент. Ситуация станет еще более угрожающей, если оба потока одновременно добавят в список новые элементы. Так что, используя критические секции, можно и нужно координировать доступ потоков к структурам данных.
Теперь, когда Вы видите все "подводные камни", попробуем исправить этот фрагмент кода с помощью критической секции:
const int MAX_TIMES = 1000;
int g_nIndex = 0;
DWORD g_dwTimes[MAX_TIMES];
CRITICAL_SECTION g_cs;
DWORD WINAPI FirstThread(PVOID pvParam)
{
for (BOOL fContinue = TRUE; fContinue; )
{
EnterCriticalSection(&g_cs);
if (g_nIndex < MAX_TIMES)
{
g_dwTimes[g_nlndex] = GetTickCount();
g_nIndex++;
}
else
fContinue = FALSE;
LeaveCriticalSection(&g_cs);
}
return(0);
}
DWORD WINAPI SecondThread(PVOID pvParam)
{
for (BOOL fContinue = TRUE; fContinue; )
{
EnterCriticalSection(&g_cs);
if (g__nIndex < MAX_TIMES)
{
g_nIndex++;
g_dwTimes[g_nIndex - 1] = GetTickCount();
}
else
fContinue = FALSE;
LeaveCriticalSecLion(&g_cs);
}
return(0);
}
Я создал экземпляр структуры данных CRITICAL_SECTION — g_cs, а потом "обернул" весь код, работающий с разделяемым ресурсом (в нашем примере это строки с g_nIndex и g_dwTimes), вызовами EnterCriticalSection и LeaveCriticalSection. Заметьте, что при вызовах этих функций я передаю адрес g_cs.
Запомните несколько важных вещей. Если у Вас есть ресурс, разделяемый несколькими потоками, Вы должны создать экземпляр структуры CRITICAL_SECTION.
Так как я пишу эти строки в самолете, позвольте провести следующую аналогию. Структура CRITICAL_SECTION похожа на туалетную кабинку в самолете, а данные, которые нужно защитить, — на унитаз. Туалетная кабинка (критическая секция) в самолете очень маленькая, и единовременно в ней может находиться только один человек (поток), пользующийся унитазом (защищенным ресурсом).
Если у Вас есть ресурсы, всегда используемые вместе, Вы можете поместить их в одну кабинку — единственная структура CRITICAL_SECTION будет охранять их всех. Но если ресурсы не всегда используются вместе (например, потоки 1 и 2 работают с одним ресурсом, а потоки 1 и 3 — с другим), Вам придется создать им по отдельной кабинке, или структуре CRITICAL_SECTION.
Теперь в каждом участке кода, где Вы обращаетесь к разделяемому ресурсу, вызывайте EnterCriticaSection, передавая ей адрес структуры CRITICAL_SECTION, которая выделена для этого ресурса. Иными словами, поток, желая обратиться к ресурсу, должен сначала убедиться, нет ли на двери кабинки знака "занято". Структура CRITICAL_SECTION идентифицирует кабинку, в которую хочет войти поток, а функция EnterCriticalSection - тот инструмент, с помощью которого он узнает, свободна или занята кабинка. EnterCriticalSection допустит вызвавший ее поток в кабинку, если оп ределит, что та свободна. В ином случае (кабинка занята) EnterCriticalSection заставит его ждать, пока она не освободится.
Поток, покидая участок кода, где он работал с защищенным ресурсом, должен вызвать функцию LeaveCriticalSection. Тем самым он уведомляет систему о том, что кабинка с данным ресурсом освободилась. Если Вы забудете это сделать, система будет считать, что ресурс все еще занят, и не позволит обратиться к нему другим ждущим потокам, То есть Вы вышли из кабинки и оставили на двери знак "занято".
NOTE:
Самое сложное — запомнить, что любой участок кода, работающего с разде ляемым ресурсом, нужно заключить в вызовы функций EnterCrtticalSection и LeaveCriticalSection.
Если Вы забудете сделать это хотя бы в одном месте, ресурс может быть поврежден. Так, если в FirstThread убрать вызовы EnterCriticalSection и LeaveCriticalSection, содержимое переменных g_nIndex и g_dwTimes станет некорректным — даже несмотря на то что в SecondThread функции EnterCriticalSection и LeaveCriticalSection вызываются правильно.
Забыв вызвать эти функции, Вы уподобитесь человеку, который рвется в туалетную кабинку, не обращая внимания па то, есть в ней кто-нибудь или нет. Поток пробивает себе путь к ресурсу и берется им манипулировать. Как Вы прекрасно понимаете, стоит лишь одному потоку проявить такую "грубость", и Ваш ресурс станет кучкой бесполезных байтов.
Применяйте критические секции, если Вам не удается решить проблему синхронизации зз счет Interlocked-функций. Преимущество критических секций в том, что они просты в использовании и выполняются очень быстро, так как реализованы на основе Interlocked-функций. А главный недостаток — нельзя синхронизировать потоки в разных процессах. Однако в главе 10 я продемонстрирую Вам свой синхронизирующий объект, который я назвал оптексом. На его примере Вы увидите, как реализуются критические секции на уровне операционной системы и как этот объект работает с потоками разных процессов.
Критические секции и обработка ошибок
Вероятность того, что lnitializeCriticalSection потерпит неудачу, крайне мала, но все же существует. В свое время Microsoft не учла этого при разработке функции и определила ее возвращаемое значение как VOID, т. e. она ничего не возвращает. Однако функция может потерпеть неудачу, так как выделяет блок памяти для внутрисистемной отладочной информации. Если выделить память не удается, генерируется исключение STATUS_NO_MEMORY. Вы можете перехватить его, используя структурную об работку исключений (см. главы 23, 24 и 25).
Есть и другой, более простой способ решить эту проблему — перейти на новую функцию InitializeCriticalSectionAndSpinCount. Она, тоже выделяя блок памяти для отладочной информации, возвращает FALSE, если выделить память не удается.
В работе с критическими секциями может возникнуть еще одна проблема. Когда за доступ к критической секции конкурирует два и более потоков, она использует объект ядра "событие". (Я покажу, как работать с этим объектом при описании C++ класса COptex в главе 10.) Поскольку такая конкуренция маловероятна, система не создает объект ядра "событие" до тех пор, пока он действительно не потребуется. Это экономит массу системных ресурсов — в большинстве критических секций конкуренция потоков никогда не возникает.
Но если потоки все же будут конкурировать за критическую секцию в условиях нехватки памяти, система не сможет создать нужный объект ядра. И тогда EnterCriticalSection возбудит исключение EXCEPTION_INVALID_HANDLE. Большинство разработчиков просто игнорирует вероятность такой ошибки и не предусматривает для нее никакой обработки, поскольку она случается действительно очень редко. Но если Вы хотите заранее подготовиться к такой ситуации, у Вас есть две возможности.v
Первая — использовать структурную обработку исключений и перехватывать ошибку. При этом Вы либо отказываетесь от обращения к ресурсу, защищенному критической секцией, либо дожидаетесь появления свободной памяти, а затем повторяете вызов EnterCriticalSection.
Вторая возможность заключается в том, что Вы создаете критическую секцию вызовом InitializeCriticalSectionAndSpinCount, передавая параметр dwSpinGount с установленным старшим битом. Тогда функция создает объект "событие" и сопоставляет его с критической секцией. Если создать объект не удается, она возвращает FALSE, и это позволяет корректнее обрабатывать такие ситуации. Но успешно созданный объект ядра "событие" гарантирует Вам, что EnterCriticalSection выполнит свою задачу при любых обстоятельствах и никогда не вызовет исключение. (Всегда выделяя память под объекты ядра "событие", Вы неэкономно расходуете системные ресурсы. Поэтому делать так следует лишь в нескольких случаях, а именно: если программа может рухнуть из-за неудачного завершения функции EnterCriticatlSection, если Вы уверены в конкуренции потоков при обращении к критической секции или если программа будет работать в условиях нехватки памяти.)
Критические секции и спин-блокировка
Когда поток пытается войти в критическую секцию, занятую другим потоком, он не медленно приостанавливается. А это значит, что поток переходит из пользовательского режима в режим ядра (на что затрачивается около 1000 тактов процессора). Цена такого перехода чрезвычайно высока. На многопроцессорной машине поток, владеющий ресурсом, может выполняться на другом процессоре и очень быстро освободить ресурс. Тогда появляется вероятность, что ресурс будет освобожден еще до того, как вызывающий поток завершит переход в режим ядра. В итоге уйма процессорного времени будет потрачена впустую.
Microsoft повысила быстродействие критических секций, включив в них спин-блокировку Теперь, когда Вы вызываете EnterCriticalSection, она выполняет заданное число циклов спин-блокировки, пытаясь получить доступ к ресурсу и лишь в том случае, когда все попытки закапчиваются неудачно, функция переводит поток в режим ядра, где он будет находиться в состоянии ожидания.
Для использования спин-блокировки в критической секции нужно инициализировать счетчик циклов, вызвав:
BOOL InitalizeCriticalSectionAndSpinCount( PCRITICAL_SECTION pcs, DWORD dwSpinCount);
Как и в InitializeCriticalSection, первый параметр этой функции — адрес структуры критической секции. Но во втором параметре, dwSpinCount, передается число циклов спин-блокировки при попытках получить доступ к ресурсу до перевода потока в состояние ожидания. Этот параметр может принимать значения от 0 до 0x00FFFFFF. Учтите, что на однопроцессорной машине значение параметра dwSpinCount игнорируется и считается равным 0. Дело в том, что применение спин-блокировки в такой системе бессмысленно: поток, владеющий ресурсом, не сможет освободить его, пока другой поток "крутится" в циклах спин-блокировки.
Вы можете изменить счетчик циклов спин-блокировки вызовом:
DWORD SetCriticalSectionSpinCount( PCRITICAL_SECTION pcs, DWORD dwSpinCount);
И в этой функции значение dwSpinCount на однопроцессорной машине игнорируется.
Па мой взгляд, используя критические секции, Вы должны всегда применять спин-блокировку — терять Вам просто нечего. Moгут возникнуть трудности в подборе значения dwSpinCount, по здесь нужно просто поэкспериментировать. Имейте в виду, что для критической секции, стоящей па страже динамической кучи Вашего процесса, этот счетчик равен 4000.
Как реализовать критические секции с применением спин-блокировки, я покажу в главе 10.
Критические секции: важное дополнение
Теперь, когда у Вяс появилось общее представление о критических секциях (зачем они нужны и как с их помощью можно монопольно распоряжаться разделяемым ресурсом), давайте повнимательнее приглядимся ктому, как они устроены. Начнем со структуры CRITICAL_SECTION. Вы не найдете ее в Platform SDK — о ней нет даже упоминания. В чем дело?
Хотя CRITICAL_SECTION не относится к недокументированным структурам, Microsoft полагает, что Вам незачем знать, как она устроена. И это правильно. Для нас она нвляется своего рода черным ящиком - сама структура известна, а ее элементы — нет. Конечно, поскольку CRITICAL_SECTION — не более чем одна из структур, мы можем сказать, из чего она состоит, изучив заголовочные файлы. (CRITICAT,_SECTlON определена в файле WinNT.h как RTL_CRITICAL_SECTION, а тип структуры RTL_CRITICAL_SECTION определен в файле WinBase.h.) Но никогда не пишите код, прямо ссылающийся на ее элементы.
Вы работаете со структурой CRITICAL_SECTION исключительно через функции Windows, передавая им адрес соответствующего экземпляра этой структуры. Функции сами знают, как обращаться с ее элементами, и гарантируют, что она всегда будет в согласованном состоянии. Так что теперь мы перейдем к рассмотрению этих функций.
Обычно структуры CRITICAL_SECTION создаются как глобальные переменные, доступные всем потокам процесса. Но ничто не мешает нам создавать их как локальные переменные или переменные, динамически размещаемые в куче. Есть только два условия, которые надо соблюдать Во-первых, все потоки, которым может понадобиться ресурс, должны знать адрес структуры CRITICAL_SECTION, которая защищает этот ресурс. Вы можете получить ее адрес, используя любой из существующих механизмов. Во-вторых, элементы структуры CRITICAL_SECTION следует инициализировать до обращения какого-либо потока к защищенному ресурсу. Структура инициализируется вызовом:
VOID InitializeCriticalSection(PCRITICAL_SECTION pcs);
Эта функция инициализирует элементы структуры CRITICAL_SECTION, на которую указывает параметр pcs.
Поскольку вся работа данной функции заключается в инициализации нескольких переменных-членов, она не дает сбоев и поэтому ничего не возвращает (void). InitializeCriticalSection должна быть вызвана до того, как один иэ потоков обратится к EnterCriticalSection. В документации Platform SDK недвусмысленно сказано, что попытка воспользоваться неинициализированной критической секцией даст непредсказуемые результаты.
Если Вы знаете, что структура CRITICAL_SECTION больше не понадобится ни одному потоку, удалите ее, вызвав DeleteCriticalSection:
VOID DeleteCriticalSection(PCRITICAL__SECTION pcs);
Она сбрасывает все переменные-члены внутри этой структуры. Естественно, нельзя удалять критическую секцию в тот момент, когда ею все еще пользуется какой-либо поток. Об этом нас предупреждают и в документации Platform SDK.
Участок кода, работающий с разделяемым ресурсом, предваряется вызовом:
VOID EnterCriticalSection(PCRITICAL_SECTION pcs);
Первое, что делает EnterCriticalSection, — исследует значения элементов структуры CRITICAL_SECTION. Если ресурс занят, в них содержатся сведения о том, какой поток пользуется ресурсом. EnterCriticalSection выполняет следующие действия.
Если ресурс свободен, EnterCriticalSection модифицирует элементы структуры, указывая, что вызывающий поток занимает ресурс, после чего немедленно возвращает управление, и поток продолжает свою работу (получив доступ к ресурсу). Если значения элементов структуры свидетельствуют, что ресурс уже захвачен вызывающим потоком, EnterCriticalSection обновляет их, отмечая тем самым, сколько раз подряд этот поток захватил ресурс, и немедленно возвращает управление. Такая ситуация бывает нечасто — лишь тогда, когда поток два раза подряд вызывает EnterCriticalSection без промежуточного вызова LeaweCritical Section. Если значения элементов структуры указывают на то, что ресурс занял другим потоком, EnterCriticalSection переводит вызывающий поток в режим ожидания. Это потрясающее свойство критических секций: поток, пребывая в ожидании, не тратит ни кванта процессорного времени.
Система запоминает, что данный поток хочет получить доступ к ресурсу, и - как только поток, занимавший этот ресурс, вызывает LeaveCriticalSection — вновь начинает выделять нашему потоку процессорное время. При этом она передает ему ресурс, автоматически обновляя элементы структуры CRITICAL_SECTION.
Внутреннее устройство EnterCriticalSection не слишком сложно; она выполняет лишь несколько простых операций. Чем она действительно ценна, так это способностью выполнять их на уровне атомарного доступа. Даже если два потока на много процессорной машине одновременно вызовут EnterCriticalSection, функция все равно корректно справится со своей задачей: один поток получит ресурс, другой — перейдет в ожидание.
Поток, переведенный EnterCriticalSection в ожидание, может надолго лишиться доступа к процессору, а в плохо написанной программе — даже вообще не получить его. Когда именно так и происходит, говорят, что поток "голодает".
WINDOWS 2000
В действительности потоки, ожидающие освобождения критической секции, никогда не блокируются "навечно" EnterCriticalSection устроена так, что по истечении определенного времени, генерирует исключение. После этого Вы можете подключить к своей программе отладчик и посмотреть, что в ней слу чилось. Длительность времени ожидания функцией EnterCriticaiSection опреде ляется значением параметра CriticalSectionTimeout, который хранится в следу ющем разделе системного реестра:
HKEY_LOCAL_MACHlNE\System\CurrentControlSet\Control\Session Manager
Длительность времени ожидания измеряется в секундах и по умолчанию равна 2 592 000 сскунд (что составляет ровно 30 суток). Не устанавливайте слишком малое значение этого параметра (например, менее 3 секунд), так как иначе Вы нарушиге работу других потоков и приложений, которые обычно ждут освобождения критической секции дольше трех секунд.
Вместо EnterCriticalSection Вы можете воспользоваться:
BOOL TryEnterCriticalSection(PCRITICAL_SECTIQN pcs);
Эта функция никогда не приостанавливает выполнение вызывающего потока.
Но возвращаемое ею значение сообщает, получил ли этот поток доступ к ресурсу. Если при ее вызове указанный ресурс занят другим потоком, она возвращает FALSE.
TryEnterCriticalSection позволяет потоку быстро проверить, доступен ли ресурс, и ссли нет, папяться чем-нибудь другим. Если функция возвращает TRUE, значит, она обновила элементы структуры CRITICAL_SECTION так, чтобы они сообщали о захвате ресурса вызывающим потоком. Отсюда следует, что для каждого вызова функции TryEnterCriticalScction, где она возвращает TRUE, надо предусмотреть парный вызов LeaveCriticalSection.
WINDOWS 2000
В Windows 98 функция TryEnterCriticalSection определена, но не реализована. При ее вызове всегда возвращается FALSE.
В конце участка кода, использующего разделяемый ресурс, должен присутствовать вызов.
VOID LeaveCriticalSection(PCRITICAL_SECTION pcs);
Эта функция просматривает элементы структуры CRITICAL_SECTION и уменьшает счетчик числа захватов ресурса вызывающим потоком на 1. Если его значение больше 0, LeaveCriticalSection ничего не делает и просто возвращает управление.
Если значение счетчика достигло 0, LeaveCnitcalSection сначала выясняет, есть ли в системе другие потоки, ждущие данный ресурс в вызове EnlerCriticalSection. Если есть хотя бы один такой поток, функция настраивает значения элементов структуры, что бы они сигнализировали о занятости ресурса, и отдает его одному из ждущих потоков (поток выбирается "по справедливости"). Если же ресурс никому не нужен, Leave CriticalSection соответственно сбрасывает элементы структуры.
Как и EnterCriticalSection, функция LeaveCriticalSection выполняет все действия на уровне атомарного доступа. Однако LeaveCrjticalSection никогда не приостанавливает поток, а управление возвращает немедленно.
Локальное состояние ввода
Независимая обработка ввода потоками, предотвращающая неблагоприятное воздей ствие одного потока на другой, — это лишь часть того, чтo обеспечивает отказоус тойчивость модели аппаратного ввода По этого недостаточно для надежной изоля ции потоков друг от друга, и поэтому система поддерживает дополнительную кон цепцию — локальное состояние ввода (local input btate).
Каждый поток обладает собственным состоянием ввода, сведения о котором хра нятся в структуре THREADINFO (глава 26) В информацию об этом состоянии вклю чаются данные об очереди виртуального ввода потока и группа переменных. Послед ние содержат управляющую информацию о состоянии ввода.
Для клавиатуры поддерживаются следующие.сведения
какое окно находится в фокусе клавиатуры;
какое окно активно в данный момент; какие клавиши нажаты; состояние курсора ввода ;
Для мыши учитывается такая информация
каким окном захвачена мышь; какова форма курсора мыши; видим ли этот курсор;
Так как у каждого потока свой набор переменных состояния ввода, то и представ ления об окне, находящемся в фокусе, об окне, захватившем мышь, и т. п. у них тоже сугубо свои. С точки зрения потока, клавиатурный фокус либо есть у одного из сго окон, либо его нет ни у одного окна во всей сисхеме, То же самое относится и к мыши либо она захвачена одним из сго окон, либо не захвачена никем. В общем, перечис лять можно еще долго. Так вот, подобный сепаратизм приводит к некоторым послед ствиям — о них мы и поговорим.
Локальный доступ
Перекачка страницы из оперативной памяти в страничный файл занимает ощутимое время. Та же задержка происходит и в момент загрузки страницы данных обратно в оперативную память. Обращаясь в основном к памяти, локализованной в небольшом диапазоне адресов, Вы снизите вероятность перекачки страниц между оперативной памятью и страничным файлом.
Поэтому при разработке приложения старайтесь размещать объекты, к которым необходим частый доступ, как можно плотнее друг к другу. Возвращаясь к примеру со связанным списком и двоичным деревом, отмечу, что просмотр списка не связан с просмотром двоичного дерева. Разместив все структуры NODE друг за другом в одной куче, Вы, возможно добьетесь того, что по крайней мере несколько структур NODE уместятся в пределах одной страницы физической памяти. И тогда просмотр связанного списка не потребует от процессора при каждом обращении к какой-либо структуре NODE переключаться с одной страницы на другую.
Если же "свалить" оба типа cтpyктyp в одну кучу, обьекты NODE необязательно будут размещены строго друг за другом. При самом неблагоприятном стечении об стоятельств на странице окажется всего одна структура NODE, a остальное место займут структуры BRANCH. B этом случае просмотр связанного списка будет приводить к ошибке страницы (page fault) при обращении к каждой структуре NODE, что в результате может чрезвычайно замедлить скорость выполнения Вашего процесса.
Материалы для обязательного чтения
Часть I: Материалы для обязательного чтения
Глава 1 - Обработка ошибок
Прежде чем изучать функции, предлагаемые Microsoft Windows, посмотрим, как в них устроена обработка ошибок.
Когда Вы вызываете функцию Windows, она проверяет переданные ей параметры, а затем пытается выполнить свою работу. Если Вы передали недопустимый параметр или если данную операцию нельзя выполнить по какой-то другой причине, она возвращает значение, свидетельствующее об ошибке, В таблице 1 -1 показаны типы данных для возвращаемых значений большинства функций Windows.
| VOID | Функция всегда (или почти всегда) выполняется успешно. Таких функций в Windows очень мало. |
| BOOL | Если вызов функции заканчивается неудачно, возвращается 0; в остальных случаях возвращаемое значение олично от 0. (Не пытайтесь проверять его на соответствие TRUE или FALSE) |
| HANDLE | Если вызов функции заканчивается неудачно, то обычно возвращается NULL, в остальных случаях HANDLE идентифицирует объект, которым Вы можете манипулировать Будьте осторожны: некоторые функции возвращают HANDLE со значением INVALID_HANDLE_VALUE, равным 1. В документации Platform SDK для каждой функции четко указывается, что именно она возвращает при ошибке — NULL или INVALID_HANDLE_VALUE. |
| PVOID | Если вызов функции заканчивается неудачно, возвращается NULL, в остальных случаях PVOID сообщает адрес блока данных в памяти. |
| LONG/DWORD | Это значение — "крепкий орешек". Функции, которые сообщают значения каких-либо счетчиков, обычно возвращают LONG или DWORD. Если по какой-то причине функция не сумела сосчитать то, что Вы хотели, она обычно возвращаем 0 или -1 (все зависит от конкретной функции). Если Вы используете одну из таких функций, проверьте по документации Platform SDK, каким именно значением она уведомляет об ошибке. |
Таблица 1-1. Стандартные типы значений, возвращаемых функциями Windows
При возникновении ошибки Вы должны разобраться, почему вызов данной функции оказался неудачен.
За каждой ошибкой закреплен свой код — 32-битное число.
Функция Windows, обнаружив ошибку, через механизм локальной памяти потока сопоставляет соответствующий кол ошибки с вызывающим потоком (Локальная память потока рассматривается в главе 21.) Это позволяет потокам работать независимо друг от друга, не вмешиваясь в чужие ошибки. Когда функция вернет Вам управление, ее возвращаемое значение будет указывать на то, что произошла какая-то ошибка. Какая именно — Вы узнаете, вызвав функцию GetLastError.
| DWORD GetLastError(); |
Теперь, когда у Вас есть код ошибки, Вам нужно обменять его на что-нибудь более внятное. Список кодов ошибок, определенных Microsoft, содержится в заголовочном файле WinError.h. Я приведу здесь его небольшую часть, чтобы Вы представляли, на что он похож
|
// MessageId: ERROR_SUCCESS // // MessageText: // // The operation completed successfully. // #define ERROR_SUCCESS 0L #define NO_ERROR 0L // dderror #define SEC_E_OK ((HRESULT)0x00000000L) // // MessageId: ERROR_INVALID_FUNCTION // // MessageText: // // Incorrect function. // #define ERROR_INVALID_FUNCTION 1L // dderror // // MessageId: ERROR_FILE_NOT_FOUND // // MessageText: // // The system cannot find the file specified. // #define ERROR_FILE_NOT_FOUND 2L // // MessageId: ERROR_PATH_NOT_FOUND // // MessageText: // // The system cannot find the path specified. // #define ERROR_PATH_NOT_FOUND 3L // // MessageId: ERROR_TOO_MANY_OPEN_FILES // // MessageText: // // The system cannot open the file. // #define ERROR_TOO_MANY_OPEN_FILES 4L // // MessageId: ERROR_ACCESS_DENIED // // MessageText: // // Access is denied. // #define ERROR_ACCESS_DENIED 5L |
Учтите, что я показал лишь крошечную часть файла WinError.h; на самом деле в нем более 21 000 строк!
Функцию GetLastError нужно вызывать сразу же после неудачного вызова функции Windows, иначе код ошибки может быть потерян.
Замечание:
GetLastError возвращает последнюю ошибку, возникшую в потоке. Если этот поток вызывает другую функцию Windows и все проходит успешно, код последней ошибки не перезаписывается и не используется как индикатор благополучного вызова функции. Лишь несколько функций Windows нарушают это правило и все же изменяют код последней ошибки. Однако в документации Platform SDK утверждается обратное: якобы после успешного выполнения API-функции обычно изменяют код последней ошибки.
Windows 98:
Многие функции Windows 98 на самом деле реализованы в 16-разрядном коде, унаследованном от операционной системы Windows 3.1. В нем не было механизма, сообщающего об ошибках через некую функцию наподобие GetLastError, и Microsoft не стала "исправлять" 1б-разрядный код в Windows 98 для поддержки обработки ошибок. На практике это означает, что многие Win32-функции в Windows 98 не устанавливают код последней ошибки после неудачного завершения, а просто возвращают значение, которое свидетельствует об ошибке. Поэтому Вам не удастся определить причину ошибки.
Некоторые функции Windows всегда завершаются успешно, но по разным причинам. Например, попытка создать объект ядра "событие" с определенным именем может быть успешна либо потому, что Вы действительно создали его, либо потому, что такой объект уже есть. Но иногда нужно знать причину успеха. Для возврата этой информации Microsoft предпочла использовать механизм установки кода последней ошибки. Так что и при успешном выполнении некоторых функций Вы можете вызывать GetLastError и получать дополнительную информацию. К числу таких функций относится, например, CreateEvent. О других функциях см. Platform SDK.
На мой взгляд, особенно полезно отслеживать код последней ошибки в процессе отладки. Кстати, отладчик в Microsort Visual Studio 6.0 позволяет настраивать окно Watch так, чтобы оно всегда показывало код и описание последней ошибки в текущем потоке.
Для этого надо выбрать какую-нибудь строку в окне Watch и ввести "@err,hr". Теперь посмотрите на рис. 1-1. Видите, я вызвал функцию CreateFile. Она вернула значение INVALIDHANDLEVALUE (-1) типа HANDLE, cвидетельствующее о том, что ей не удалось открыть заданный файл. Но окно Watch показывает нам код последней ошибки (который вернула бы функция GetLastError, если бы я ее вызвал), равный 0x00000002, и описание "The system cannot find the file specified" ("Система не может найти указанный файл"). Именно эта строка и определена в заголовочном файле WinError.h для ошибки с кодом 2.
Рис. 1 -1. Используя "@err,hr" в окне Watch среды Visual Studio 6.0, Вы можете просматривать
код последней ошибки в текущем потоке
С Visual Studio поставляется небольшая утилита Error Lookup, которая позволяет получать описание ошибки по ее коду.
Если приложение обнаруживает какую-нибудь ошибку, то, как правило, сообщает о ней пользователю, выводя на экран ее описание. В Windows для этого есть специальная функция, которая "конвертирует" код ошибки в ее описание, — FormatMessage.
DWORD ForrnatMessage(
DWORD dwFlags,
LHCVOID pSource,
DWORD dwMessageId,
DWORD dwLanguageId,
PTSTR pszBuffer,
DWORD nSize,
va_list *Arguments);
FormatMessage ~ весьма богатая по своим возможностям функция, и именно ее желательно применять при формировании всех строк, показываемых пользователю Дело в том, что она позволяет легко работать со множеством языков. FormatMessage определяет, какой язык выбран в системе в качестве основного (этот параметр задается через апплет Regional Settings в Control Panel), и возвращает текст на соответствующем языке Разумеется, сначала Вы должны перевести строки на нужные языки и встроить этот ресурс в свой EXE- или DLL -модуль, зато потом функция будет автоматически выбирать требуемый язык. Программа-пример ErrorShow, приведенная в конце главы, демонстрирует, как вызывать эту функцию для получения текстового описания ошибки по ее коду, определенному Microsoft.
Время от времени меня кто-нибудь да спрашивает, составит ли Microsoft полный список кодов всех ошибок, возможных в каждой функции Windows. Ответ; увы, нет. Скажу больше, такого списка никогда не будет — слишком уж сложно сго составлять и поддерживать для все новых и новых версий системы.
Проблема с подобным списком еще и в том, что Вы вызываете одну API-функцию, а она может обратиться к другой, та — к третьей и т. д, Любая из этих функций может завершиться неудачно (и по самым разным причинам). Иногда функция более высокого уровня сама справляется с ошибкой в одной из вызванных ею функций и в конечном счете выполняет то, что Вы от нее хотели. В общем, для создания такого списка Microsoft пришлось бы проследить цепочки вызовов в каждой функции, что очень трудно. А с появлением новой версии системы эти цепочки нужно было бы пересматривать заново.
Механизм Address Windowing Extensions (только Windows 2000)
Жизнь идет вперед, и приложения требуют все больше и больше памяти — особенно серверные. Чем выше число клиентов, обращающихся к серверу, тем меньше его про изводительность. Для увеличения быстродействия серверное приложение должно хранить как можно больше своих данных в оперативной памяти и сбрасывать их на диск как можно реже. Другим классам приложений (базам данных, программам для работы с трехмерной графикой, математическими моделями и др.) тоже нужно ма нипулировать крупными блоками памяти. И всем этим приложениям уже тесно в 32 разрядном адресном пространстве.
Для таких приложений Windows 2000 предлагает новый механизм — Address Win dowing Extensions (AWE). Создавая AWE, Microsoft стремилась ктому, чтобы приложе ния МОГЛИ:
работать с оперативной памятью, никогда не выгружаемой на диск операци онной системой;
обращаться к таким объемам оперативной памяти, которые превышают раз меры соответствующих разделов в адресных пространствах их процессов.
AWE дает возможность приложению выделять себе один и более блоков оператив ной памяти, невидимых в адресном пространстве процесса. Сделав это, приложение резервирует регион адресного пространства (с помощью VirtualAlloc), и он становит ся адресным окном (address window). Далее программа вызывает функцию, которая связывает адресное окно с одним из выделенных блоков оперативной памяти. Эта операция выполняется чрезвычайно быстро (обычно за пару микросекунд).
Через одно адресное окно единовременно доступен лишь один блок памяти. Это, конечно, усложняет программирование, так как при обращении к другому блоку при ходится явно вызывать функции, которые как бы переключают адресное окно на оче редной блок.
Вот пример, демонстрирующий использование AWE:
// сначала резервируем для адресного окна регион размером 1 Мб
ULONG_PTR ulRAMBytes = 1024 * 1024;
PVOlD pvWindow = VirtualAlloc(NULL, ulRAMBytes, MEM_RESERVE | MEMJ>HYSICAL, PAGE_REAOWRITE);
// получаем размер страниц на данной процессорной платформе
SYSTEM_INFO sinf;
GetSystemInfo(&sint);
// вычисляем, сколько страниц памяти нужно для нашего количества байтов
ULONG_PTR ulRAMPages = (ulRAMBytes + sinf.dwPageSize - 1) / sinf.dwPageSize;
// создаем соответствующий массив для номеров фреймов страниц
ULONG_PTR aRAMPages[ulRAHPages];
// выделяем сграницы оперативной памяти (в полномочиях пользователя
// должна быть разрешена блокировка страниц в памяти)
AllocateUserPhysicalPages(
GetCurrentProcess(), // выделяем память для нашего процесса
&ulRAMPages, // на входе: количество запрошенных страниц
RAM, // на выходе: количество выделенных страниц RAM
aRAMPages); // на выходе специфический массив,
// идентифицирующий выделенные страницы
// назначаем страницы оперативной памяти нашему окну
MapUserPhysicalPages(
pvWindow, // адрес адресного окна
ulRAMPages, // число элементов в массиве
aRAHPages); // массив страниц RAM
// обращаемся к этим страницам через виртуальный адрес pvWindow
...
// освобождаем блок страниц оперативной памяти
FreeUserPhysicalPages(
GetCurrentProcess(), // освобождаем RAM, выделенную нашему процессу
&ulRAMPages, // на входе, количество страниц
RAM, // на выходе: количество освобожденных страниц RAM
aRAMPages); // на входе- массив, иден1ифицирующий освобождаемые
// страницы RAM
// уничтожаем адресное окно
VirtualFree(pvWindow, 0, MEM_RELbASE);
Как видите, пользоваться AWE несложно. А теперь хочу обратить Ваше внимание на несколько интересных моментов, связанных с этим фрагментом кода.
Вызов VirtualAlloc резервирует адресное окно размером 1 Мб. Обычно адресное окно гораздо больше. Бы должны выбрать его размер в соответствии с объемом бло ков оперативной памяти, необходимых Вашему приложению. Но, конечно, размер такого окна ограничен размером самого крупного свободного (и непрерывного) блока в адресном пространстве процесса. Флаг MEM_RESERVE указывает, что я про сто резервирую диапазон адресов, а флаг MEM_PHYSICAL — что в конечном счете этот диапазон адресов будет связан с физической (оперативной) памнтью.
Механизм AWE требует, чтобы вся намять, связываемая с адресным окном, была доступна для чтения и записи; поэтому в данном случае функции VirtualAlloc можно передать только один атрибут защиты — PAGE_READWRITE, Кроме того, нельзя пользоваться функцией VirtualProtect и пытаться изменять тип защиты этого блока памяти.
Для выделения блока в физической памяти надо вызвать функцию AllocateUser PhysicalPages:
BOOL AllocateUserPhysicalPages( HANDLE hProcess, PULONG_PTR pulRAMPages, PULONG_PTR aRAMPages);
Она выделяет количество страниц оперативной памяти, заданное в значении, на которое указывает параметр pulRAMPages, и закрепляет эти страницы за процессом, определяемым параметром hProcess
Операционная система назначает каждой странице оперативной памяти номер фрейма страницы (page frame number) По мсре того как система отбирает страни цы памяти, выделяемые приложению, она вносит соответствующие данные (номер фрейма страницы для каждой страницы оперативной памяти) в массив, на который указывает параметр dRAMPages. Сами по себе эти номера для приложения совершен но бесполезны; Вам не следует просматривать содержимое этого массива и тем бо
лее что-либо менять в нем. Вы не узнаете, какие страницы оперативной памяти будут выделены под запрошенный блок, да это и не нужно. Когда эти страницы связывают ся с адресным окном, они появляются в виде непрерывного блока памяти, А что там система делает для этого, Вас не должно интересовать
Когда fyyHKiwnAllocateUserPbystcalPages возвращает управление, значение в pulRAM Pages сообгцает количество фактически выделенных страниц. Обычно оно совпадает с тем, что Вы передаете функции, но может оказаться и поменьше.
Страницы оперативной памяти выделяются только процессу, из которого была вызвана данная функция; AWE не разрешает проецировать их на адресное простран ство другого процесса. Поэтому такие блоки памяти нельзя разделять между процес сами.
NOTE:
Конечно, оперативная память — ресурс драгоценный, и приложение может выделить лишь ее незадействованную часть.
Не злоупотребляйте механизмом AWE: если Ваш процесс захватит слишком много оперативной памяти, это может привести к интенсивной перекачке страниц на диск и резкому падению производительности вссй системы. Кроме того, это ограничит возможности системы в создании новых процессов, потоков и других ресурсов (Монито ринг степени использования физической памяти можно реализовать через функцию GlobalMemoryStatusEx)
AllocateUserPhysicalPages требует также, чтобы приложению была разреше на блокировка страниц в памяти (т. e. у пользователя должно быть право "Lock Pages in Memory"), a иначе функция потерпит неудачу. По умолчанию таким правом пользователи или их группы не наделяются. Оно назначается учетной записи Local System, которая обычно используется различными службами. Если Вы хотите запускать интерактивное приложение, вызывающее AttocateUser PhysicalPages, администратор должен предоставить Вам соответствующее пра во еще до того, как Вы зарегистрируетесь в системе.
Теперь, создав адресное окно и выделив блок памяти, я связываю этот блок с ок ном вызовом функции MapUserPhysicalPages:
BOOL MapUserPhysicalPages( PVOID pvAddressWindow, ULONG_PTR ulRAMPages, PULONG_PTR aRAMPages);
Ее первый параметр, pvAddressWindow, определяет виртуальный адрес адресного окна, а последние два параметра, ulRAMPages и aRAMPages, сообщают, сколько стра ниц оперативной памяти должно быть видимо через адресное окно и что это за стра ницы. Если окно меньше связываемого блока памяти, функция потерпит неудачу.
NOTE:
Функция MapUserPhysicalPages отключает текущий блок оперативной памяти от адресного окна, если вместо параметра aRAMPages передается NULL. Вот пример:
// отключаем текущий блок RAM от адресного окна
MapUserPhysicalPayes(pvWindow, ulRAMPapes, NULL);
WINDOWS 2000
Связав блок оперативной памяти с адресным окном, Бы можете легко обра щаться к этой памяти, просто ссылаясь на виртуальные адреса относительно базового адреса адресного окна (в моем примере эти pvWindow)
Когда необходимость в блоке памяти отпадет, освободите его вызовом функции FreeUserPhysicalPages:
BOOL FreeUserPhysicalPages( HANDLE hProcess, PULONG_PTR pulRAMPages, PULONG_PTR aRAMPages);
В Windows 2000 право "Lock Pages in Memory" активизируется так:
Запустите консоль Computer Management MMC. Для этого щелкните кнопку Start, выберите команду Run, введите "compmgmt.msc /а" и щелкните кнопку ОК.
Если в левой секции нет элемента Local Computer Policy, выберите из меню Console команду Add/Remove Snap-in. На вкладке Standalone в списке Snap-ins Added То укажите строку Computer Management (Local). Теперь щелкните кноп ку Add, чтобы открыть диалоговое окно Add Standalone Snap-in, B списке Avai lable Standalone Snap-ins укажите Select Group Policy и выберите кнопку Add. В диалоговом окне Select Group Policy Objcct просто щелкните кнопку Finish. Наконец, в диалоговом окне Add Standalone Snap-in щелкните кнопку Close, a и диалоговом окне Add/Remove Snap-in — кнопку OK После этого в левой сек ции консоли Computer Management должен появиться элемент Local Computer Policy.
В левой секции консоли последовательно раскройте следующие элементы: Local Computer Policy, Computer Configuration, Windows Settings, Security Settings и Local Policies. Выберите User Rights Assignment.
В правой секции выберите атрибут Lock Pages in Memory.
Выберите из меню Action команду Select Security, чтобы открыть диалоговое окно Lock Pages in Memory. Щелкните кнопку Add. В диалоговом окне Sclect Users or Groups добавьте пользователей и/или группы, которым Вы хотите раз решить блокировку страниц в памяти. Затем закройте все диалоговые окна, щелкая в каждом из них кнопку ОК.
Новые права вступят в силу при следующей регистрации в системе. Если Вы только что сами себе предоставили право "Lock Pages in Memory", выйдите из системы и вновь зарегистрируйтесь в ней.
Ее первый параметр, bProcess, идентифицирует процесс, владеющий данными страницами памяти, а последние два параметра сообщают, сколько страниц опера тивной памяти следует освободить и что это за страницы.
Если освобождаемый блок в данный момент связан с адресным окном, он сначала отключается от этого окна
И, наконец, завершая очистку, я освобождаю адресное окно. Для этого я вызываю VirtualFree и передаю ей базовый виртуальный адрес окна, нуль вместо размера реги она и флаг MEM_RELEASE.
В моем простом примере создается одно адресное окно и единственный блок памяти. Это позволяет моей программе обращаться к оперативной памяти, которая никогда не будет сбрасываться на диск. Однако приложение может создать несколь ко адресных окон и выделить несколько блоков памяти. Эти блоки разрешается свя зывать с любым адресным окном, но операционная система не позволит связать один блок сразу с двумя окнами.
64-разрядная Windows 2000 полностью поддерживает AWE, так что перенос 32 разрядных приложений, использующих этот механизм, не вызывает никаких проблем. Однако AWE не столь полезен для 64-разрядных приложений, поскольку размеры их адресных пространств намного больше Но все равно он дает возможность приложе нию выделять физическую память, которая никогда пе сбрасывается на диск.
Метод 1: один файл, один буфер
Первый (и теоретически простейший) метод — выделение блока памяти, достаточ ного для размещения всего файла Открываем файл, считываем eго содержимое в блок памяти, закрываем. Располагая в памяти содержимым файла, можно поменять первый
байт с последним, второй — с предпоследним и т. д. Этот процесс будет продолжать ся, пока мы не поменяем местами два смежных байта, находящихся в середине файла. Закончив эту операцию, вновь открываем файл и перезаписываем его содержимое.
Этот довольно простой в реализации метод имеет два существенных недостатка Во-первых, придется выделить блок памяти такого же размера, что и файл. Это тер пимо, если файл небольшой. А если он занимает 2 Гб? Система просто не позволит приложению передать такой объем физической памяти. Значит, к болыпим файлам нужен совершенно иной подход.
Во-вторых, если перезапись вдруг прервется, содержимое файла будет испорче но. Простейшая мера предосторожности — создать копию исходного файла (потом ее можно удалить), но это потребует дополнительного дискового пространства
Метод 2: два файла, один буфер
Открываем существующий файл и создаем на диске новый — нулевой длины. Затем выделяем небольшой внутренний буфер размером, скажем, 8 Кб. Устанавливаем ука затель файла в позицию 8 Кб от конца, считываем в буфер последние 8 Кб содержи мого файла, меняем в нем порядок следования байтов на обратный и переписываем буфер в только что созданный файл. Повторяем эти операции, пока нс доЙдем до начала исходного файла, Конечно, если длина файла не будет кратна 8 Кб, операции придется немного усложнить, но это не страшно. Закончив обработку, закрываем оба файла и удаляем исходный файл.
Этот метод посложнее первого, зато позволяет гораздо эффективнее использовать память, так как требует выделения лишь 8 Кб, Но и здесь не без проблем, и вот двс главных.. Во-первых, обработка идет медленнее, чем при первом методе: на каждой итерации перед считыванием приходится находить нужный фрагмент исходного файла. Во-вторых, может понадобиться огромное пространство па жестком диске. Если длина исходного файла 400 Мб, новый файл постепенно вырастет до этой вели чины, и перед самым удалением исходного файла будет занято 800 Мб, т. e. на 400 Мб больше, чем следовало бы. Так что все пути ведут... к третьему методу
Метод 3: один файл, два буфера
Программа инициализирует два раздельных буфера, допустим, по 8 Кб и считывает первые 8 Кб файла в один буфер, а последние 8 Кб — в другой. Далее содержимое обоих буферов обменивается в обратном порядке и первый буфер записывается в конец, а второй — в начало того же файла. На каждой итерации программа переме щает восьмикилобайтовые блоки из одной половины файла в другую. Разумеется, нужно предусмотреть какую-то обработку на случай, ссли длина файла не кратна 16 Кб, и эта обработка будет куда сложнее, чем в предыдущем методе. Но разве это испугает опытного программиста?
По сравнению с первыми двумя этот метод позволяет экономить пространство на жестком диске, так как все операции чтения и записи протекают в рамках одного файла. Что же касается памяти, то и здесь данный метод довольно эффективен, ис пользуя всего 16 Кб. Однако он, по-видимому, самый сложный в реализации. И, кро ме того, как и первый метод, он может испортить файл данных, ссли процесс вдруг прервется.
Ну а теперь посмотрим, как тот же процесс реализуется, если применить файлы, проецируемые в память.
Метод 4: один файл и никаких буферов
Вы открываете файл, указывая системе зарезервировать регион виртуального адрес ного пространства. Затем сообщаете, что первый байт файла следует спроецировать на первый байт этого региона, и обращаетесь к региону так, будто он на самом деле содержит файл. Если в конце файла есть отдельный нулевой байт, можно вызвать библиотечную функцию _strrev и поменять порядок следования байтов на обратный. Огромный плюс этого метода в том, что всю работу по кэшированию файла вы полняет сама система: не надо выделить память, загружать данные из файла в память, переписывать их обратно в файл и т. д. и т. п. Но, увы, вероятность прерывания про цесса, например из-за сбоя в электросети, по-прежнсму сохраняется, и от порчи дан ных Вы не застрахованы.
Мьютексы
Объекты ядра "мьютексы" гарантируют потокам взаимоисключающий доступ к един ственному ресурсу. Отсюда и произошло название этих объектов (mutual exclusion, mutex). Они содержат счетчик числа пользователей, счетчик рекурсии и переменную, в которой запоминается идентификатор потока. Мьютексы ведут себя точно так же, как и критические секции. Однако, если последние являются объектами пользователь ского режима, то мьютексы — объектами ядра. Кроме того, единственный объект-мью текс позволяет синхронизировать доступ к ресурсу нескольких потоков из разных процессов; при этом можно задать максимальное время ожидания доступа к ресурсу.
Идентификатор потока определяет, какой поток захватил мьютекс, а счетчик ре курсий — сколько раз. У мьютексов много применений, и это наиболее часто исполь зуемые объекты ядра. Как правило, с их помощью защищают блок памяти, к которо му обращается множество потоков Если бы потоки одновременно использовали ка кой-то блок памяти, данные в нем были бы повреждены. Мьютексы гарантируют, что любой поток получает монопольный доступ к блоку памяти, и тем самым обеспечи вают целостность данных.
Для мьютексов определены следующие правила:
если его идентификатор потока равен 0 (у самого потока не может быть та кой идентификатор), мьютекс не захвачен ни одним из потоков и находится в свободном состоянии;
если его идентификатор потока не равен 0, мьютекс захвачен одним из пото ков и находится в занятом состоянии;
в отличис от других объектов ядра мьютексы могут нарушать обычные прави ла, действующие в операционной системе (об этом — чуть позже)
Для использования объекта-мьютекса один из процессов должен сначала создать его вызовом CreateMutex:
HANDLE CreateMutex( PSECURITY_ATTRIBUTES psa, BOOL fIniLialOwner, PCTSTR pszName);
O параметрах psa и pszName я рассказывал в главе 3. Разумеется, любой процесс может получить свой ("процессо-зависимый") описатель существующего объекта "мьютекс", вызвав OpenMutex:
HANDLE OpenMutex( DWORD fdwAccess, 800L bInheritHandle, PCTSTR pszName);
Параметр fInitialOwner опрсдсляст начальное состояние мьютекса. Если в нем пе редается FALSE (что обычно и бывает), объект-мьютекс не принадлежит ни одному из потоков и поэтому находится в свободном состоянии. При этом его идентифика тор потока и счетчик рекурсии равны 0 Если же в нем передается TRUE, идентифи катор потока, принадлежащий мьютексу, приравнивается идентификатору вызываю щего потока, а счетчик рекурсии получает значение 1. Поскольку теперь идентифи катор потока отличен от 0, мьютекс изначально находится в занятом состоянии.
Поток получаст доступ к разделяемому ресурсу, вызывая одну из Wait-функций и передавая ей описатель мьютекса, который охраняет этот ресурс. Wait-функция про веряет у мьютекса идентификатор потока, если сго значение не равно 0, мьютекс сво боден, в ином случае оно принимает значение идентификатора вызывающего пото ка, и этот поток остается планируемым.
Если Wait-функция определяет, что у мьютекса идентификатор потока не равен 0 (мьютекс занят), вызывающий поток переходит в состояние ожидания. Система за поминает это и, когда идентификатор обнуляется, записывает в него идентификатор ждущего потока, а счетчику рекурсии присваивает значение 1, после чего ждущий поток вновь становится планируемым. Все проверки и изменения состояния объек та-мьютекса выполняются на уровне атомарного доступа.
Для мьютексов сделано одно исключение в правилах перехода объектов ядра из одного состояния в другое Допустим, поток ждет освобождения занятого объекта мьютекса В этом случае поток обычно засыпает (переходит в состояние ожидания). Однако система проверяет, не совпадает ли идентификатор потока, пытающегося захватить мьютекс, с аналогичным идентификатором у мьютекса Если они совпада ют, система по-прежнему выделяет потоку процессорное время, хотя мьютскс все ещс занят. Подобных особенностей в поведении нет ни у каких других объектов ядря в системе. Всякий раз, когда поток захватывает объект-мьютекс, счетчик рекурсии в этом объекте увеличивается на 1 Единственная ситуация, в которой значение счет чика рекурсии может быть больше 1, — поток захватывает один и тот же мьютскс несколько раз, пользуясь упомянутым исключением из общих правил.
Когда ожидание мьютекса потоком успешно завершается, последний получает монопольный доступ к защищенному ресурсу. Все остальные потоки, пытающиеся обратиться к этому ресурсу, переходят в состояние ожидания Когда поток, занимаю щий ресурс, заканчивает с ним работать, он должен освободить мьютекс вызовом функции ReleaseMutex
BOOL ReleaseMutex(HANDLE hMutex);
Эта функция уменьшает счстчик рекурсии в объекте-мьютексе на 1. Если данный объект передавался во владение потоку неоднократно, поток обязан вызвать Release Mutex столько раз, сколько необходимо для обнуления счстчика рекурсии Как толь ко счетчик станет равен 0, псрсмснная, хранящая идентификатор потока, тоже обну лится, и объект-мьютекс освободится. После этого система проверит, ожидают ли
освобождения мьютекса какие-нибудь другие потоки. Если да, система "по-честному" выберет один из ждущих потоков и передаст ему во владение объект-мьютекс.
Мьютексы и критические секции
Мьютексы и критические секции одинаковы в том, как они влияют на планирование ждущих потоков, но различны по некоторым другим характеристикам. Эти объекты сравниваются в следующей таблице.
|
Характеристики |
Объект-мьютекс |
Обьект — критическая секция | |||
|
Быстродействие |
Малое |
Высокое | |||
|
Возможность использования за границами процесса |
Да |
Нет | |||
|
Объявление |
HANDLE hmfx; |
CRITICAL_SECTION cs; | |||
|
Инициализация |
hmtx = CreateMutex (NULL, FALSE, NULL); |
InitializeCriticalSection(&cs); | |||
|
Очистка |
CloseHandle(hmtx); |
DeleteCriticalSection(&cs); | |||
|
Бесконечное ожидание |
WaitForSingleObject (hmtx, INFINITE); |
EnterCrittcalSection(&cs); | |||
|
Ожидание в течение 0 мс |
WaitForSingleObject (hmtx, 0); |
TryEnterCriticalSection (&cs); | |||
|
Ожидание в течение произвольного периода времени |
WaitForSingleObject (hmtx, dwMilliseconds); |
Невозможно | |||
|
Освобождение |
ReleaseMutex(hmtx); |
LeaveCriticalSecliun(&cs); | |||
|
Возможность параллельного ожидания других объектов ядра |
Да (с помощью WaitForMultipleObjects или аналогичной функции) |
Нет |
Модификация базовых адресов модулей
У каждого EXE и DLL-модуля есть предпочтительный базовый адрес (preferred base address) — идеальный адрес, по которому он должен проецироваться на адресное пространство процесса. Для ЕХЕ-модуля компоновщик выбирает в качестве такого адреса значение 0x00400000, а для DLL-модуля — 0x10000000. Выяснить этот адрес позволяет утилита DumpBin с ключом /Headers. Вот какую информацию сообщает DumpBin о самой себе:
С \>DUMPBIN /headers dumpbin.exe
Microsoft (R} COFF Binary File Dumper Version 6 00.8168 Copyright (C) Microsoft Corp 1992-1998. All rights reserved
Dump of file dumpbin.exe
PE signature found
File Type: EXECUTABLE_IMAGE
File HEADER VALUES
14C machine (i386)
3 number of sections
3588004A time date stamp Wed Jun 17 10'43-38 1998 0 file pointer to symbol table 0 number of symbols E0 size of optional header 10F characteristics
Relocations stripped
Executable
Line numbers stripped
Symbols stripped
32 bit word machine
OPTIONAL HEADER VALUES
108 magic #
6.00 linker version
1000 size of code
2000 size of initialized data
0 size of uninitialized data
1320 RVA of entry point
1000 base of code
2000 base of data
400000 image base <-- предпочтительный базовый адрес модуля
1000 section alignment
1000 file alignment 4.00 operating system verbion 0.00 image version 4.00 subsystem version
0 Win32 version 4000 size of image 1000 size of headers 127E2 checksum
3 subsystem (Windows CUI)
0 DLL characteristics
100000 size of stack reserve 1000 size of stack commit
При запуске исполняемого модуля загрузчик операционной системы создает виртуальное адресное пространство нового процесса и проецирует этот модуль по адресу 0x00400000, а DLL-модуль — по адресу 0x10000000. Почему так важен предпочтительный базовый адрес? Взгляните на следующий фрагмент кода.
int g_x;
void Func()
{
g_x = 5; // нас интересует эта строка
}
После обработки функции Func компилятором и компоновщиком полученный машинный код будет выглядеть приблизительно так:
MOV [0x00414540], b
Иначе говоря, компилятор и компоновщик "жестко зашили" в машинный код адpеc переменной g_x: в адресном пространстве процесса (0x00414540). Но, конечно, этот адрес корректен, только ссли исполняемый модуль будет загружен по базовому адресу 0x00400000
А что получится, если тот же исходный код будет помещен в DLL? Тогда машинный код будет иметь такой вид
MOV [0x10014b40], 5
Заметьте, что и на этот paз виртуальный адрес переменной g_x "жестко зашит" в машинный код. И опять жс этот адрес будет правилен только при том условии, что DLL загрузится по своему базовому адресу.
О'кэй, а теперь представьте, что Вы создали приложение с двумя DLL. По умолчанию компоновщик установит для ЕХЕ-модуля предпочтительный базовый адрес 0x00400000, а для обеих DLL — 0x10000000. Если Вы затем попытаетесь запустить исполняемый файл, загрузчик создаст виртуальное адресное пространство и спроецирует ЕХЕ-модуль по адресу 0x00400000 Далее первая DLL будет спроецирована по адресу 0x10000000, но загрузить вторую DLL по предпочтительному базовому адресу не удастся — ee придется проецировать по какому-то другому адресу.
Переадресация (relocation) в EXE- или DLL-модуле операция просто ужасающая, и Вы должны сделать все, чтобы избежать ее. Почему? Допустим, загрузчик переместил вторую DLL по адресу 0x20000000. Тогда код, который присваивает переменной
g_x значение 5, должен измениться на:
MOV [0x20014540], 5
Но в образе файла код остался прежним:
MOV [0x10014540], 5
Если будет выполнен именно этот кол, он перезапишет какое-то 4-байтовое значение в первой DLL значением 5 Но, по идее, такого не должно случиться. Загрузчик исправит этот код. Дсло в том, что, создавая модуль, компоновщик встраивает в конечный файл раздел переадресации (relocation section) co списком байтовых смещений. Эти смещения идентифицируют адреса памяти, используемые инструкциями машинного кода. Если загрузчику удастся спроецировать модуль по его предпочтительному базовому адресу, раздел переадресации не понадобится Именно этого мы и хотим.
С другой стороны, если модуль не удастся спроецировать по базовому адресу, загрузчик обратится к разделу переадресации и последовательно обработает все его записи. Для каждой записи загрузчик обращается к странице памяти, где содержится машинная команда, которую надо модифицировать, получает используемый ею на данный момент адрес и добавляет к нему разницу между предпочтительным базовым адресом модуля и сго фактическим адресом.
В предыдущем примере вторая DLL была спроецирована по адресу 0x20000000, тогда как ее предпочтительный базовый адрес — 0x10000000 Получаем разницу (0х 10000000), добавляем ее к адресу в машинной команде и получаем.
MOV [0x20014540], 5
Теперь и вторая DLL корректно ссылается на переменную g_x. Невозможность загрузить модуль по предпочтительному базовому адресу создает две крупные проблемы
Загрузчику приходится обрабатывать все записи раздела переадресации и модифицировать уйму кода в модуле. Это сильнейшим образом сказывается на быстродействии и может резко увеличить время инициализации приложения. Из-за того что загрузчик модифицирует в оперативной памяти страницы с кодом модуля, системный механизм копирования при записи создает их копии в страничном файле.
Вторая проблема особенно неприятна, поскольку теперь страницы с кодом модуля больше нельзя выгружать из памяти и перезагружать из его файла на диске Вместо этого страницы будут постоянно сбрасываться в страничный файл и подгружаться из него. Это тоже отрицательно скажется па производительности Но и это еще не все. Поскольку все страницы с кодом модуля размещаются в страничном файле, в системе сокращается объем общей памяти, доступной другим процессам, а это ограничивает размер электронных таблиц, документов текстовых процессоров, чертежей CAD, растровых изображений и т. д.
Кстати, Вы можете создать EXE- или DLL-модуль без раздела переадресации, указав при сборке ключ /FIXED компоновщика. Тогда у модуля будет меньший размер, но загрузить сго по другому базовому адресу, кроме предпочтительного, уже не удастся.
Если загрузчику понадобится модифицировать адреса в модуле, в котором пет раздела переадресации, он уничтожит весь процесс, и пользователь увидит сообщение "Abnormal Process Termination" ("аварийное завершение процесса")
Для DLL, содержащей только ресурсы, это тоже проблема. Хотя в ней нет машинного кода, отсутствие раздела переадресации не позволит загрузить ее по базовому
адресу, отличному от предпочтительного Просто нелепо. Но, к счастью, компонов щик может встроить в заголовок модуля информацию о том, что в модуле нет раздела переадресации, так как он вообще не нужен. А загрузчик Windows 2000, обнаружив эту информацию, может пагрупить DLL, которая содержит только ресурсы, без дополнительной нагрузки на страничный файл.
Для создания файла с немодифицируемыми адресами предназначен ключ /SUBSYSTEM:WINDOWS, 5 0 или /SUBSYSTEM:CONSOLE, 5 0; ключ /FIXED при этом не нужен. Если компоновщик определяет, что модификация адресов в модуле не понадобится, он опускает раздел переадресации и сбрасывает в заголовке специальный флаг IMAGEFILERELOCS_STRIPPED Тогда Windows 2000 увидит, что данный модуль можно загружать по базовому адресу, отличному от предпочтительного, и что ему не требуется модификация адресов. Но все, о чем я только что рассказал, поддерживается лишь в Windows 2000 (вот почему в ключе /SUBSYSTEM указывается значение 50)
Теперь Вы понимаете, насколько важен предпочтительный базовый адрес. Загружая несколько модулей в одно адресное пространство, для каждого из них приходится выбирать свои базовые адреса. Диалоговое окно Project Settings в среде Microsoft Visual Studio значительно упрощает решение этой задачи. Вам нужно лишь открыть вкладку Link, в списке Category указать Output, а в поле Base Address ввести предпочтительный адрес. Например, на следующей иллюстрации для DLL установлен базовый адрес 0x20000000
Кстати, всегда загружайте DLL, начиная со старших адресов; это позволяет уменьшить фрагментацию адресного пространства.
NOTE:
Предпочтительные базовые адреса должны быть кратны гранулярности выделения памяти (64 Кб на всех современных платформах).
В будущем эта цифра может измениться Подробнее о гранулярности выделения памяти см. главу 13
О'кэй, все это просто замечательно, но что делать, если понадобится загрузить кучу модулей в одно адресное пространство? Было бы неплохо "одним махом" задать правильные базовые адреса для всех модулей. К счастью, такой способ есть
В Visual Studio есть утилита Rebase.exe. Запустив ее без ключей в командной строке, Вы получите информацию о том, как ею пользоваться. Она описана в документации Platform SDK, и я не буду ее здесь детально рассматривать Добавлю лишь, что в ней нет ничего сверхъестественного: она просто вызывает функцию ReBaselmage для каждого указанного файла. Вот что представляет собой эта функция:
BOOL ReBaseImage(
PSIR CurrentImageName; // полное имя обрабатываемого файла
PSTR SymbolPath; // символьный путь к файлу (необходим для корректности отладочной информации)
BOOL fRebase; // TRUE = выполнить реальную модификацию адреса;
// FALSE - имитировать такую модификацию
BOOL fRebasoSysFileOk; // FALSE = не модифицировать адреса системных файлов
BOOL fGoingDown; // TRUE = модифицировать адрес модуля,
// продвигаясь в сторону уменьшения адресов
ULONG CheckImageSize; // ограничение на размер получаемого в итоге модуля
ULONG* pOldImageSize; // исходный размер модуля
ULONG* pOldImageBase; // исходный базовый адрес модуля
ULONG* pNewIinageSize; // ноеый размер модуля
ULONG* pNfiwImageRase; // новый базовый адрес модуля
ULONG TirneStamp); // новая временная мегка модуля
Когдя Вы запускаете утилиту Rebase, указывая ей несколько файлов, она выполняет следующие операции.
Моделирует создание адресного пространства процесса Открывает все модули, которые загружались бы в это адресное пространство, и получаст предпочтительный базовый адрес и размер каждого модуля. Моделирует переадресацию модулей в адресном пространстве, добиваясь того, чтобы модули не перекрывались. В каждом модуле анализирует раздел переадресации и соответственно изменяет код в фяйле модуля на диске. Записывает новый базовый адрес в заголовок файла.
Rebase — отличная утилита, и я настоятельно рекомендую Вам пользоваться ею. Вы должны запускать ее ближе к концу цикла сборки, когда уже созданы все модули приложения. Кроме того, применяя утилиту Rebase, можно проигнорировать настройку базового адреса в диалоговом окне Pro)cct Settings. Она автоматически изменит базовый адрес 0x10000000 для DLL, задаваемый компоновщиком по умолчанию
Но ни при каких обстоятельствах не модифицируйте базовые адреса системных модулей. Их адреса уже оптимизированы Microsoft, так что при загрузке в одно адресное пространство системные модули не перекрываются
Я, кстати, добавил специальный инструмент в свою программу ProcessInfoexe (см. главу 4) Он показывает список всех модулей, находящихся в адресном пространстве процесса. В колонке BaseAddr сообщается виртуальный адрес, по которому загружен модуль. Справа от BaseAddr расположена колонка ImagAddr Обычно оиа пуста, указывая, что соответствующий модуль загружен по его предпочтительному базовому адресу. Так и должно быть для всех модулей Однако, ссли в этой колонке присутствует адрес в скобках, значит, модуль загружен не по предпочтительному базовому адресу, и в колонке ImagAddr показывается базовый адрес, взятый из заголовка его файла на диске.
Ниже приведена информация о процессе Acrord32.exe, предоставленная моей программой ProcessInfo Обратите внимдние, что часть модулей загружена по предпочтительным базовым адресам, а часть — нет. Для последних сообщается один и тот же базовый адрес, 0x10000000; значит, автор этих DLL не подумал о проблемах модификации базовых адресов — пусть ему будет стыдно.
Наборы символов
Настоящей проблемой при локализации всегда были операции с различными наборами символов. Годами, кодируя текстовые строки как последовательности однобайтовых символов с нулем в конце, большинство программистов так к этому привыкло, что это стало чуть ли не второй их натурой. Вызываемая нами функция strlen возвращает количество символов в заканчивающемся нулем массиве однобайтовых символов. Но существуют такие языки и системы письменности (классический пример — японские иероглифы), в которых столько знаков, что одного байта, позволяющего кодировать не более 256 символов, просто недостаточно. Для поддержки подобных языков были созданы двухбайтовые наборы символов (double-byte character sets, DBCS).
Наследование описателей объекта
Наследование применимо, только когда процессы связаны родственными отношениями (родительский-дочерний). Например, родительскому процессу доступен один или несколько описателей объектов ядра, и он решает, породив дочерний процесс, передать ему по наследству доступ к своим объектам ядра. Чтобы такой сценарий наследования сработал, родительский процесс должен выполнить несколько операций.
Во-первых, еще при создании объекта ядра этот процесс должен сообщить системе, что ему нужен наследуемый описатель данного объекта. (Имейте в виду описатели объектов ядра наследуются, но сами объекты ядра — нет.)
Чтобы создать наследуемый описатель, родительский процесс выделяет и инициализирует структуру SECURITY_ATTRIBUTES, а затем передает ее адрес требуемой Create-функции. Следующий код создаст объект-мьютекс и возвращает его описатель:
SECURITY_ATTRIBUTES sa;
sa.nLength = sizeof(sa);
sa.lpSecuntyDescriptor = NULL;
sa.bInheritHandle =- TRUE; // делаем возвращаемый описатель наследуемым
HANDLE hMutex = CreateMutex(&sa, FALSE, NULL);
Этот код инициализирует структуру SECURTY_ATTRIBUTES, указывая, что объект следует создать с защитой по умолчанию (в Windows 98 это игнорируется) и что возвращаемый описательдолжен быть наследуемым.
WINDOWS 98:
Хотя Windows 98 не полностью поддерживает защиту, она все же поддерживает наследование и поэтому корректно обрабатывает элемент bInheritHandle.
А теперь перейдем к флагам, которые хранятся в таблице описателей, принадлежащей процессу В каждой ее записи присутствует битовый флаг, сообщающий, является данный описатель наследуемым или нет. Если Вы, создавая объект ядра, передадите в парамере типа PSECURITY_ATTRIBUTES значение NULL, то получите ненаследуемый описатель, и этот флаг будет нулевым. А если элемент bInheritHandle равен TRUE, флaгy пpиcвaивaeтcя 1.
Допустим, какому-то процессу принадлежит таблица описателей, как в таблице 3-2.
| Индекс |
Указатель на блок памяти объекта ядра | Маска доступа (DWORD с набором битовых флагов) | Флаги (DWORD с набором битовых флагов) | ||||
| 1 | 0xF0000000 | 0x???????? | 0x00000000 | ||||
| 2 | 0x00000000 | (неприменим) | (неприменим) | ||||
| 3 | 0xF0000010 | 0х???????? | 0x00000001 |
Таблица 3-2. Таблица описателей с двумя действительными записями
Эта таблица свидетельствует, что данный процесс имеет доступ к двум объектам ядра: описатель 1 (ненаследуемый) и 3 (наследуемый).
Следующий этап — родительский процесс порождает дочерний. Это делается с помощью функции CreateProcess:
BOOL CreateProcess(
PCTSTR pszApplicationName,
PTSTR pszCommandLine,
PSECURITY_ATTRIBUTES psaProcess,
PSECURITY_ATTRIBUTES psaThread,
BOOL bInheritHandles,
DWORD fdwCreale,
PVOIO pvEnvironment,
PCTSTR pszCurDir,
PSTARTUPINFO psiStartInfo,
PPROCESS_INFORMATION ppiProcInfo);
Подробно мы рассмотрим эту функцию в следующей главе, а сейчас я хочу лишь обратить Ваше внимание на параметр blnberitHandles. Создавая процесс, Вы обычно передаете в этом параметре FALSE, тем самым сообщая системе, что дочерний процесс не должен наследовать наследуемые описатели, зафиксированные в таблице родительского процесса. Если же Вы передаете TRUE, дочерний процесс наследует описатели родительского. Тогда операционная система создает дочерний процесс, но не дает ему немедленно начать свою работу. Сформировав в нем, как обычно, новую (пустую) таблицу описателей, она считывает таблицу родительского процесса и копирует все ее действительные записи в таблицу дочернего — причем в те же позиции. Последний факт чрезвычайно важен, так как означает, что описатели будут идентичны в обоих процессах (родительском и дочернем).
Помимо копирования записей из таблицы описателей, система увеличивает значения счетчиков соответствующих объектов ядра, поскольку эти объекты теперь используются обоими процессами. Чтобы уничтожить какой-то объект ядра, его описатель должны закрыть (вызовом CloseHandle) оба процесса. Кстати, сразу после возврата управления функцией CreateProcess родительский процесс может закрыть свой описатель объекта, и это никак не отразится на способности дочернего процесса манипулировать с этим объектом.
В таблице 3-3 показано состояние таблицы описателей в дочернем процессе — перед самым началом его исполнения.
Как видите, записи 1 и 2 не инициализированы, и поэтому данные описатели неприменимы в дочсрнсм процессе Однако индекс 3 действительно идентифицирует объект ядра по тому же (что и в родительском) адресу 0xF0000010. При этом маска доступа и флаги в родительском и дочернем процессах тоже идентичны. Так что, если дочерний процесс в свою очередь породит новый ("внука" по отношению к исходному родительскому), "внук" унаследует данный описатель объекта ядра с теми же значением, нравами доступа и флагами, а счетчик числа пользователей этого объекта ядра вновь увеличится на 1.
| Индекс |
Указатель на блок памяти объекта ядра |
Маска доступа (DWORD с набором битовых флагов) |
Флаги (DWORD с набором битовых флагов) |
| 1 | 0x00000000 | (неприменим) | (неприменим) |
| 2 | 0x00000000 | (неприменим) | (неприменим) |
| 3 | 0xF0000010 | 0х???????? | 0x00000001 |
Наследуются только описатели объектов, существующие на момент создания дочернего процесса. Если родительский процесс создаст после этого новые объекты ядра с наследуемыми описателями, то эти описатели будут уже недоступны дочернему процессу.
Для наследования описателей объектов характерно одно очень странное свойство: дочерний процесс не имеет ни малеЙшего понятия, что он унаследовал какие-то описатсли. Поэтому наследование описятелей объектов ядра полезно, только когда дочерний процесс сообщает, что при его создании родительским процессом он ожидает доступа к какому-нибудь объекту ядра. Тут надо заметить, что обычно родительское и дочернее приложения пишутся одной фирмой, но в принципе дочернее приложение может написать и сторонняя фирма, если в этой программе задокументировано, чего именно она ждет от родительского процесса.
Для этого в дочерний процесс обычно передают значение ожидаемого им описателя объекта ядра как аргумент в командной строке. Инициализирующий код дочернего процесса анализирует командную строку (чаще всего вызовом sscanf), извлекает из нее значение описателя, и дочерний процесс получает неограниченный доступ к объекту.
При этом механизм наследования срабатывает только потому, что значение описателя общего объекта ядра в родительском и дочернем процессах одинаково, — и именно по этой причине родительский процесс может передать значение описателя как аргумент в командной строке.
Для наследственной передачи описателя объекта ядра от родительского процесса дочернему, конечно же, годятся и другие формы межпроцессной сяязи Один из приемов заключается в том, что родительский процесс дожидается окончания инициализации дочернего (через функцию WaitForInputIdle рассматриваемую в главе 9), а затем посылает (синхронно или асинхронно) сообщение окну, созданному потоком дочернего процесса.
Еще один прием: родительский процесс добавляет в свой блок переменных окружения новую переменную Она должна быть "узнаваема" дочерним процессом и содержать значение наследуемого описятеля объекта ядра, Далее родительский процесс создает дочерний, тот наследует переменные окружения родительского процесса и, вызвав GetEnvironmentVariable, получает нужный описатель. Такой прием особенно хорош, когда дочерний процесс тоже порождает процессы, — ведь все переменные окружения вновь наследуются.
Изменение флагов описателя
Иногда встречаются ситуации, в которых родительский процесс создает объект ядра с наследуемым описателем, а затем порождает два дочерних процесса. Но наследуемый описатель нужен только одному из них. Иначе говоря, время от времени возникает необходимость контролировать, какой из дочерних процессов наследует описатели объектов ядра. Для этого модифицируйте флаг наследования, связанный с описателем, вызовом SetHandleInformation:
BOOL SetHandleInformation(
HANDLE hObject,
DWORD dwMask,
DWORD dwFlags);
Как видите, эта функция принимает три параметра. Первый (bObject) идентифицирует допустимый описатель. Второй (dwMask) сообщает функции, какой флаг (или флаги). Вы хотите изменить. На сегодняшний день с каждым описателем связано два флага:
#define HANDLE FLAG_INHtRIT 0x00000001
#define HANDLE FLAG PROTECT FROM CLOSE 0x00000002
Чтобы изменить сразу все флаги объекта, нужно объединить их побитовой операцией OR.
И, наконец, третий параметр функции SetHandleInformation — dwFlags — указывает, в какое именно состояние следует перевести флаги. Например, чтобы установить флаг наследования для описателя объекта ядра:
SetHandleInformation(hobj, HANDLE_FLAG_INHERIT, HANDLE_FLAG_INHERIT);
а чтобы сбросить этот флаг:
SetHandleInformation(hobj, HANDLE_FLAG_INHERIT, 0);
Флаг HANDLE_FLAGPROTECT_FROM_CLOSE сообщает системе, что данный описатель закрывать нельзя:
SetHandleInformation(hobj, HANDLE_FLAG_PROTECT_FROM_CLOSE, HANDLE_FLAG_PROTECT_FROM_CLOSE);
CloseHandle(hobj); // генерируется исключение
Если какой-нибудь поток попытается закрыть защищенный описатель, CloseHandle приведет к исключению. Необходимость в такой защите возникает очень редко. Однако этот флаг весьма полезен, когда процесс порождает дочерний, а тот в свою очередь — еще один процесс. При этом родительский процесс может ожидать, что его "внук" унаследует определенный описатель объекта, переданный дочернему. Но тут вполне возможно, что дочерний процесс, прежде чем породить новый процесс, закрывает нужный описатель. Тогда родительский процесс теряет связь с "внуком", поскольку тот не унаследовал требуемый объект ядра. Защитив описатель от закрытия, Вы исправите ситуацию, и "внук" унаследует предназначенный ему объект.
У этого подхода, впрочем, есть один недостаток. Дочерний процесс, вызвав:
SetHandleInformation(hobj, HANDLEMFLAG_PROlECl_FROM_CLOSE, 0);
CloseHandle(hobj);
может сбросить флаг HANDLE_FLAG_PROTECT_FROM_CLOSE и закрыть затем соответствующий описатель. Родительский процесс ставит на то, что дочерний не исполнит этот код. Но одновременно он ставит и на то, что дочерний процесс породит ему "внука", поэтому в целом ставки не слишком рискованны.
Для полноты картины стоит, пожалуй, упомянуть и функцию GetHandleInformation:
BOOL GetHandleInformation(
HANDLE hObj,
PDWORD pdwFlags);
Эта функция возвращает текущие флаги для заданного описателя в переменной типа DWORD, на которую укапывает pdwFlags.Чтобы проверить, является ли описатель наследуемым, сделайте так:
DWORD dwFlags;
GetHandleInformation(hObj, &dwFlags);
BOOL fHandleIsInheritable = (0 != (dwFlags & HANDLE_FLAG_INHERIT));
Некоторые полезные примеры
Допустим, Вы хотите создать отказоустойчивое приложение, которое должно рабо тать 24 часа в сутки и 7 дней в неделю. В наше время, когда программное обеспече ние настолько усложнилось и подвержено влиянию множества непредсказуемых фак торов, мне кажется, что без SEH просто нельзя создать действительно надежное при ложение. Возьмем элементарный пример, функцию strcpy из библиотеки С:
char* strcpy(char* strDestination, const char* strSource);
Крошечная, давно известная и очень простая функция, да? Разве она может выз вать завершение процесса? Ну, если в каком-нибудь из параметров будет передан NULL (или любой другой недопустимый адрес), strcpy приведет к нарушению доступа, и весь процесс будет закрыт.
Создание абсолютно надежной функции strcpy возможно только при использова нии SEH
char* RobustStrCpy(char* strDestination, const char* strSource)
{
__try
{
strcpy(strDestination, strSource);
}
except (EXCEPTION_EXECUTE_HANDLER)
{
// здесь ничего на делаем
}
return(strDestination);
}
Все, что делает эта функция, — помещает вызов strcpy в SEH-фрейм. Если вызов strcfiy приходит успешно, RobustStrCpy просто возвращает управление. Если же strcpy генерирует нарушение доступа, фильтр исключений возвращает значение EXCEP TION_EXECIITE_HANDLER, которое заставляет поток выполнить код обработчика. В функции RobublStrCpy обработчик не делает ровным счетом ничего, и опягь Robust StrCpy просто возвращает управление. Но она никогда не приведет к аварийному за вершению процесса1
Рассмотрим другой пример. Вот функция, которая сообщает число отделенных пробелами лексем в строке.
int RobustHowManyToken(const char* str)
{
int nHowManyTokens = -1,
// значение, равное -1, сообщает о неудаче
char* strTemp = NULL;
// предполагаем худшее
__try
{
// создаем временный буфер
strTemp = (char*) malloc(strlen(str) + 1);
// копируем исходную строку во временный буфер
strcpy(strTemp, str);
// получаем первую лексему
char* pszToken = strtok(strTemp, " ");
// перечисляем все лексемы
for (; pszToken != NULL; pszToken = strtok(NULL, " ")) nHowManyTokens++;
nHowManyTokens++; // добавляем 1, так как мы начали с -1
}
__except (EXCEPTION_EXECUTE_HANDLER}
{
// здесь ничего не делаем
}
// удаляем временный буфер (гарантированная операция)
free(strTemp);
return(nHowManyTokens);
}
Эта функция создает временный буфер и копирует в нсго строку. Затем, вызывая библиотечную функцию strtok, она разбирает строку на отдельные лексемы. Времен ный буфер необходим из-за того, что strtok модифицирует анализируемую строку.
Благодаря SEH эта обманчиво простая функция справляется с любыми неожидан ностями. Давайте посмотрим, как она работает в некоторых ситуациях
Во-первых, если ей передастся NULL (или любой другой недопустимый адрес), переменная nHowManyTokens сохраняет исходное значение -1. Вызов strlen внутри блока try приводит к нарушению доступа. Тогда управление передается фильтру ис ключений, а от него — блоку except, который ничего не делает. После блока except вызывается free, чтобы удалить временный буфер в памяти. Однако он не был создан, и в данной ситуации мы вызываем/гее с передачей ей NULL Стандарт ANSl С допус кает вызов/me с передачей NULL, в каковом случае эта функция просто возвращает управление, так что ошибки здесь нет. В итоге RobustHowManyToken возвращает зна чение -1, сообщая о неудаче, и аварийного завершения процесса нс происходит,
Во-вторых, если функция получает корректный адрес, но вызов malloc (внутри блока try) заканчивается неудачно и дает NULL, то обращение к strcpy опять приво дит к нарушению доступа. Вновь активизируется фильтр исключений, выполняется блок ехсерг (который ничего не делает), вызывается free с передачей NULL (из-за чего она тоже ничего не делает), и RobustHowManyToken возвращает -1, сообщая о неуда че. Аварийного завершения процесса не происходит.
Наконец, допустим, что функции передан корректный адрес и вызов malloc про шел успешно. Тогда преуспеет и остальной код, а в переменную nHowManyTokens бу дет записано число лексем в строке, В этом случае выражение в фильтре исключений (в конце блока try) не оценивается, код в блоке except не выполняется, временный буфер нормально удаляется, и nHowManyTokens сообщает количество лексем в строке.
Функция RobustHowManyToken демонстрирует, как обеспечить гарантированную очистку ресурса, не прибегая к try-finally. Также гарантируется выполнение любого кода, расположенного за обработчиком исключения (если, конечно, функция не воз вращает управление из блока try, но таких вещей Вы должны избегать)
Атеперь рассмотрим последний, особенно полезный пример использования SEH. Вот функция, которая дублирует блок памяти:
PBYTE RobustMemDup(PBYTE pbSrc, size_t cb)
{
PBYTE pbDup = NULL;
// заранее предполагаем неудачу
__try
{
// создаем буфер для дублированного блока памяти
pbDup = (PBYTE) malloc(cb);
memcpy(pbDup, pbSrc, cb);
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
free(pbDup);
pbDup = NULL;
}
return(pbDup);
}
Эта функция создает буфер в памяти и копирует в него байты из исходного бло ка. Затем она возвращает адрес этого дубликата (или NULL, если вызов закончился неудачно). Предполагается, что буфер освобождается вызывающей функцией — ког да необходимость в нем отпадает Это первый пример, где в блоке except понадобится какой-то код. Давайте проанализируем работу этой функции в различных ситуациях.
• Если в пираметр pbSrc передается некорректный адрес или если вызов malloc завершается неудачно (и дает NULL), memcpy возбуждает нарушение доступа А это приводит к выполнению фильтра, который передает управление блоку except. Код в блоке except освобождает буфер памяти и устанавливает pbDup в NULL, чтобы вызвавший эту функцию поток узнал о cc неудачном завершении. (Не забудьте, что стандарт ANSI С допускает передачу NULL функции free.)
• Если в параметрер pbSrc передается корректный адрес и вызов malloc проходит успешно, функция возвращает адрес только что созданного блока памяти
Некоторые соображения по библиотеке С/С++
Microsoft поставляет с Visual С++ шесть библиотек С/С++. Их краткое описание представлено в следующей таблице.
|
Имя библиотеки |
Описание | ||
|
LibC.lib |
Статически подключаемая библиотека для однопоточных приложений | ||
|
LibCD.lih |
Отладочная версия статически подключаемой библиотеки для однопо | ||
|
LibCMt.lib |
Статически подключаемая библиотека для многопоточных приложений | ||
|
LibCMtD.lib |
Отладочная версия статически подключаемой библиотеки для много | ||
|
MSVCRt.lib |
Библиотека импорта для динамического подключения рабочей версии | ||
|
MSVCRtD.lib |
Библиотека импорта дли динамического подключения отладочной версии MSVCRtD.dll; поддерживает как одно-, так и многопоточные приложения |
При реализации любого проекта нужно знать, с какой библиотекой его следует связать. Конкретную библиотеку можно выбрать в диалоговом окне Project Settings: на вкладке С/С++ в списке Category укажите Code Generation, а в списке Use Run-Time Library — одну из шести библиотек.
Наверное, Вам уже хочется спросить: "А зачем мне отдельные библиотеки для однопоточных и многопоточных программ?" Отвечаю. Стандартная библиотека С была разработана где-то в 1970 году — задолго до появления самого понятия многопоточности. Авторы этой библиотеки, само собой, не задумывались о проблемах, связанных с многопоточными приложениями.
Возьмем, к примеру, глобальную переменную errno из стандартной библиотеки С. Некоторые функции, если происходит какая-нибудь ошибка, записывают в эту переменную соответствующий код. Допустим, у Вас есть такой фрагмент кода:
BOOL fFailure = (system("NOTEPAD.EXE README.TXT") == -1);
if (fFailure)
{
switch (errno)
{
case E2BIG:
// список аргументов или размер окружения слишком велик
break;
case ENOENT:
// командный интерпретатор не найден
break;
case ENOEXEC;
// неверный формат командного интерпретатора
break;
case ENOMEM:
// недостаточно памяти для выполнения команды
break;
}
Теперь представим, что поток, выполняющий показанный выше код, прерван после вызова функции system и до оператора if.
Допустим также, поток прерван для выполнения другого потока (в том же процессе), который обращается к одной из функций библиотеки С, и та тоже заиосит какое то значение в глобальную переменную errno. Смотрите, что получается когда процессор вернется к выполнению первого потока, в переменной errno окажется вовсе не то значение, которое было записано функцией system. Поэтому для решения этой проблемы нужно закрепить за каждым потоком свою переменную errno. Кроме того, понадобится какой-то механизм, который позволит каждому потоку ссылаться на свою переменную errno и не трогать чужую.
Это лишь один пример того, что стандартная библиотека С/С++ не рассчитана на многопоточные приложения. Кроме errno, в ней есть еще целый ряд переменных и функций, с которыми возможны проблемы в многопоточной среде _doserrno, strtok, _wcstok, strerror, _strerror, tmpnam, tmpfile, a<tcttme, _wascttme, gmttme, _ecvt, _Jcvt - список можно продолжить.
Чтобы многопоточные программы, использующие библиотеку С/С++, работали корректно, требуется создать специальную структуру данных и связать ее с каждым потоком, из которого вызываются библиотечные функции. Более того, они должны знать, что, когда Вы к ним обращаетесь, нужно просматривать этот блок данных в вызывающем потоке чтобы не повредить данные в каком-нибудь другом потоке.
Так откуда же система знает, что при создании нового потока надо создать и этот блок данных3. Ответ очень прост - не знает и знать не хочет. Вся ответственность — исключительно на Вас. Если Вы пользуетесь небезопасными в многопоточной среде функциями, то должны создавать потоки библиотечной функцией _begmthreadex, а не Windows-функцией CreateThread.
unsigned long _beginthreadex( void *secunty unsigned stack size unsigned (*start_address)(void *) void *arglist unsigned initflag unsigned *thrdaddr)
У функции _beginthreadGX тот же список параметров, что и у CreateThread, но их имена и типы несколько отличаются. (Группа, которая отвечает в Microsoft за разработку и поддержку библиотеки С/С++, считает, что библиотечные функции не должны зависеть от типов данных Windows).
Как и CreateTbread, функция _beginthreadex возвращает описатель только что созданного потока. Поэтому, если Вы раньше пользовались функцией CreateThread, её вызовы в исходном коде несложно заменить на вызовы _begtnthreadex. Однако из-за некоторого расхождения в типах данных Вам придется позаботиться об их приведении к тем, которые нужны функции _begin threadex, и тогда компилятор будет счастлив. Лично я создал небольшой макрос chBEGINTHREADEX, который и делает всю эту работу в исходном коде:
typedef unsigned ( stdcall *PTHREAD START) (void *)
#define chBEGINTHREADEX(psa cbStack pfnStartAddr \
pvParam fdwCreate pdwThreadID) \
((HANDLE) _beginthreadex( \
(void *) (psa) \
(unsigned) (cbStack), \
(PTHREAD_START) (pfnStartAddr) \
(void *) (pvParam) \
(unsigned) (fdwCreate) \
(unsigned *) (pdwThreadID)))
Заметьте, что функция _beginthreadex существует только в многопоточных версиях библиотеки С/С++. Связав проект с однопоточной библиотекой, Вы получите от компоновщика сообщение об ошибке "unresolved external symbol". Конечно, это сделано специально, потому что однопоточная библиотека не может корректно работать в многопоточном приложении. Также обратите внимание на то, что при создании нового проекта Visual Studio по умолчанию выбирает однопоточную библиотеку. Этот вариант не самый безопасный, и для многопоточных приложений Вы должны сами выбрать одну из многопоточных версий библиотеки С/С++.
Поскольку Microsoft поставляет исходный код библиотеки С/С++, несложно разобраться в том, что такого делает _beginthreadex, чего не делает CreateThread. На дистрибутивном компакт-диске Visual Studio ее исходный код содержится в файле Threadex.c. Чтобы не перепечатывать весь код, я решил дать Вам её версию в псевдокоде, выделив самые интересные места.
unsigned long _cdocl _beginthreadex ( void *psa, unsigned cbStack,
unsigned (__stdcall * pTnStartAddr) (void *), void *pvParam, unsigned fdwCreate, unsigned *pdwThreadID)
{
_ptiddata ptd;
// указатель на блок данных потока unsigned long thdl,
// описатель потока
// выделяется блок данных для нового потока
if ((ptd = _calloc_crt(1, sizeof(struct tiddata))) == NULl)
goto error_returnж
// инициализация блока данных
initptd(ptd);
// здесь запоминается нужная функция потока и параметр,
// который мы хотим поместить в блок данных
ptd->_initaddr = (void *) pfnStartAddr;
ptd->_initarg = pvParam;
// создание Honoio потока
thdl = (unsigned long)
CreateThread(psa, cbStack, _threadstartex, (PVOID) ptd, fdwCreate, pdwThrcadID);
if (thdl == NULl) {
// создать поток не удалось, проводится очистка и сообщается об ошибке
goto error_return;
}
// поток успешно создан; возвращается его описатель
return(thdl);
error_return:
// ошибка! не удалось создать блок данных или сам поток
_free_crt(ptd);
return((unsigned long)0L);
}
Несколько важных моментов, связанных с _beginthreadex
Каждый поток получает свой блок памяти tiddata, выделяемый из кучи, которая принадлежит библиотеке С/C++. (Структура tiddata определена в файле Mtdll h. Она довольно любопытна, и я привел ее на рис 6-2.) Адрес функции потока, переданный _beginthreadex, запоминается в блоке памяти tiddata. Там же сохраняется и параметр, который должен быть передан этой функции. Функция _beginthreadex вызывает CreateThread, так как лишь с ее помощью операционная система может создать новый поток. При вызове CreateThread сообщается, что она должна начатъ выполнение нового потока с функции _threadstartex, а не с того адреса, на который указывает fnStartAddr. Кроме того, функции потока передается не параметр рvParam, а адрес структуры tiddata. Если все проходит успешно, beginthreadex, как и CreateThread, возвращает описатель потока. В ином случае возвращается NULL.
struct tiddata
{
unsigned long _tid; /* идентификатор потока */
unsigned long _thandle; /* описатель потока */
int terrno; /* значение errno */
unsigned long tdoserrno; /* значение _doserrno */
unsigned int _fpds; /* сегмент данных Floating Point */
unsigned lonq _holdrand; /* зародышевое значение для rand() */
char * _token; /* указатель (ptr) на метку strtok() */
#ifdef _WIN32
wchar_t *_wtoken; /* ptr на метку wcstok() */
#endif /* _WIN32 */
unsigned char * _mtoken; /* ptr на метку _mbstok() */
/* следующие указатели обрабатываются функцией malloc в период выполнения */
char * _errmsg; /* ptr на буфер strerror()/_strerror() */
char * _namebuf0; /* ptr на буфер tmpnam() */
#ifdef _WIN32
wchar_t * _wnarnebuf0; /* ptr на буфер_wtmpnam() */
#endif /* _WIN32 */
char * _namebuf1 /* ptr на буфер tmpfile() */
#ifdef _WIN32
wchar_t * _wnamebuf1; /* ptr ма буфер wTmpfi]e() */
#endif /* _WIN32 */
char * _asctimebuf; /* ptr на буфер asctime() */
#ifdef _WIN32
wchar_t * _wasctimebuf; /* ptr на буфер _wasctime() */
#endif /* _WIN32 */
void * _gmtimebuf; /* ptr на структуру gmtime() */
char * _cvtbuf; * /* ptr на буфер ecvt()/fcvt */
/* следующие поля используются кодом _beginthread */
void * _initaddr; /* начальный адррс пользовательское потока */
void * _initarg; /* начальный аргумент пользовательского потока */
/* следующие три поля нужны для поддержки функции signal и обработки ошибок, возникающих в период выполнения */
void * _pxcptaottab; /* ptr на таблицу исключение-действие */
void * _tpxcptaofoptrs; /* ptr на указагели к информации об исключении */
int _tfpecode; /* код исключения для операций над числами с плавающей точкой */
/* следующее поле нужно подпрограммам NLG */
unsigned long _NLG_dwCode;
/* данные для отдельного потока используемые при обработке исключений в С++ */
void * _terminate; /* подпрограмма terminate() */
void * _unexpected; /* подпрограмма unexpected() */
void * _translator; /* транслятор S E */
void * _curexception; /* текущее исключение */
void * _curcontext; /* контекст текущего исключения */
#if defined (_M_MRX000)
void * _pFrameInfoChain;
void * _pUnwindContext;
void * _pExitContext,
int _MipsPtdDelta;
int _MipsPtdEpsilon;
#elif defined (_M_PPC)
void * __pExitContext;
void * _pUnwindContext;
void * _pFrameInfoChain;
int _FrameInfo[6];
#endif /* defined (_M_PPC) */
};
typedef struct _tiddata * _ptiddata;
Рис. 6-2. Локальная структура tiddata потока, определенная в библиотеке С/С++
Выяснив, как создается и инициализируется структура tiddata для нового потока, посмотрим, как она сопоставляется с этим потоком. Взгляните на исходный код функции _threadstartex (который тоже содержится в файле Threadex с библиотеки С/С++). Вот моя версия этой функции в псевдокоде:
static unsigned long WINAPI threadstartex (void* ptd)
{
// Примечание ptd - это адрес блока tiddata данного потока
// блок tiddata сопоставляется с данным потоком
TlsSetValue( __tlsindex ptd);
// идентификатор этого потока записывается в tiddata
((_ptiddata) ptd)->_tid = GetCurrentThreadId();
// здесь инициализируется поддержка операций над числами с плавающей точкой
// (код не показан)
// пользовательская функция потока включается в SEH-фрейм для обработки
// ошибок периода выполнения и поддержки signal
__try
{
// здесь вызывается функция потока, которой передается нужный параметр;
// код завершения потока передается _endthreadex
_endthreadex( ( (unsigned (WINAPI *)(void *))(((_ptiddata)ptd)->_initaddr) ) ( ((_ptiddata)ptd)->_initarg ) ) ;
}
_except(_XcptFilter(GetExceptionCode(), GetExceptionInformation()))
{
// обработчик исключений из библиотеки С не даст нам попасть сюда
_exit(GetExceptionGode());
}
// здесь мы тоже никогда не будем, так как в этой функции поток умирает
return(0L);
}
Несколько важных моментов, связанных со _threadstartex.
Новый поток начинает выполнение с BaseThreadStart (в Kernel32.dll), а затем переходит в _threadstartex. В качестве единственного параметра функции _threadstartex передается адрес блока tiddata нового потока. Windows-функция TlsSetValue сопоставляет с вызывающим потоком значение, которое называется локальной памятью потока (Thread Local Storage, TLS) (о ней я расскажу в главе 21), a _threadstartex сопоставляет блок tiddata с новым потоком. Функция потока заключается в SEH-фрейм. Он предназначен для обработки ошибок периода выполнения (например, не перехваченных исключений С++), поддержки библиотечной функции signal и др.
Этот момент, кстати, очень важен. Если бы Вы создали поток с помощью CreateThread, а потом вызвали библиотечную функцию signal, она работала бы некорректно. Далее вызывается функция потока, которой передается нужный параметр. Адрес этой функции и ее параметр были сохранены в блоке tiddata функцией _beginthreadex. Значение, возвращаемое функцией потока, считается кодом завершения этого потока. Обратите внимание: _threadstartex не возвращается в BaseThreadStart. Иначе после уничтожения потока его блок tiddata так и остался бы в памяти. А это привело бы к утечке памяти в Вашем приложении. Чтобы избежать этого, threadstartex вызывает другую библиотечную функцию, _endthreadex, и передает ей код завершения.
Последняя функция, которую нам нужно рассмотреть, — это _endthreadex (ее исходный код тоже содержится в файле Threadex.c). Вот как она выглядит в моей версии (в псевдокоде).
void _cdecl _endthreadex (unsigned retcode)
{
_ptiddata ptd;
// указатель на блок данных потока
// здесь проводится очистка ресурсов, выделенных для поддержки операций
// над числами с плавающей точкой (код не показан)
// определение адреса блока tiddata данного потока
ptd = _getptd();
// высвобождение блока tiddata
_freeptd(ptd);
// завершение потока
ExitThread(retcode);
}
Несколько важных моментов, связанных с _endthreadex.
Библиотечная функция _getptd обращается к Windows-функции TlsGetValue, которая сообщает адрес блока памяти tiddata вызывающего потока. Этот блок освобождается, и вызовом ExttThread поток разрушается. При этом, конечно, передается корректный код завершения.
Где-то в начале главы я уже говорил, что прямого обращения к функции ExitThread следует иpбегать. Это правда, и я не отказываюсь от своих слов. Тогда же я сказал, что это приводит к уничтожению вызывающего потока и не позволяет ему вернуться из выполняемой в данный момент функции. А поскольку она не возвращает управление, любые созданные Вами С++-объекты не разрушаются. Так вот, теперь у Вас есть еще одна причина не вызывать ExitThread, она не дает освободить блок памяти tiddata потока, из-за чего в Вашем приложении может наблюдаться утечка памяти (до его pавершения).
Разработчики Microsoft Visual C++, конечно, прекрасно понимают, что многие все равно будут пользоваться функцией ExitThread, поэтому они кое-что сделали, чтобы свести к минимуму вероятность утечки памяти. Если Вы действительно так хотите самостоятельно уничтожить свой поток, можете вызвать из него _endthreadex (вместо ExitTbread) и тем самым освободить его блок tiddata. И все же я не рекомендую этого.
Сейчас Вы уже должны понимать, зачем библиотечным функциям нужен отдельный блок данных для каждого порождаемого потока и каким образом после вызова _beginthreadex происходит создание и инициализация этого блока данных, а также его связывание с только что созданным потоком. Кроме того, Вы уже должны разбираться в том, как функция _endthreadex освобождает этот блок по завершении потока.
Как только блок данных инициализирован и сопоставлен с конкретным потоком, любая библиотечная функция, к которой обращается поток, может легко узнать адрес его блока и таким образом получить доступ к данным, принадлежащим этому потоку.
Ладно, с функциями все ясно, теперь попробуем проследить, что происходит с глобальными переменными вроде errno. В заголовочных файлах С эта переменная определена так:
#if defined(_MT) || defined(_DLL)
extern int * _cdecl _errno(void);
#define errno (*_еггпо())
#else /* ndef _MT && ndef _DLL */
extern int errno;
#endif /* MT | | _DLL */
Создавая многопоточное приложение, надо указывать в командной строке ком пилятора один из ключей /MT (многопоточное приложение) или /MD (многопоточная DLL); тогда компилятор определит идентификатор _MT. После этого, ссылаясь на errno, Вы будете на самом деле вызывать внутреннюю функцию _errno из библиотеки С/С++. Она возвращает адрес элемента данных errno в блоке, сопоставленном с вызывающим потоком. Кстати, макрос errno составлен так, что позволяет получать co держимое памяти по этому адресу. А сделано это для того, чтобы можно было писать, например, такой код:
int *p = &errno;
if (*p == ENOMEM){
...
}
Если бы внутренняя функция _errno просто возвращала значение errno, этот код не удалось бы скомпилировать.
Многопоточная версия библиотеки С/С++, кроме того, "обертывает" некоторые функции синхронизирующими примитивами. Ведь если бы два потока одновременно вызывали функцию malloc, куча могла бы быть повреждена. Поэтому в многопоточной версии библиотеки потоки не могут одновременно выделять память из кучи. Второй поток она заставляет ждать до тех пор, пока первый не выйдет из функции malloc, и лишь тогда второй поток получает доступ к malloc. (Подробнее о синхрони зации потоков мы поговорим в главах 8, 9 и 10.)
Конечно, все эти дополнительные операции не могли не отразиться на быстро действии многопоточной версии библиотеки. Поэтому Microsoft, кроме многопоточной, поставляет и однопоточную версию статически подключаемой библиотеки С/С++.
Динамически подключаемая версия библиотеки С/С++ вполне универсальна ее могут использовать любые выполняемые приложения и DLL, которые обращаются к библиотечным функциям. По этоЙ причине данная библиотека существует лишь в многопоточной версии. Поскольку она поставляется в виде DLL, ее код не нужно включать непосредственно в EXE- и DLL-модули, что существенно уменьшает их размер. Кроме того, если Microsoft исправляет какую-то ошибку в такой библиотеке, то и программы, построенные на ее основе, автоматически избавляются от этой ошибки.
Как Вы, наверное, и предполагали, стартовый код из библиотеки С/С++ создает и инициализирует блок данных для первичного потока приложения. Это позволяет без всяких опасений вызывать из первичного потока любые библиотечные функции. А когда первичный поток заканчивает выполнение своей входной функции, блок данных завершаемого потока освобождается самой библиотекой. Более того, стартовый код делает все необходимое для сгруктурной обработки исключений, благодаря чему из первичного потока можно спокойно обращаться и к библиотечной функции signal.
Несколько полезных приемов
Используя критические секции, желательно привыкнуть делать одни вещи и избегать других. Вот несколько полезных приемов, которые пригодятся Вам в работе с критическими секциями. (Они применимы и к синхронизации потоков с помощью объектов ядра, о которой я расскажу в следующей главе.)
На каждый разделяемый ресурс используйте отдельную структуру CRITICAL_SECTION
Если в Вашей программе имеется несколько независимых структур данных, создавайте для каждой из них отдельный экземпляр структуры CRITICAL_SECTION. Это лучше, чем защищать все разделяемые ресурсы одной критической секцией. Посмотрите на этот фрагмент кода:
int g_nNums[100]; // один разделяемый ресурс
TCHAR g_cChars[100]; // Другой разделяемый ресурс
CRITICAL_SECTION g_cs, // защищает оба ресурса
DWORD WINAPI ThreadFunc(PVOID pvParam)
{ EnterCriticalSection(&g_cs);
for (int x = 0; x < 100: x++)
{
g_nNums[x] = 0;
g_cChars|x] - TEXT('X');
}
LeaveCriticalSection(&g_cs);
return(0);
}
Здесь создана единственная критическая секция, защищающая оба массива — g_nNums и g_cChars - в период их инициализации. Но эти массивы совершенно различны. И при выполнении данного цикла ни один из потоков не получит доступ ни к одному массиву. Теперь посмотрим, что будет, если ThreadFunc реализовать так:
DWORD WINAPI ThreadFunc(PVOID pvParam)
{
EnterCriticalSection(&g_cs);
for (int x = 0; x < 100; x++)
g_nNums[x] = 0;
for (x = 0; x < 100; x++)
g_cChars[x] = TEXT('X');
LeaveCriticalSection(&g_cs);
return(0);
}
В этом фрагменте массивы инициализируются по отдельности, и теоретически после инициализации g_nNums посторонний поток, которому нужен доступ только к первому массиву, сможет начать исполнение — пока ThreadFunc занимается вторым массивом. Увы, это невозможно: обе структуры данных защищены одной критической секцией. Чтобы выйти из затруднения, создадим две критические секции:
int g_nNum[100]; // разделяемый ресурс
CRITICAL_SECTION g_csNums; // защищает g_nNums
TCHAR g_cChars[100]; // другой разделяемый ресурс
CRITICAL_SECTION g_csChars; // защищает g_cChars
DWORD WTNAPT ThreadFunc(PVOTD pvParam)
{
EnterCriticalSection(&g_csNums);
for (int x = 0; x < 100; x++)
g_nNums[x] = 0;
LeaveCriticalSection(&g_csNums);
EnterCriticalSection(&g_csChars);
for (x = 0; x < 100; x++)
g_cChars[x] = TEXT('X');
LeaveCriticalSection(&g_ csChars);
return(0);
}
Теперь другой поток сможет работать с массивом g_nNums, как только ThreadFunc закончит его инициализацию. Можно сделать и так, чтобы один поток инициализировал массив g_nNums, я другой — gcChars.
Одновременный доступ к нескольким ресурсам
Иногда нужен одновременный доступ сразу к двум структурам данных. Тогда ThreadFunc следует реализовать так:
DWORD WINAPI ThreadFunc(PVOID pvParam)
{
EnterCriticalSection(&g_csNums);
EnterCriticalSection(&g_csChars);
// в этом цикле нужен одновременный доступ к обоим ресурсам
for (int x = 0; x < 100; x++)
g_nNums[x] = g_cChars[x];
LeaveCriticalSection(&g_csChars);
LeaveCrilicalSection(&g_csNums};
return(0);
}
Предположим, доступ к обоим массивам требуется и другому потоку в данном процессе; при этом его функция написана следующим образом:
DWORD WINAPI OtherThreadFunc(PVOID pvParam)
{
EnterCriticalSection(&g_csChars);
EnterCriticalSection(&g_csNums);
for (int x = 0; x < 100; x++)
g_nNums[x] = g_cChars[x];
LeaveCriticalSection(&g_csNums);
LeaveCriticalSection(&g_csChars);
return(0);
}
Я лишь поменял порядок вызовов EnterCriticalSection и LeaveCriticalSection. Но из за того, что функции ThreadFunc и OtherThreadFunc написаны именно так, существует вероятность взаимной блокировки (deadlock). Допустим, ThreadFunc начинает исполнение и занимает критическую секцию g_csNums. Получив от системы процессорное время, поток с функцией OtherThreadFunc захватывает критическую секцию g_csChars. Тут-то и происходит взаимная блокировка потоков. Какая бы из функций — ThreadFunc или OtherThreadFunc — ни пыталась продолжить исполнение, она не сумеет занять другую, необходимую ей критическую секцию.
Эту ситуацию легко исправить, написав код обеих функций так, чтобы они вызывали EnterCriticalSection в одинаковом порядке Заметьте, что порядок вызовов Leave CrititalSection несуществен, поскольку эта функция никогда не приостанавливает поток.
Не занимайте критические секции надолго
Надолго занимая критическую секцию, Ваше приложение может блокировать другие потоки, что отрицательно скажется на его общей производительности Вот прием, позволяющий свести к минимуму время пребывания в критической секции. Следующий код не даст другому потоку изменять значение в g_s до тех пор, пока в окно не будет отправлено сообщение WM_SOMEMSG:
SOMESTRUCT g, s;
CRITICAL_SECTION g_cs;
DWORD WINAPI SomeThread(PVOID pvParam)
{
EnterCriticalSection(&g_cs);
// посылаем в окно сообщение
SendMessage(hwndSomeWnd, WM_SOMEMSG, &g_s, 0);
LeaveCriticalSection(&g_cs);
return(0);
}
Трудно сказать, сколько времени уйдет на обработку WM_SOMEMSG оконной процедурой — может, несколько миллисекунд, а может, и несколько лет. В течение этого времени никакой другой поток не получит доступ к структуре g_s. Поэтому лучше составить код иначе:
SOMESTRUCT g_s;
CRITICAL_SECTION g_cs;
DWORO WINAPI SomeThread(PVOID pvParam)
{
EnterCriticalSection(&g_cs);
SOMESTRUCT sTemp = g_s;
LeaveCriticalSection(&g_cs);
// посылаем в окно сообщение
SendMessage(hwndSompWnd, WM_SOMEMSG, &sTemp, 0);
return(0);
}
Этот код сохраняет значение элемента g_t, во временной переменной sTemp. Не трудно догадаться, что на исполнение этой строки уходит всего несколько тактов процессора. Далее программа сразу вызывает LeaveCriticalSection — защищать глобальную структуру больше не нужно. Так что вторая версия программы намного лучше первой, поскольку другие потоки "отлучаются" от структуры g_s лишь на несколько таков процессора, а не на неопределенно долгое время. Такой подход предполагает, что "моментальный снимок" структуры вполне пригоден для чтения оконной процедурой, а также что оконная процедура не будет изменять элементы этой структуры.
Обработка больших файлов
Я обещал рассказать, как спроецировать на небольшое адресное просранство файл длиной 16 экзабайтов. Так вот, этого сделать нельзя Вам придется проецировать не весь файл, а сго представление, содержащее лишь некую часть данных Вы начнете с того, что спроецируете представление самого начала файла Закончив обработку дан ных в этом представлении, Вы отключите его и спроецируете представление следую щей части файла — и так до тсх пор, пока нс будет обработан весь файл Конечно, это делает работу с большими файлами, проецируемыми в память, не слишком удоб ной, но утешимся тем, чго длина большинства файлов достаточно мала
Рассмотрим сказанное на примере файла размером 8 Гб Ниже приведен текст подпрограммы, позволяющей в несколько этапов подсчитывать, сколько раз встреча ется нулевой байт в том или ином двоичном файле данных.
__int64 CountOs(void)
{
// начальные границы представлений всегда начинаются no адресам,
// кратным гранулярности выделения памяти
SYSTEM_INFO sinf;
GetSystemInfo(&sinf);
// открываем файл данных
HANOLE hFile = CreateFile( "С:\\HugeFile.Big , GENERIC_READ, FILE_SHARE_READ NULL, OPEN_EXISTING, FILE_FLAG_SEQUENTIAL SCAN, NULL);
// создаем объект проекция файла
HANDLE hFileMapping = CreateFileMapping(hFile, NULL, PAGE_READONLY, 0, 0, NULL);
DWORD dwFileSizeHigh;
__int64 qwFileSize = GetFileSize(hFile, &dwFileSizeHigh);
qwFileSize += (((__int64) dwFileSizeHigh) << 32);
// доступ к описателю объекта файл нам больше не нужен
CloseHandle(hFile);
__int64 qwFileOffset = 0;
qwNumOfOs = 0;
while (qwFileSize > 0)
{
// определяем, сколько байтов надо спроецировать
DWORD dwBytesInBlock = sinf.dwAllocationGranularity;
if (qwFileSize < sinf.dwAllocationGranularity)
dwBytesInBlock = (DWORD)qwFileSize;
PBYTE pbFile = (PBYTE)MapViewOfFile(hFileMapping, FILE_MAP_READ, (DWORD) (qwFileOffset >> 32), // начальный байт (DWORD) (qwFileOffset & 0xFFFFFFFF), // в файле dwBytesInBlock); // число проецируемых байтов
// подсчитываем количество нулевых байтов в этом блоке
for (DWORD dwByte = 0; dwByte < dwBytesInBlock; dwByte++)
{
if (pbFilfe[dwByte] == 0)
qwNumOfOs++;
}
// прекращаем проецирование представления, чтобы в адресном пространстве
// не образовалось несколько представлений одного файла
UnmapViewOfFiie(pbFile);
// переходим к следующей группе байтов в файле
qwFileOffset += dwBytesInBlock;
qwFileSize -= dwBytesInBlock;
}
CloseHandle(hFileMapping);
return(qwNumOfOs);
}
Этот алгоритм проецирует представления по 64 Кб (в соответствии с грануляр ностью выделения памяти) или менее Кроме того, функция MapViewOfFile требует, чтобы передаваемое ей смещение в файле тоже было кратно гранулярности выделе ния памяти. Подпрограмма проецирует на адресное пространство сначала одно пред ставление, подсчитывает в нем количество нулей, затем переходит к другому пред ставлению, и все повторяется. Спроецировав и просмотрев все 64-килобайтовые бло ки, подпрограмма закрывает объект "проекция файла".
Общая картина
Попробуем разобраться в том, как работают DLL и как опи используются Вами и системой. Начнем с общей картины (рис 19-1).
Для пачала рассмотрим неявное связывание EXE- и DLL-модулей. Неявное связывание (implicit linking) — самый распространенный на сегодняшний день метод (Windows поддерживает и явное связывание, но об этом — в главе 20.)
Как видно на рис 19-1, когда некий модуль (например, EXE) обращается к функциям и переменным, находящимся в DLL, в этом процессе участвует несколько файлов и компонентов. Для упрощения будем считать, что исполняемый модуль (EXE) импортирует функции и переменные из DLL, а DLL-модули, наоборот, экспортируют их в исполняемый модуль. Но учтите, что DLL может (и это не редкость) импортировать функции и переменные из других DLL.
Собирая исполняемый модуль, который импортирует функции и переменные из DLL, Вы должны сначала создать эту DLL. А для этого нужно следующее.
Прежде всего Вы должны подготовить заголовочный файл с прототипами функций, структурами и идентификаторами, экспортируемыми из DLL. Этот файл включается в исходный код всех модулей Вашей DLL. Как Вы потом увидите, этот же файл понадобится и при сборке исполняемого модуля (или модулей), который использует функции и переменные из Вашей DLL. Вы пишете на С/С++ модуль (или модули) исходного кода с телами функций и определениями переменных, которые должны находиться в DLL. Так как эти модули исходного кода не нужны для сборки исполняемого модуля, они могут остаться коммерческой тайной компании-разработчика. Компилятор преобразует исходный код модулей DLL в OBJ-файлы (по одному на каждый модуль). Компоновщик собирает все OBJ-модули в единый загрузочный DLL-модуль, в который в конечном итоге помещаются двоичный код и переменные (глобальные и статические), относящиеся к данной DLL Этот файл потребуется при компиляции исполняемого модуля. Если компоновщик обнаружит, что DLL экспортирует хотя бы одну переменную или функцию, то создаст и LIB-файл. Этот файл совсем крошечный, поскольку в нем нет ничего, кроме списка символьных имен функций и переменных, экспортируемых из DLL.
Этот LIB- файл тоже понадобится при компиляции ЕХЕ-файла.
Создав DLL, можно перейти к сборке исполняемого модуля. Во все модули исходного кода, где есть ссылки на внешние функции, переменные, структуры данных или идентификаторы, надо включить заголовочный файл, предоставленный разработчиком DLL.
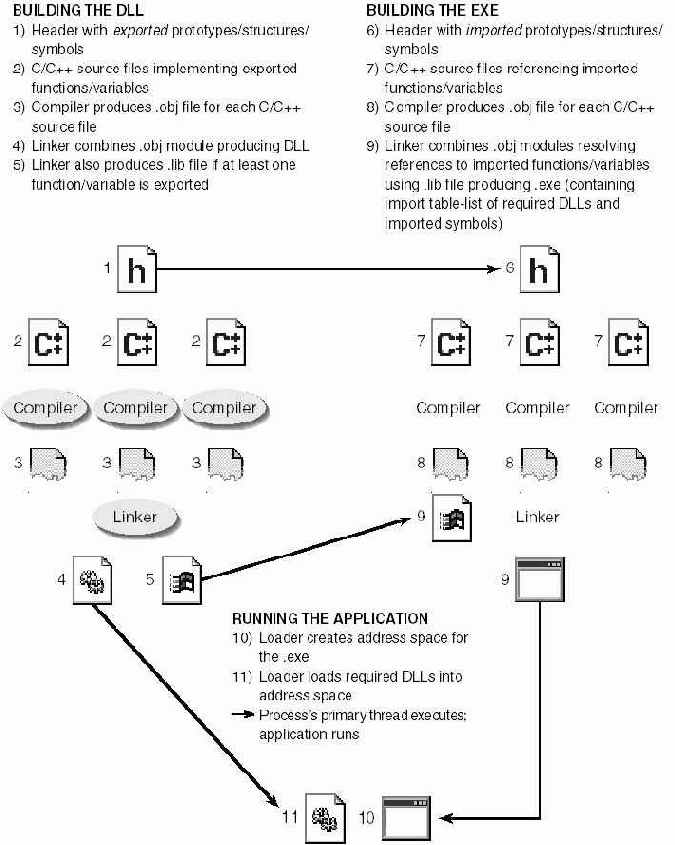
|
СОЗДАНИЕ DLL 1) Заголовочный файл с экспортируемыми прототипами, структурами и идентификаторами (символьными именами) 2) Исходные файлы С/С++ в которых реализованы функции и определены переменные 3) Компилятор создаэт OBJ-файл из каждого исходного файла С/С++ 4) Компоновщик собирает DLL из OBJ-модулей 5) Если DLL экспортирует хотя бы одну переменную или функцию, компоновщик создает и LIB-файл. |
СОЗДАНИЕ ЕХЕ 6) Заголовочный файл с импортируемыми прототипами структурами и идентификаторами 7) Исходные файлы С/С++, из которых вызываются импортируемые функции и переменные 8) Компилятор создает OBJ-файл из каждого исходного файла С/С++. 9) Используя OBJ модули и LIB-файл и учитывая ссылки на импортируемые идентификаторы компоновщик собирает ЕХЕ-модуль (в котором также размещается таблица импорта — список необходимых DLL и импортируемых идентификаторов). |
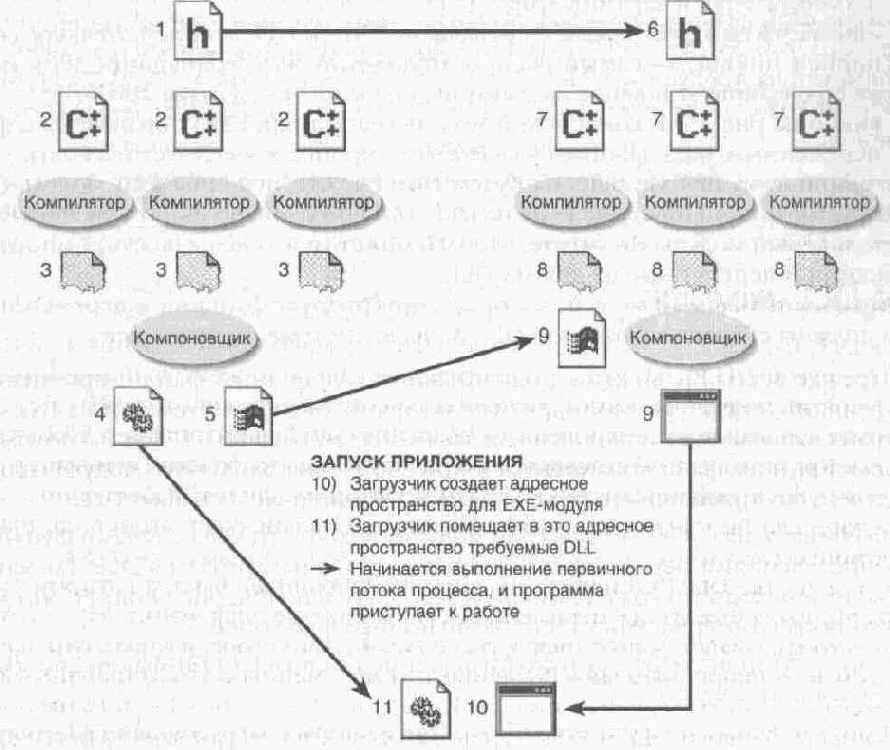
Рис. 19-1. Так DLL создается и неявно связывается с приложением
Вы пишете на С/С++ модуль (или модули) исходного кода с телами функций и определениями переменных, которые должны находиться в ЕХЕ-файле. Естественно, ничто не мешает Вам ссылаться на функции и переменные, определенные в заголовочном файле DLL-модуля. Компилятор преобразует исходный код модулей EXE в OBJ-файлы (по одному на каждый модуль). Компоновщик собирает все OBJ-модули в единый загрузочный ЕХЕ-модуль, в который в конечном итоге помещаются двоичный код и переменные (глобальные и статические), относящиеся к данному EXE. В нем также создается раздел импорта, где перечисляются имена всех необходимых DLL-модулей (информацию о разделах см в главе 17) Кроме того, для каждой DLL в этом разделе указывается, на какие символьные имена функций и переменных ссылается двоичный код исполняемого файла.
Эти сведения потребуются загрузчику операционной системы, а как именно он ими пользуется — мы узнаем чуть позже.
Создав DLL- и ЕХЕ-модули, приложение можно запустить. При его запуске загрузчик операционной системы выполняет следующие операции:
Загрузчик операционной системы создает виртуальное адресное пространство для нового процесса и проецирует на него исполняемый модуль. Далее загрузчик анализирует раздел импорта, находит все необходимые DLL-модули и тоже проецирует на адресное пространство процесса. Заметьте, что DLL может импортировать функции и переменные их другой DLL, а значит, у нее может быть собственный раздел импорта. Заканчивая подготовку процесса к работе, загрузчик просматривает раздел импорта каждого модуля и проецирует все требуемые DLL-модули на адресное пространство этого процесса. Как видите, на инициализацию процесса может уйти довольно длительное время.
После отображения EXE- и всех DLL-модулей на адресное пространство процесса его первичный поток готов к выполнению, и приложение может начать работу. Далее мы подробно рассмотрим, как именно это происходит.
Очередь сообщений потока
Как я уже говорил, одна из главных целей Windows — предоставить всем приложени ям отказоустойчивую среду. Для этого любой поток должен выполняться в такой сре де, где он может считать себя единственным. Точнее, у каждого потока должны быть очереди сообщений, полностью независимые от других потоков. Кроме того, для каж дого потока нужно смоделировать среду, позволяющую ему самостоятельно управлять фокусом ввода с клавиатуры, активизировать окна, захватывать мышь и т. д
Создавая какой-либо поток, система предполагает, что он не будет иметь отноше ния к поддержке пользовательского интерфейса. Это позволяет уменьшшь объем выделяемых ему системных ресурсов. Но, как только поток обратится к той или иной GUI-функции (например, для проверки очереди сообщений или создания окна), сис тема автоматически выделит сму дополнительные ресурсы, необходимые для выпол нения задач, связанных с пользовательским интерфейсом А ссли конкретнее, то сис тема создает структуру THREADINFO и сопоставляет ее с этим потоком
Элементы этой структуры используются, чтобы обмануть поток — заставить его считать, будто он выполняется в среде, принадлежащей только ему. THREADINFO — это внутренняя (недокументированная) структура, идентифицирующая очередь асин хронных сообщений потока (posted-message queue), очередь синхронных сообщений потока (sent-message queue), очередь ответных сообщений (reply-message queue), оче редь виртуального ввода (virtualized input queue) и флаги пробуждения (wakc flags), она также включает ряд других переменных-членов, характеризующих локальное состояние ввода для данного потока На рис 26-1 показаны структуры THREADINFO, сопоставленные с тремя потоками.
Структура THREADINFO — фундамент всей подсистемы передачи сообщений; чи тая следующие разделы, время от времени посматривайте на эту иллюстрацию.
Одно- и двухбайтовые наборы символов
В двухбайтовом наборе символ представляется либо одним, либо двумя байтами. Так, для японской каны, если значение первого байта находится между 0x81 и 0x9F или между 0xE0 и 0xFC, надо проверить значение следующего байта в строке, чтобы определить полный символ. Работа с двухбайтовыми наборами символов — просто кошмар для программиста, так как часть их состоит из одного байта, а часть — из двух.
Простой вызов функции strlen не дает количества символов в строке — она возвращает только число байтов. В ANSI-библиотске С нет функций, работающих с двухбайтовыми наборами символов. Но в аналогичную библиотеку Visual C++ включено множество функций (типа _mbslen), способных оперировать со строками мультибайтовых (как одно-, так и двухбайтовых) символов.
Для работы с DBCS-строками в Windows предусмотрен целый набор вспомогательных функций:
|
Функция |
Описание | ||
|
PTSTR CharNext (PCTSTR pszCurrentChar); |
Возвращает адрес следующего символа в строке | ||
|
PTSTR CharPrep(PCTSTR pszStart, PCTSTR pszCurrentChar); |
Возвращает адрес предыдущего символа в строке | ||
|
BOOL IsDBCSLeadByte (BYTE bTestChar); |
Возвращает TRUE, если данный байт — первый в DBCS-символе |
Функции CharNext и CharPrev появоляют "перемещаться" по двухбайтовой строке единовременно на 1 символ вперед или назад, a IsDBCSLeadByte возвращает TRUE, если переданный ей байт — первый в двухбайтовом символе
Хотя эти функции несколько облегчают работу с DBCS-строками, необходимость в ином подходе очевидна. Перейдем к Unicode.
Ой, вместо _beginthreadex я по ошибке вызвал CreateThread
Вас, наверное, интересует, что случится, если создать поток не библиотечной функцией _begintbreadex, а Windows-функцией CreateThread. Когда этот поток вызовет какую-нибудь библиотечную функцию, которая манипулирует со структурой tiddata, произойдет следующее. (Большинство библиотечных функций реентерабельно и не требует этой структуры.) Сначала эта функция попытается выяснить адрес блока данных потока (вызовом TleGetValue). Получив NULL вместо адреса tiddata, она узнает, что вызывающий поток не сопоставлен с таким блоком. Тогда библиотечная функция тут же создаст и инициализирует блок tiddata для вызывающего потока. Далее этот блок будет сопоставлен с потоком (через TlsSetValue) и останется при нем до тех пор, пока выполнение потока нс прекратится, С этого моменга данная функция (как, впрочем, и любая другая из библиотеки С/С++) сможет пользоваться блоком tiddata потока.
Как это ни фантасгично, но Ваш поток будет работать почти без глюков. Хотя некоторые проблемы все же появятся. Во-первых, если этот поток воспользуется библиотечной функцией signal, весь процесс завершится, так как SEH-фрейм не подготовлен. Во-вторых, если поток завершится, не вызвав endtbreadex, его блок данных не высвободится и произойдет утечка памяти. (Да и кто, интересно, вызовет endthreadex иэ потока, созданного с помощью CreateTbread?)
NOTE:
Если Вы связываете свой модуль с многопоточной DLL версией библиотеки С/С++, то при завершении потока и высвобождении блока tiddata (если он был создан), библиотека получает уведомление DLL_THREAD_DETACH. Даже не смотря на то что это предотвращает утечку памяти, связанную с блоком tiddata, я настоятельно советую создавать потоки через _beginthreadex, а не с помощью CreateTbread.
Описатель экземпляра процесса
Любому EXE- или DLL-модулю, загружаемому в адресное пространство процесса, присваивается уникальный описатель экземпляра. Описатель экземпляра Вашего EXE-файла передается как первый параметр функции (w)WinMain - hinstExe. Это значение обычно требуется при вызовах функций, загружающих те или иные ресурсы. Например, чтобы загрузить из образа ЕХЕ-файла такой ресурс, как значок, надо вызвать:
HICON LoadIcon( HINSTANCE hinst, PCTSTR pszIcori);
Первый параметр в LoadIcon указывает, в каком файле (EXE или DLL) содержится интересующий Вас ресурс. Многие приложения сохраняют параметр hinstExe функции (w)WinMain в глобальной переменной, благодаря чему он доступен из любой части кода ЕХЕ-файла.
В документации Platform SDK утверждается, что некоторые Windows-функции требуют параметр типа HMODULE. Пример — функция GetModuleFileName.
DWORD GetModuleFileName( HMODULE hinstModule, PTSTR pszPath, DWORD cchPath);
NOTE:
Как оказалось, HMODULE и HINSTANCE — это идно и то же. Встретив в документации указание передать какой-то функции HMODULE, смело передавайте HINSTANCE, и наоборот. Они существуют в таком виде лишь потому, что в l6 разрядпой Windows идентифицировали совершенно разные вещи.
Истинное значение параметра hinstExe функции (w)WinMain - базовый адрес в памяти, определяющий ту область в адресном пространстве процесса, куда был загружен образ данного ЕХЕ-файла. Например, если система открывает исполняемый файл и загружает его содержимое по адресу 0x00400000, то hinstExe функции (w)Win Main получает значение 0x00400000.
Базовый адрес, но которому загружается приложение, определяется компоновщи ком. Разные компоновщики выбирают и разные (no умолчанию) базовые адреса. Компоновщик Visual С++ использует по умолчанию базовый адрес 0x00400000 — самый нижний в Windows 98, начиная с которого в ней допускается загрузка образа исполняемого файла. Указав параметр /BASE: адрес (в случае компоновщика от Microsoft), можно изменить базовый адрес, по которому будет загружаться приложение.
При попытке загрузить исполняемый файл в Windows 98 по базовому адресу ниже 0x00400000 загрузчик переместит его на другой адрес. Это увеличит время загрузки приложения, но оно по крайней мере будет выполнено. Если Вы разрабатываете программы и для Windows 98, и для Windows 2000, сделайте так, чтобы приложение загружалось по базовому адресу не ниже 0x00400000. Функция GetModuleHandle.
HMODULE GetModuleHandle( PCTSTR pszModule);
возвращает описатель/базовый адрес, указывающий, куда именно (в адресном пространстве процесса) загружается EXE- или DLL-файл. При вызове этой функции имя нужного EXE- или DLL-файла передается как строка с нулевым символом в конце. Если система находит указанный файл, GetModuleHandle возвращает базовый адрес, по которому располагается образ данного файла. Если же файл системой не найден, функция возвращает NULL. Кроме того, можно вызвать эту функцию, передав ей NULL вместо параметра pszModule, — тогда Вы узнаете базовый адрес EXE-файла. Именно это и делает стартовый код из библиотеки С/С++ при вызове (w)WinMain из Вашей программы.
Есть еще две важные вещи, касающиеся GetModuleHandle. Во-первых, она прове ряет адресное пространство только того процесса, который ее вызвал. Если этот про цесс не использует никаких функций, связанных со стандартными диалоговыми ок нами, то, вызвав GetModuleHandle и передав ей аргумент "ComDlg32", Вы получите NULL - пусть даже модуль ComDlg32.dll и загружен в адресное пространство какого нибудь другого процесса. Во-вторых, вызов этой функции и передача ей NULL дает в результате базовый адрес ЕХЕ-фяйла в адресном пространстве процесса. Так что, вызывая функцию в виде GetModuleHandle(NULL) - даже из кода в DLL, — Вы получаете базовый адрес EXE-, а не DLL-файла.
Описатель предыдущего экземпляра процесса
Я уже говорил, что стартовый код из библиотеки С/С++ всегда передает в функцию (w)WinMain параметр binstExePrev как NULL. Этот параметр предусмотрен исключи тельно для совместимости с 16-разрядными версиями Windows и не имеет никакого смысла для Windows-приложений. Поэтому я всегда пишу заголовок (w)WinMain так:
int WINAPI WinMain(
HINSTANCE hinstExe,
HINSTANCE, PSTR pszCmdLine, int nCmdShow);
Поскольку у второго параметра нет имени, компилятор не выдает предупрежде ние "parameter not referenced" ("нет ссылки на параметр"),
Определение ограничений, налагаемых на процессы в задании
Создав задание, Вы обычно строите "песочницу" (набор ограничений) для включаемых в него процессов. Ограничения бывают нескольких видов:
базовые и расширенные базовые ограничения — не дают процессам в задании монопольно захватывать системные ресурсы; базовые ограничения по пользовательскому интерфейсу (UI) — блокируют возможность его изменения; ограничения, связанные с защитой, — перекрывают процессам в задании доступ к защищенным ресурсам (файлам, подразделам реестра и т.д.).
Ограничения на задание вводятся вызовом:
BOOL SetInformationJobObject( HANDLE hJob, JOBOBJECTINFOCLASS JobObjectInformationClass, PVOID pJobObjectTnformation, DWORD cbJobObjectInformationLength);
Первый параметр определяет нужное Вам задание, второй параметр (перечислимого типа) — вид ограничений, третий — адрес структуры данных, содержащей подробную информацию о задаваемых ограничениях, а четвертый — размер этой структуры (используется для указания версии). Следующая таблица показывает, как устанавливаются ограничения.
| Вид ограничений | Значение второго параметра | Структура, указываемая в третьем параметре | |||
| Базовые ограничения | JobObjectBasicLimitInformation | JOBOBJECT_BASIC_ LIMIT_INFORMATION | |||
| Расширенные базовые ограничения | JobObjectExtendedLimitInformation | JOBOBJECT_EXTENDED_ LIMIT_INFORMATION | |||
| Базовые ограничения по ользовательскому интерфейсу | JobObjectBasicUIRestrictions | JOBOBJECT_BASIC UI_RESTRICTIONS | |||
| Ограничения, связанные с защитой | JobObjectSecurityLimitInformation | JOBOBJECT_SECURITY_ LIMIT_INFORMATION |
В функции StartRestrictedProcess я устанавливаю для задания лишь несколько базовых ограничений. Для этого я создаю структуру JOB_OBJECT_BASIC_LIMIT_INFORMATION, инициализирую ее и вызываю функцию SetInformationJobObject. Данная структура выглядит так:
typedef struct _JOBOBJECT_BASIC_LIMIT_INFORMATION
{
LARGE_INTEGER PerProcessUserTimeLimit;
LARGE_INTEGER PorJobUserTimeLimit;
DWORD LimitFlags;
DWORD MinimumWorkingSetSize;
DWORD MaximumWorkingSetSize;
DWORD ActiveProcessLimit;
DWORD^PTR Affinity;
DWORD PriorityClass;
DWORD SchedulingClass;
} JOBOBJECT_BASIC_LIMIT_INFORMATION, *PJOBOBJECT_BASIC_LIMIT_INFORMATION;
Все элементы этой структуры кратко описаны в таблице 5-1.
| Элементы | Описание | Примечание |
| PerProcessUserTtmeLimit | Максимальное время в пользова тельском режиме, выделяемое каждому процессу (в порциях по 100 нс) | Система автоматически завершает любой процесс, который пытается использовать больше обведенного времени. Это ограничение вводится флагом JOB OBJECT LIMIT PROCESS_TIME в LimitFlags |
| PerJobUserTimeLimit | Максимальное время в пользова тельском режиме для всех процессов в данном задании (в порциях по 100 нс) | По умолчанию система автомати чески завершает все процессы, когда заканчивается это время Данное значение можно изменять в процес ее выполнения задания. Это ограничение вводится флагом JOB_OBJFCT_LIMIT_JOB_TIME в LimitFlags |
| LimitFlags | Виды ограничений для задания | См раздел после таблицы. |
| MinimumWorkingSetSize и MaximumWorkingSetSize | Верхний и нижний предел рабочего набора для каждого процесса (а не для всех процессов в задании) |
Обычно рабочий набор процесса может расширяться за стандартный предел; указав MaximumWorkingSetSize, Вы введете жесткое ограничение. Когда размер рабочего набора какого-либо процесса достигнет заданного предела, процесс начнет сбрасывать свои страницы на диск. Вызовы функции SetProcessWorkingSetSize этим процессом будут игнорироваться, если только он не обра щается к ней для того, чтобы очистить свой рабочий набор. Это ограничение вводится флагом JOB_OBJECT_LIMIT_WORKINGSET в LimitFlags. |
| ActiveProcessLimit | Максимальное количество процессов, одновременно выполняемых в задании | Любая попьпка обойти такое ограничение приведет к завершению нового процесса с ошибкой "not enough quota" ("превышение квоты") Это ограничение вводится флагом JOB_OBJECT_LIMIT_ACTIVE_ PROCESS в LimitFlags. |
| Affinity | Подмножество процессоров, на которых можно выполнять процессы этого задания | Для индивидуальных процессов это ограничение можно еще больше детализировать. Вводится флагом JOB_OBJECT_LIMIT AFFINITY в LimitFlags. |
| PriorityClass | Класс приоритета для всех процессов в задании | Вызванная процессом функция SetPriorityClass сообщает об успехе даже в том случае, если на самом деле она не выполнила свою задачу, a GetPriorityClass возвращает класс приоритета, каковой и пытался уста новить процесс, хотя в реальности его класс может быть совсем другим. Кроме того, SetThreadPriority не может поднять приоритет потоков выше normal, но позволяет понижать его. Это ограничение вводится флагом JOB_OBJECT_LIMIT_ PRIORITY_CLASS в LimitFlags. |
| SchedulingClass | Относительная продолжительность кванта времени, выделяемого всем потокам в задании | Этот элемент может принимать значения от 0 до 9; по умолчанию устанавливается 5. Подробнее о его назначении см. ниже. Это ограниче ние вводится флагом JOB_OBJECT_ LIMIT_SCHEDULING_CLASS в LimitFlags. |
Таблица 5-1. Элементы структуры JOBOBJECT_BASIC_LIMIT_INFORMATION
Хочу пояснить некоторые вещи, связанные с этой структурой, которые, по-моему довольно туманно изложены в документации Platform SDK. Указывая ограничения для задания, Вы устанавливаете те или иные биты в элементе LimitFlags. Например, в StartRestrictedProcess я использовал флаги JOB_OBJECT_LIMIT_PRIORITY_CLASS и JOB_ OBJECT_LIMIT_JOB_TIME, т. e. определил всего два ограничения.
При выполнении задание ведет учет по нескольким показателям — например, сколько процессорного времени уже использовали его процессы. Всякий раз, когда Вы устанавливаете базовые ограничения с помощью флага JOB_OBJECT_LIMIT_JOB_TIME, из общего процессорного времени, израсходованного всеми процессами, вычитается то, которое использовали завершившиеся процессы. Этот показатель сообщает, сколько процессорного времени израсходовали активные на данный момент процессы, А что если Вам понадобится изменить ограничения на доступ к подмножеству процессоров, не сбрасывая при этом учетную информацию по процессорному времени? Для этого Вы должны ввести новое базовое ограничение флагом JOB_OBJECT_LIMIT_AFFINITY и отказаться от флага JOB_OBJECT_LIMIT_JOB_TIME. Но тогда получится, что Вы снимаете ограничения на процессорное время.
Вы хотели другого: ограничить доступ к подмножеству процессоров, сохранив существующее ограничение на процессорное время, и не вычитать время, израсходованное завершенными процессами, из общего времени. Чтобы решить эту проблему, используйте специальный флаг JOB_OBJECT_LIMIT_PRESERVE_JOB_TIME. Этот флaг и JOB_OBJECT_LIMIT_JOB_TIME являются взаимоисключающими. Флаг JOB_OBJECT_LIMIT_PRESERVE_JOB_TIME указывает системе изменить ограничения, не вычитая процессорное время, использованное уже завершенными процессами.
Обсудим также элемент SchedulingCtoss структуры JOB_OBJECT_BASIC_LIMIT_INFORMATION. Представьте, что для двух заданий определен класс приоритета NORMAL_PRIORITY_CLASS, а Вы хотите, чтобы процессы одного задания получали больше процессорного времени, чем процессы другого.
Так вот, элемент SchedulingClass позволяет изменять распределение процессорного времени между заданиями с одинаковым классом приоритета. Вы можете присвоить ему любое значение в пределах 0-9 (по умолчанию он равен 5). Увеличивая сго значение, Вы заставляете Windows 2000 выделять потокам в процессах конкретного задания более длительный квант времени, а снижая — напротив, уменьшаете этот квант.
Допустим, у меня есть два задания с обычным (normal) классом приоритета: в каждом задании — по одному процессу, а в каждом процессе — по одному потоку (тоже с обычным приоритетом). В нормальной ситуации эти два потока обрабатывались бы процессором по принципу каруссли и получали бы равные кванты процессорного времени. Но если я запишу в элемент SchedulingClass для первого задания значение 3, система будет выделять его потокам более короткий квант процессорного времени, чем потокам второго задания.
Используя SchedulingClass, избегайте слишком больших его значений, иначе Вы замедлите общую реакцию других заданий, процессов и потоков на какие-либо со бытия в системе. Кроме того, учтите, что все сказанное здесь относится только к Windows 2000. В будущих версиях Windows планировщик потоков предполагается существенно изменить, чтобы операционная система могла более гибко планировать потоки в заданиях и процессах.
И последнее ограничение, которое заслуживает отдельного упоминания, связано с флагом JOB_OBJECT_LIMIT_DIE_ON_UNHANDLED_EXCEPTION. Он отключает для всех процессов в задании вывод диалогового окна с сообщением о необработанном исключении. Система реагирует на этот флаг вызовом SetErrorMode с флагом SEM_NOGPFAULTERRORBOX для каждого из процессов в задании. Процесс, в котором возникнет необрабатываемое им исключение, немедленно завершается без уведомления пользователя. Этот флаг полезен в сервисных и других пакетных заданиях. В его отсутствие один из процессов в задании мог бы вызвать исключение и не завершиться, впустую расходуя системные ресурсы.
Помимо базовых ограничений, Вы можете устанавливать расширенные, для чего применяется структура JOBOBJECT_EXTENDED_LIMIT_INFORMATION:
typedef struct _JOBOBJECT_EXTENDED_LIMIT_INFORMATION
{
JOBOBJECT_BASIC_LIMIT_INFORMATION BasicLimitInformation;
IO_COUNTERS Iolnfo;
SIZE_T Proces&MemoryLimit;
SIZE_T JobMemoryLimit;
SIZE_T PeakProcessMemoryUsed;
SIZE_T PeakJobMemoryUsed;
} JOBOBJECT_EXTENDED_LIMIT_INFORHATION, *PJOBOBJECT_EXTENDED LIMIT_INFORMATION;
Как видите, она включает структуру JOBOBJECT_BASIC_LIMIT_INFORMATION, являясь фактически ее надстройкой. Это несколько странная структура, потому что в ней есть элементы, не имеющие никакого отношения к определению ограничений для задания. Во-первых, элемент IoInfo зарезервирован, и Вы ни в коем случае не должны обращаться к нему. О том, как узнать значение счетчика ввода-вывода, я расскажу позже. Кроме того, элементы PeakProcessMemoryUsed и PeakJobMemoryUsed предназначены только для чтения и сообщают о максимальном объеме памяти, переданной соответственно одному из процессов или всем процессам в задании.
Остальные два элемента, ProcessMemoryLimit и JobMemoryLimit, ограничивают со ответственно объем переданной памяти, который может быть использован одним из процессов или всеми процессами в задании. Чтобы задать любое из этих ограничений, укажите в элементе LimitFlags флаг JOB_OBJECT_LIMIT_JOB_MEMORY или JOB_OB JECT_LIMIT_PROCESS_MEMORY.
А теперь вернемся к прочим ограничениям, которые можно налагать на задания. Структура JOBOBJECT_BASIC_UI_RESTRICTIONS выглядит так:
typedef struct _JOBOBJECT_BASIC_UI_RESTRICTIONS
{
DWORD UIRestrictionsClass;
} JOBOBJECT_BASIC_UI_RESTRICTIONS, *PJOBOBJECT_BASIC_UI_RESTRICTIONS;
В этой структуре всего один элемент, UIRestrictionsClass, который содержит набор битовых флагов, кратко описанных н таблице 5-2.
| Флаг | Описание |
| JOB_OBJECT_UILIMIT_EXITWINDOWS | Запрещает выдачу команд из процессов на выход из системы, завершение ее работы, перезагрузку или выключение компьютера через функцию ExitWindowsEx |
| JOB_OBJECT_UILIMIT_READCLIPBOARD | Запрещает процессам чтение из буфера обмена |
| JOB_OBJECT_UILIMIT_WRITECLIPBOARD | Запрещает процессам стирание буфера обмена |
| JOB_OBJECT_UILIMIT_SYSTEMPARAMETERS | Запрещает процессам изменение системных параметров через SystemParametersInfo |
| JOB_OBJECT_UILIMIT DISPLAYSETTINGS | Запрещает процессам изменение параметров экрана через ChangeDisplaySettings |
|
JOB_OBJECT_UILIMIT_GLOBALATOMS |
Предоставляет заданию отдельную глобаль ную таблицу атомарного доступа (global atom table) и разрешает его процессам пользоваться только этой таблицей |
|
JOB_OBJECT_UILIM1T_DESKTOP |
Запрещает процессам создание новых рабочих столов или переключение между ними через функции CreateDesktop или SwitchDesktop |
| JOB_OBJECT_UILIMIT HANDLES | Запрещает процессам в задании использо вать USER-объекты (например, HWND), созданные внешними по отношению к этому заданию процессами |
Таблица 5-2. Битовые флаги базовых ограничений по пользовательскому интерфейсу дпя объекта-задания
Последний флaг, JOB_OBJECT_UILIMIT_HANDLES, представляет особый интерес: он запрещает процессам в задании обращаться к USER-объектам, созданным внешними по отношению к этому заданию процессами. Так, запустив утилиту Microsoft Spy++ из задания, Вы не обнаружите никаких окон, кроме тех, которые создаст сама Spy++. Ha рис. 5-2 показано окно Microsoft Spy++ с двумя открытыми дочерними MDI-окнами. Заметьте, что в левой секции (Threads 1) содержится список потоков в системе. Кажется, что лишь у одного из них, 000006АС SPYXX, есть дочерние окна. А все дело в том, что я запустил Microsoft Spy++ из задания и ограничил ему права па использование описателей USER-объектов. В том же окне сообщается о потоках MSDEV и EXPLORER, но никаких упоминаний о созданных ими окнах нет. Уверяю Вас, эти потоки наверняка создали какие-нибудь окна — просто Spy++ лишена возможности их видеть. В правой секции (Windows 3) утилита Spy++ должна показывать иерархию окон на рабочем столе, но там нет ничего, кроме одного элемента — 00000000. (Это не настоящий элемент, но Spy++ была обязана поместить сюда хоть что-нибудь.)
Обратите внимание, что такие oграничения односторонни, т e. внешние процессы все равно видят USER-объекты, которые созданы процессами, включенными в задание. Например, если запустить Notepad в задании, a Spy++ — вне его, последняя увидит окно Notepad, даже если для задания указан флаг JOB_OBJECT_UILIMIT_HANDLES. Кроме того, Spy++, запущенная в отдельном задании, все равно увидинт окно Notepad, если только для ее задания не установлен флаг JOB_OBJECT_UILIMIT_HANDLES.
Рис. 5-2. Microsoft Spy++ работает в задании, которому ограничен доступ к описателям USER-объектов
Ограничение доступа к описателям USER-объектов — вещь изумительная, если Вы хотите создать по-настоящему безопасную песочницу, в которой будут "копаться" процессы Вашего задания. Однако часто бывает нужно, чтобы процесс в задании взаимодействовал с внешними процессами.
Одно из самых простых решений здесь — использовать оконные сообщения, но, если процессам в задании доступ к описателям пользовательского интерфейса запрещен, ни один из них не сможет послать сообщение (синхронно или асинхронно) окну, созданному внешним процессом. К счастью, теперь есть функция, которая поможет решить эту проблему:
BOOL UserHandleGrantAccess( HANOIF hUserObj, HANDLE hjob, BOOL fGrant);
Параметр hUserObj идентифицирует конкретный USER-объект, доступ к которому Вы хотите предоставить или запретить процессам в задании. Это почти всегда описатель окна, но USER объектом может быть, например, рабочий стол, программная ловушка, ярлык или меню. Последние два параметра, hjob и fGrant, указывают на задание и вид ограничения. Обратите внимание, что функция не сработает, если ее вызвать из процесса в том задании, на которое указывает hjob, — процесс нс имеет права сам себе предоставлять доступ к объекту.
И последний вид ограничений, устанавливаемых для задания, относится к защите. (Введя в действие такие ограничения, Вы не сможете их отменить.) Структура JOBOBJECT_SECURITY_LIMIT_INFORMATION выглядит так.
typedef struct _JOBOBJECT_SECURITY_LIMIT_INFORMATION
{
DWORD SecurityLimitFlags;
HANDLE JobToken;
PTOKEN GROUPS SidsToDisable;
PTOKEN_PRIVILEGES PrivilegesToDelete;
PTOKEN_GROUPS RestrictedSids;
} JOBOBJECT_SECURITY LIMIT_INFORMATION, *PJOBOBJECT_SECURITY_LIMIT_INFORMATION;
Ее элементы описаны в следующей таблице:
| Элемент | Описание |
| SecurityLimitFlags | Набор флагов, которые закрывают доступ администратору, запрещают маркер неограниченного доступа, принудительно назначают заданный маркер доступа, блокируют доступ по каким-либо идентификаторам защиты (security ID, SID) и отменяют указанные привилегии |
| JobToken | Маркер доступа, связываемый со всеми процессами в задании |
| SidsToDisable | Указывает, по каким SID не разрешается доступ |
| PrivilegesToDelete | Определяет привилегии, которые снимаются с маркера доступа |
| RestrictedSids | Задает набор SID, по которым запрещается доступ к любому защищенному объекту (deny-only SIDs); этот набор добавляется к маркеру доступа |
Естественно, если Вы налагаете ограничения, то потом Вам, наверное, понадобится информация о них. Для этого вызовите:
BOOL QueryInformationJobObject( HANDLE hJob, JOBOBJECTINFOCLASS JobObjectInformationClass. PVOID pvJobObjectInformation, DWORD cbJobObjectInformationLength, PDWORD pdwReturnLength);
В эту функцию, как и в SetInformationJobObject, передается описатель задания, переменная перечислимого типа JOBOJECTINFOCLASS. Она сообщает информацию об ограничениях, адрес и размер структуры данных, инициализируемой функцией. Последний параметр, pdwReturnLength, заполняется самой функцией и указывает, сколько байтов помещено в буфер. Если эти сведения Вас не интересуют (что обычно и бывает), передавайте в этом параметре NULL.
NOTE:
Процесс может получить информацию о своем задании, передав при вызове QuerylnformationJobObject вместо описателя задания значение NULL. Это позволит ему выяснить установленные для него ограничения. Однако аналогичный вызов SetInformationJobOtject даст ошибку, так как процесс не имеет права самостоятельно изменять заданные для него ограничения
Определение периодов выполнения потока
Иногда нужно знать, сколько времени затрачивает поток на выполнениетой или иной операции Многие в таких случаях пишут что-то вроде этого:
// получаем стартовое время
DWORD dwStartTime = GetTickCount();
// здесь выполняем какой-нибудь сложный алгоритм
// вычитаем стартовое время из текущего
DWORD dwElapsedTime = GetTickCount() - dwSlartTime;
Этот код основан на простом допущении, что он не будет прерван. Но в операционной системе с вытесняющей многозадачностью никто не знает, когда поток получит процессорное время, и результат будет сильно искажен. Что нам здесь нужно, так это функция, которая сообщает время, затраченное процессором на обработку данного потока. К счастью, в Windows есть такая функция:
BOOL GetThreadTimes( HANDLE hThread, PFILETIME pftCreationTime, PFILETIMt pftExitTime, PFILETIME pftKernelTime, PFIIFTIME pftUserTime);
GetThreadTimes возвращает четыре временных параметра:
|
Показатель времени |
Описание | ||
|
Время coздания (creation time) |
Абсолютная величина, выраженная в интервалах по 100 нс. Отсчитывается с полуночи 1 января 1601 года по Гринвичу до момента создания потока | ||
|
Время завершении (exit time) |
Абсолютная величина, выраженная в интервалах по 100 нс Отсчитывается с полуночи 1 января 1601 года по Гринвичу до момента завершения потока. Если поток все еще выполняется, этот показатель имеет неопределенное значение | ||
|
Время выполнения ядра (kernel time) |
Относительная величина, выраженная в интерва лах по 100 нс. Сообщает время, затраченное этим потоком на выполнение кода операцион ной системы | ||
|
Бремя выполнения User (User time) |
Относительная величина, выраженная в интерва лах по 100 не Сообщает время, затраченное по током на выполнение кода приложения. |
С помощью этой функции можно определить время, необходимое для выполне ния сложного алгоритма:
_int64 FileTimeToQuadWord(PFILETIME ptt)
{
return(Int64ShllMod32(pft->dwHighDateTime, 32) | pft->dwLowDateTime);
}
void PerformLongOperation ()
{
FILETIME ftKernelTimeStart, ftKernelTimeEnd;
FILETIME ftUserTimeStart, ftUserTirreEnd;
FILETIME ftDummy;
_int64 qwKernelTimeElapsed, qwUserTimeElapsed, qwTotalTimeElapsed;
// получаем начальные показатели времени
GetThreadTimes(GetCurrentThrcad(), &ftDurrmy, &ftDummy, &ftKernelTirrieStart, &ttUserTimeStart);
// здесь выполняем сложный алгоритм
// получаем конечные показатели времени
GetThreadTimes(GetCurrentThread(), &ftDumrny, &ftDummy, &ftKernelTimeEnd, &ftUserTimeEnd);
// получаем значении времени, затраченного на выполнение ядра и User,
// преобразуя начальные и конечные показатели времени из FILETIME
// в учетверенные слова, а затем вычитая начальные показатели из конечных
qwKernelTimeElapsed = FileTimeToQuadWord(&ftKernelTimeEnd) - FileTimeToQuadWord(&ftKernelTimeStart);
qwUserTimeElapsed = FileTimeToQuadWord(&ftUserTimeFnd) - FileTimeToQuadWord(&riUserTimeStart);
// получаем общее время, складывая время выполнения ядра и User
qwTotalTimeElapsed = qwKernelTimeElapsed + qwUserTimeElapsed;
// общее время хранится в qwTotalTimeElapsed
}
Заметим, что существует еще одна функция, аналогичная GetThreadTimes и при менимая ко всем потокам в процессе:
BOOL GetPrucessTimes( HANDLE hProcess, PFILETIHE pftCreationTime, PFILETIME pftExitTime, PFILETIME pftKernelTime, PFILETIME pftUserTime);
GetProcessTimes возвращает временные параметры, суммированные по всем пото кам (даже уже завершенным) в указанном процессе Так, время выполнения ядра бу дет суммой периодов времени, затраченного всеми потоками процесса на выполне ние кода операционной системы.
WINDOWS 98
К сожалению, в Windows 98 функции GetThreadTimes и GetProcessTimes опре делены, но не реализованы, Так что в Windows 98 нет надежного механизма, с помощью которого можно было бы определить, сколько процессорного вре мени выделяется потоку или процессу.
GetThreadTimes не годится для высокоточного измерения временных интервалов — для этого в Windows предусмотрено двe специальные функции:
BOOL QueryPerformanceFrequency(LARGE_INTEGER* pliFrequency);
BOOL QueryPerformanceCounler(LARGE_INTEGER* pliCount);
Они построены на том допущении, что поток не вытесняется, поскольку высоко точные измерения проводятся, как правило, в очень быстро выполняемых блоках кода. Чтобы слегка упростить работу с этими функциями, я создал следующий С++ - класс:
class CStopwatch
{
public:
CStopwatch() { QueryPerformanceFrequency(&m_liPeifFreq), Start(); }
void Start() { QueryPerformanceCounter(&m_liPerfStart); }
_irt64 Now() const
{ // возвращает число миллисекунд после вызова Start
LARGE_INTEGER liPerfNow;
QueryPerformanceCounter(&liPerfNow);
return(((liPerfNow.QuadPart - m_liPerfStart.QuadPart) * 1000) / m_liPerfFreq.QuadPart);
}
private
LARGE_INTEGER m_liPerfFreq;
// количество отсчетов в секунду
LARGE_INTEGER m_liPerfStart;
// начальный отсчет
};
Я применяю этот класс так:
// создаю секундомер (начинающий отсчет с текущего момента времени)
CStopwatch stopwatch;
// здесь н помещаю код, время выполнения которого нужно измерить
// определяю, сколько времени прошло
__int64 qwElapsedTime = stopwatch Now();
// qwElapsedTime сообщает длительность выполнения в миллисекундах
Определение размера блока
Выделив блок памяти, можно вызвать HeapSize и узнать его истинный размер
SIZE_T HeapSize( HANDLE hHeap, DWORD fdwFlags, LPCVOlD pvMem);
Параметр hHeap идентифицирует кучу, а параметр pvMem сообщает адрес блока. Параметр dfwFlags принимает два значения: 0 или HEAP_NO_SERIALIZE
Определение состояния адресного пространства
В Windows имеется функция, позволяющая запрашивать определенную информацию об участке памяти по заданному адресу (в пределах адресного пространства вызывающего процесса): размер, тип памяти и атрибуты защиты. В частности, с ее помощью программа VMMap (ее листинг см. на рис. 14-4) выводит карты виртуальной памяти, с которыми мы познакомились в главе 13. Вот эта функция:
DWORD VirtualQuery( LPCVOID pvAddress, PMEMORY_BASIC_INFORMATION pmbi, DWORD dwLength);
Парная ей функция, VirtualQueryEx, сообщает ту же информацию о памяти, но в другом процессе:
DWORD VirtualQueryEx( HANDLE hProcess, LPCVOID pvAddress, PMEMORY_BASIC_INFORMATION pmbi, DWORD dwLength);
Эти функции идентичны с тем исключением, что VirtualQueryEx принимает описатель процесса, об адресном пространстве которого Вы хотите получить информацию. Чаще всего функцией VirtualQueryEx пользуются отладчики и системные утилиты — остальные приложения обращаются к VirtitalQuery. При вызове VirtualQitery(Ex) параметр pvAddress должен содержать адрес виртуальной памяти, о которой Вы хотите получить информацию. Параметр pmbi — это адрес структуры MEMORY_BASIC_INFORMATION, которую надо создать перед вызовом функции. Данная структура определена в файле WinNT.h так:
typedef struct _MFMORY_BASIC_INFORMATION
{
PVOID BaseAddress;
PVOID AllocationBase;
DWORD AllocationProtect;
SIZE_T RegionSize;
DWORO State;
DWORD Protect;
DWORD Type;
} MEMORY_BASIC_INFORMATION, PMEMORY_BASIC_INFORMATION;
Параметр dwLength задает размер структуры MEMORY_BASIC_INFORMATION. Функция VirtualQuery(Ex) возвращает число байтов, скопированных в буфер.
Используя адрес, указанный Вами в параметре pvAddress, функция VirtualQuery(Ex) заполняет структуру информацией о диапазоне смежных страниц, имеющих одинаковые состояние, атрибуты защиты и тип. Описание элементов структуры приведено в таблице ниже.
|
Элемент |
Описание | ||
|
BaseAddress |
Сообщает то же значение, что и параметр pvAddress, но округленное до ближайшего меньшею адреса, кратного размеру страницы | ||
|
AllocationBase |
Идентифицирует базовый адрес региона, включающего в себя адрес, указанный в параметре pvAddress | ||
|
AllocationProtect |
Идентифицирует атрибут защиты, присвоенный региону при его резервировании | ||
|
RegionSize |
Сообщаем суммарный размер (в байтах) группы страниц, которые на чинаются с базового адреса BaseAddress и имеют те же атрибуты защиты, состояние и тип, что и страница, расположенная по адресу, указанному в параметре pvAddress | ||
|
State |
Сообщает состояние (MEM_FRFF, MFM_RFSFRVE или MEM_COMMIT) всех смежных страниц, которые имеют те же атрибуты защиты, состояние и тип, что и страница, расположенная по адресу, указанному в параметре pvAddress. При MEM_FREE элементы AllocationBase, AllocationProtect, Protect и Туре содержат неопределенные значения, а при MEM_RESERVE неопределенное значение содержит элемент Protect. | ||
|
Protect |
Идентифицирует атрибут защиты (PAGE *) всех смежных страниц, которые имеют те же трибуты защиты, состояние и тип, что и страница, расположенная по адресу, указанному в параметре pvAddress | ||
|
Type |
Идентифицируем тип физической памяти (MEM_IMAGE, MEM_MAPPED или MEM_PRIVATE), связанной с группой смежных страниц, которые имеют те же атрибуты защиты, состояние и тип, что и страница, расположенная по адресу, указанному в пара метре pvAddress. В Windows 98 этот элемент всегда дает MFM_PRIVATE. |