Приостановка и возобновление процессов
В Windows понятия "приостановка" и "возобновление" неприменимы к процессам, так как они не участвуют в распределении процессорного времени. Однако меня не раз спрашивали, как одним махом приостановить все потоки определенного процесса. Это можно сделать из другого процесса, причем он должен быть отладчиком и, в частности, вызывать функции вроде WaitForDebugEvent и ContinueDebugEvent.
Других способов приостановки всех потоков процесса в Windows нет: программа, выполняющая такую операцию, может "потерять" новые потоки. Система должна как-то приостанавливать в этот период не только все существующие, но и вновь создаваемые потоки. Microsoft предпочла встроить эту функциональность в системный механизм отладки.
Вам, конечно, не удастся написать идеальную функцию SuspendProcess, но вполне по силам добиться eё удовлетворительной работы во многих ситуациях. Вот мой вариант функции SuspendProcess.
VOID SuspendProcess(DWORD dwProcessID, BOOL tSuspend)
{
// получаем список потоков в системе
HANDLE hSnapshot = CreateToolhelp32Snapshot(TH32CS_SNAPTHREAD, dwProcessID),
if (hSnapshot != INVALID_HANDLE_VALUE) {
// просматриваем список потоков
THREADENTRY32 te = { sizeof(te) };
BOOL fOk = Thread32First(hSnapshot, &te);
for (, fOk, fOk = Thread32Next(hSnapshot, &te))
{
// относится ли данный поток к нужному процессу
if (te.th320wnerProcessID == dwProcessID)
{
// пытаемся получить описатель потока по его идентификатору
HANDLE hThread = OpenThread(THREAD_SUSPEND_RESUME, FALSE, te th32ThreadID);
if (hThread != NULL)
{
// приоcтанавливаем или возобновляем поток
if (fSuspend)
SuspendTh read(hThread);
else
ResumeThread(hThread);
}
CloseHandle(hThread);
}
}
CloseHandle(hSnapsnot);
}
}
Для перечисления списка потоков я использую ToolHelp функции (они рассматривались в главе 4). Определив потоки нужною процесса, я вызываю OpenThread.
HANDLE OpenThread( DWORD dwDesiredAccess, BOOL bInheritHandle, DWORD dwThreadID);
Это новая функция, которая появилась в Windows 2000.
Она находит объект ядра "поток" по идентификатору, указанному в dwTbreadJD, увеличивает его счетчик пользователей на 1 и возвращает описатель объекта. Получив описатель, я могу передать его в SuspendThread (или ResumeThread). OpenThread имеется только в Windows 2000, поэтому моя функция SuspendProcess не будет работать ни в Windows 95/98, ни в Windows NT 4 0.
Вероятно, Вы уже догадались, почему SuspendProcess будет срабатывать не во всех случаях: при перечислении могут создаваться новые и уничтожаться существующие потоки. После вызова CreateToolhelp32Snapshot в процессе может появиться новый поток, который моя функция уже не увидит, а значит, и не приостановит Впоследствии, когда я попытаюсь возобновить потоки, вновь вызвав SuspendProcess, она возобновит поток, который собственно и не приостанавливался. Но может быть еще хуже - при перечислении текущий поток уничтожается и создастся новый с тем же идентификатором. Тогда моя функция приостановит неизвестно какой поток (и даже непонятно в каком процессе).
Конечно, все эти ситуации крайне маловероятны, и, если Вы точно представляе те, что делает интересующий Вас процесс, никаких проблем не будет. В общем, используйте мою функцию на свой страх и риск.
Привязка к процессорам
Обычно потоки внутри процесса могут выполняться на любом процессоре компью тера. Однако их можно закрепить за определенным подмножеством процессоров из числа имеющихся на компьютере Это свойство называется привязкой к процессорам (processor affinity) и подробно обсуждается в главе 7. Дочерние процессы наследуют привязку к процессорам от родительских.
Привязка потоков к процессорам
По умолчанию Windows 2000 использует нежесткую привязку (soft affmity) потоков к процессорам Это означает, что при прочих равных условиях, система пытается выполнять поток на том же процессоре, на котором он работал в последний раз При таком подходе можно повторно использовать данные, все еще хранящиеся в кэше процессора
В повой компьютерной архитектуре NUMA (Non Uniform MemoryAccess) машина состоит из нескольких плат, на каждой из которых находятся четыре процессора и отдельный банк памяти На следующей иллюстрации показана машина с тремя таки ми платами, в сумме содержащими 12 процессоров Отдельный погок может выпол няться на любом из этих процессоров

Система NUMA достигает максимальной производительности, если процессоры используют память на своей плате Если же они обращаются к памяти на другой пла те, производительность резко падает В такой среде желательно, чтобы потоки одно го процесса выполнялись на процессорах 0-3, другого — на процессорах 4-7 и т д Windows 2000 позволяет подстроиться под эту архитектуру, закрепляя отдельные процессы и потоки за конкретными процессорами Иначе говоря, Вы можете конт ролировать, на каких процессорах будут выполняться Ваши потоки Такая привязка называется жесткой (hard affmity)
Количество процессоров система определяет при загрузке, и эта информация ста новится доступной приложениям через функцию GetSystemInfo (о ней — в главе 14). По умолчанию любой поток может выполняться на любом процессоре. Чтобы пото ки отдельного процесса работали лишь на некоем подмножестве процессоров, ис пользуйте функцию SetProcessAffinityMask:
BOOL SetProcessAffinityMask( HANDLE hProcess, DWOHD_PTR dwProcessAffinityMask);
В первом параметре, hProcess, передается описатель процесса. Второй параметр, dwProcessAffinityMask, — это битовая маска, указывающая, на каких процессорах мо гут выполняться потоки данного процесса. Передав, например, значение 0x00000005, мы разрешим процессу использовать только процессоры 0 и 2 (процессоры 1 и 3-31 ему будут недоступны).
Привязка к процессорам наследуется дочерними процессами. Так, если для роди тельского процесса задана битовая маска 0x00000005, у всех потоков его дочерних процессов будет идентичная маска, и они смогут работать лишь на тех же процессо рах. Для привязки целой группы процессов к определенным процессорам используйте объект ядра "задание" (см главу 5).
Ну и, конечно же, есть функция, позволяющая получить информацию о такой привязке;
BOOL GetProcessAffinityMask( HANDLE hProcess, PDWORD_PTR pdwProcessAffiniLyMask, PDWORD_PTR pdwSystemAffinityMask);
Вы передаете ей описатель процесса, а результат возвращается в переменной, на которую указывает pdwProcessAffimtyMask. Кроме того, функция возвращает систем ную маску привязки через переменную, на которую ссылается pdwSystemAffinityMask. Эта маска указывает, какие процессоры в системе могут выполнять потоки. Таким образом, маска привязки процесса всегда является подмножеством системной маски привязки.
WINDOWS 98
В Windows 98, которая использует только один процессор независимо от того, сколько их на самом дслс, GetProcessAffinityMask всегда возвращает в обеих пе ременныхзначенис 1.
До сих пор мы говорили о том, как назначить все потоки процесса определенным процессорам. Но иногда такие ограничения нужно вводить для отдельных потоков. Допустим, в процессе имеется четыре потока, выполняемые на четырехпроцессорной машине. Один из потоков занимается особо важной работой, и Вы, желая повысить вероятность того, что у него всегда будет доступ к вычислительным мощностям, зап рещяете остальным потокам использовать процессор 0.
Задать маски привязки для отдельных потоков позволяет функция:
DWORD_PTR SetThreadAffimtyMask( HANOLE hThread, DWORD_PTR dwThreadAffinityMask);
В параметре hTbread передается описатель потока, a dwThreadAffinityMask опреде ляет процессоры, доступные этому потоку. Параметр dwThreadAffinityMask должен
быть корректным подмножеством маски привяжи процесса, которому принадлежит данный поток Функция возвращает предыдущую маску привязки потока Вот как ог раничить три потока из нашего примера процессорами 1, 2 и 3
// поток 0 выполняется только на процессоре 0
SetThreadAffimtyMask(hThread0 0x00000001);
// потоки 1, 2 3 выполняются на процессорах 1 2 3
SetThreadAffinityMask(hThredd1 0x0000000E);
SetThreadAffimtyMask(hThread2 0x0000000E);
SetThreadAffinityMask(hThread3 0x0000000E);
WINDOWS 98
В Windows 98, которая использует только один процессор независимо от того, сколько их на самом деле, параметр dwThreadAffmityMask всегда должен быть равен 1
При загрузке система тестирует процессоры типа x86 на наличие в них знамени того "жучка" в операциях деления чисел с плавающей точкой (эта ошибка имеется в некоторых Pentium) Она привязывает поток, выполняющий потенциально сбойную операцию деления, к исследуемому процессору и сравнивает результат с тем, что дол жно быть на самом деле Такая последовательность операций выполняется для каж дого процессора в машине
NOTE
В большинстве сред вмешательство в системную привязку потоков нарушает нормальную работу планировщика, не позволяя ему максимально эффектив но распределять вычислительные мощности Рассмотрим один пример
| Поток | Приоритет | Маска привязки | Результат |
| А | 4 | 0x00000001 | Работает только на процессоре 0 |
| В | 8 | 0x00000003 | Работает на процессоре 0 и 1 |
| С | 6 | 0x00000002 | Работает только на процессоре 1 |
Но вот пробуждается поток С привязанный к процессору 1 Этот процес сор уже занят потоком В с приоритетом 8, а значит, поток С, приоритет кото рого равен 6, не может его вытеснить Он конечно, мог бы вытеснить поток А (с приоритетом 4) с процессора 0, но у него нет прав на использование этого процессора
Ограничение потока одним процессором не всегда является лучшим решением Всдь может оказаться так, что три потока конкурируют за доступ к процессору 0, тог да как процессоры 1, 2 и 3 простаивают Гораздо лучше сообщить системе, что поток желательно выполнять на определенном процессоре, но, если он занят, его можно переключать на другой процессор
Указать предпочтительный (идеальный) процессор позволяет функция:
DWORD SetThreadIdealProcessor( HANDLE hThread, DWORD dwIdealProcessor);
В параметре hThread передается описатель потока. D отличие от функций, кото рые мы уже рассматривали, параметр dwIdealProcessor содержит не битовую маску, а целое значение в диапазоне 0-31, которое указывает предпочтительный процессор для данного потока. Передав в нем константу MAXIMUM_PROCESSORS (в WinNT.h она определена как 32), Вы сообщите системе, что потоку не требуется предпочтитель ный процессор. Функция возвращает установленный ранее номер предпочтительно го процессора или MAXIMUM_PROCESSORS, если таковой процессор не задан
Привязку к процессорам можно указать в заголовке исполняемого файла. Как ни странно, но подходящего ключа компоновщика на этот случай, похоже, не предус мотрено. Тем не менее Вы можете воспользоваться, например, таким кодом:
// загружаем ЕХЕ-файл в память
PLOADED_IMAGE pLoadedImage = ImageLoad(szExeName, NULL);
// получаем информацию о текущей загрузочной конфигурации ЕХЕ-файла
IMAGE_LOAD_CONFIG_DIRECTORY ilcd;
GetImageConfigInfprmation(pLoadedImage, &ilcd),
// изменяем маску привязки процесса
ilcd.ProcessAffimtyMask = 0x00000003;
// нам нужны процессоры 0 и 1
// сохраняем новую информацию о загрузочной конфигурации
SetImageConfigInformation(pLoadedImage, &ilcd);
// выгружаем ЕХЕ-файл из памяти
ImageUnload(pLoadcdImage);
Детально описывать эти функции я не стану — при необходимости Вы найдете их в документации Platform SDK. Кроме того, Вы можете использовать утилиту Image Cfg.exe, которая позволяет изменять некоторые флаги в заголовке исполняемого мо дуля Подсказку по ее применению Вы получите, запустив ImageCfg.exe без ключей.
Указав при запуске ImageCfg ключ -а, Вы сможете изменить маску привязки для приложения Конечно, все, что делает эта утилита, — вызывает функции, перечислен ные в подсказке по ее применению. Обратите внимание на ключ -u, который сооб щает системе, что исполняемый файл может выполняться исключительно на одно процессорной машине
И, наконец, привязку процесса к процессорам можно изменять с помощью Task Manager в Windows 2000, В многопроцессорных системах в контекстном меню для процесса появляется команда Set Affinity (ее нет на компьютерах с одним процессо ром) Выбрав эту команду, Вы откроете показанное ниже диалоговое окпо и выберете конкретные процессоры для данногопроцесса.

WINDOWS 2000
При запуске Windows, 2000 на машине с процессорами типа x86 можно огра ничить число процессоров, используемых системой. В процессе загрузки сис тема считывает файл Boot.ini, который находится в корневом каталоге загру зочного диска. Вот как он выглядит на моем компьютере с двумя процессорами
[boot loader]
timeout=2
default=multi(0)disk(0)rdisk(0)partition(1)\WINNT
[operating systems]
multi(0)disk(0)rdisk(0)partition(1)\WINNT= "Windows 2000 Server"
/fastdetecL multi(0)disk(0)rdisk(0)partition(1)\WINNT="Windows 2000 Server"
/fastdetec+ /NurnProcs=1
Этот файл создается при установке Windows 2000, последнюю запись я добавил сам (с помощыо Notepad) Она заставляет систему использовать только один процессор Ключ /NumProcs=l — как раз то зелье, которое и вызывает все эти магические превращения Я пользуюсь им иногда для отладки (Но обычно работаю со всеми своими процессорами)
Заметьте, что ключи перенесены на отдельные строки с отступом лишь для удобства чтения На самом деле ключи и путь от загрузочного раздела жестко го диска должны находиться на одной строке
Пробуждение потока
Когда поток вызывает GetMessage или WaitMessage и никаких сообщений для пего или созданных им окон нет, система может приостановить выполнение потока, и тогда он уже не получаст процессорное время Как только потоку будет отправлено синх ронное или асинхронное сообщение, система установит флаг пробуждения, указыва ющий, что теперь поток должен получать процессорное время и обработать сообще ние Если пользователь ничего нс набирает на клавиатуре и не трогает мышь, то обыч но в таких обстоятельствах никаких сообщений окнам не посылается А это значит, что большинство потоков в системе не получаст процессорное время.
Пробуждение потока с использованием объектов ядра или флагов состояния очереди
Функции GetMessage и PeekMessage приостанавливают поток до тех пор, пока ему не понадобится выполнить какую-нибудь задачу, связанную с пользовательским интер фейсом. Иногда то же самое было бы удобно и при обработке других задач. Для этого поток должен как-то узнавать о завершении операции, не относящейся к пользова тельскому интерфейсу.
Чтобы поток ждал собственных сообщений, вызовите функцию MsgWaitForMultiple Objects или MsgWaitForMultipleObjectsEx:
DWORD MsgWaitForMultipleOb]ects( DWORD nCount, PHANDLE phOb]ects, BOOL fWaitAll, DWORD dwMilUseconds, DWORD dwWakeMask);
DWORD MsgWaitForMultipleObjectsEx( DWORD nCount, PHANDLE phObjects, DWORD dwMilUseconds,DWORD dwWakeMask, DWORD dwFlags);
Эти функции аналогичны WaitForMultipleObjects (см главу 9). Разница в том, что при их использовании поток становится планируемым, когда освобождается какой нибудь из указанных объектов ядра или когда оконное сообщение нужно переслать окну, созданному этим потоком.
Внутренне система просто добавляет объект ядра "событие" в массив описателей ядра Параметр dwWakeMask сообщает системе, в какой момент объект-событие дол жно переходить R свободное состояние. Его допустимые значения идентичны тем, которые можно передавать в функцию GetQueueStatus.
WaitForMultipleObjects обычно возвращает индекс освобожденного объекта (в диа пазоне от WAIT_OBJECT_0 до WAIT_OBJECT_0 + nCount - 1). Задание параметра dwWa keMask равносильно добавлению еще одного описателя При выполнении условия, определенного маской пробуждения,MsgWaitForMullipleObjects(Ex) возвращает значе ние WAIT_OBJECT_0 + nCount.
Вот пример вызова MsgWaitForMultipleObjects
MsgWaitForMultipleObjects(0, NULL, TRUE, INFINITE, QS_INPUT);
Описатели синхронизирующих объектов в этом операторе не передаются — па раметры nCount и phObjects равны соответственно 0 и NULL. Мы указываем функции ждать освобождения всех объектов Но в действительности задан лишь один объект, и с тем же успехом параметру fWaitAll можно было бы присвоить знячение FALSE.
Мы также сообщаем, что будем ждать — сколько бы времени это ни потребовало — появ ления в очереди ввода потока сообщения от клавиатуры или мыши.
Начав пользоваться функцией MsgWaitForMultipleObjects в своих программах, Вы быстро поймете, что она лишена многих важных качеств. Вот почему Microsoft при шлось создать более совершенную функцию MsgWaitForMultipleObjectsEx, которая по зволяет задать в параметре dwFlags любую комбинацию следующих флагов.
| Флаг | Описание |
| MWMO_WAITALL | Функция ждет освобождения всех объектов ядра и появления в очереди потока указанных сообщений (без этого флага функ ция ждет освобождения одного из объектов ядра или появле ния в очереди одного из указанных сообщений) |
| MWMO_ALERTABLE | Функция ждет в "тревожном" состоянии |
| MWMO_INPUTAVAILABLE | Функция ждет появления в очереди потока одного из указан ных сообщений |
При использовании MsgWaitForMultipIeObjects(Ex) учитывайте, что.
эти функции лишь включают описатель внутреннего объекта ядра "событие" в массив описателей объектов ядра, и значение параметра nCount не должно превышать 63 (MAXIMUM_WAIT_OBJECTS - 1);
если в параметре fWaitAll передастся FALSE, функции возвращают управление при освобождении объекта ядра или при появлении в очереди потока сооб щения заданного типа,
если в параметре fWaitAll передается TRUE, функции возвращают управление при освобождении всех объектов ядра и появлении в очереди потока сообщения заданного типа. Такое поведение этих функций преподносит сюрприз многим разработчикам Ведь очень часто поток надо пробуждать при освобож дении всех объектов ядра или при появлении сообщения указанного типа. Но функции, действующей именно так, нет;
при вызове любая из этих функций на самом деле проверяет в очереди пото ка только новые сообщения заданного типа.
Заметьте, что и последняя особенность этих функций — не очень приятный сюр приз для многих разработчиков.
Возьмем простой пример Допустим, в очереди по токи находятся два сообщения о нажатии клавиш. Если теперь вызвать MsgWaitForMul tipleObjects(Ex) и задать в dwWakeMask значение QS_INPUT, поток пробудится, извле чет из очереди первое сообщение и обработает его Но на повторный вызов MsgWait ForMultipleObjects(Ex) поток никак не отреагирует — ведь новых сообщений в очере ди нет.
Этот механизм создал столько проблем разработчикам, что Microsoft пришлось добавить в MsgWaitForMultipleObjectsEx поддержку флага MWMO_INPUTAVATLABLE
Вот как надо писать цикл выборки сообщений при использовании MsgWaitForMul tipleObjectsEx
BOOL fQuit = FALSE; // надо ли завершить цикл?
while (!fQuit)
{
// поток пробуждается при освобождении обьекта ядра ИЛИ
// для обработки сообщения от пользовательского интерфейса
DWORD dwResult = MsgWaitForMultipleObjectsEx(1, &hEvent, INFINITE, QS_ALLEVENTS, MWMO_INPUTAVAILABLE);
switch (dwResult}
{
case WAIT_OBJECT_0:
// освободилось событие
break;
case WAIT_OBJECT_0 + 1:
// в очереди появилось сообщение
// разослать все сообщения MSG msg;
while (PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
if (msg.message == WM_QUIT)
{
// сообщение WM_QUIT - выходим из цикла
fQuit = TRUE;
}
else
{
// транслируем и пересылаем сообщение
TranslateMessage(&msg);
DispatchMessage(&msg);
}
}
// наша очередь пуста
break;
}
}
// конец цикла while
Проецирование в память EXE- и DLL-файлов
При вызове из потока функции CreateProcess система действует так:
Отыскивает ЕХЕ-файл, указанный при вызове CreateProcess. Если файл не най ден, новый процесс не создастся, а функция возвращает FALSE.
Создает новый объект ядра "процесс"
Создает адресное пространство нового процесса
Резервирует регион адресного пространства — такой, чтобы в него поместил ся данный ЕХЕ-файл Желательное расположение этого региона указывается внут ри самого ЕХЕ-файла По умолчанию базовый адрес ЕХЕ-файла — 0x00400000 (в 64-разрядном приложении под управлением 64-разрядпой Windows 2000 этот адрес может быть другим). При создании исполняемого файла приложе ния базовый адрес может быть изменен через параметр компоновщика /BASE.
Отмечает, что физическая память, связанная с зарезервированным регионом, — ЕХЕ-файл на диске, а нс страничный файл.
Спроецировав ЕХЕ-файл на адресное пространство процесса, система обращает ся к разделу ЕХЕ-файла со списком DLL, содержащих необходимые программе функ ции. После этого система, вызывая LoadLibrary, поочередно загружает указанные (а при необходимости и дополнительные) DLL-модули. Всякий раз, когда для загрузки DLL вызывается LoadLibrary, система выполняет действия, аналогичные описанным выще в пп. 4 и 5:
Резервирует регион адресного пространства - такой, чтобы в него мог поме ститься заданный DLL-файл Желательное расположение этого региона указы вается внутри самого DLL-файла. По умолчанию Microsoft Visual C++ присваи вает DLL-модулям базовый адрес 0x10000000 (в 64-разрядной DLL под управ лением 64-разрядной Windows 2000 этот адрес может быть другим). При ком поновке DLL это значение можно изменить с помощью параметра /BASE. У всех стандартных системных DLL, поставляемых с Windows, разные базовые здре ca, чтобы не допустить их перекрытия при загрузке в одно адресное простран ство
Если зарезервировать регион по желательному для DLL базовому адресу не удается (из-за того, что он слишком мал либо занят каким-то еще EXE- или DLL файлом), система пытается найти другой регион.
Но по двум причинам такая ситуация весьма неприятна. Во-первых, если в DLL нет информации о возмож ной переадресации (relocation information), загрузка может вообще не полу читься. (Такую информацию можно удалить из DLL при компоновке с парамет ром /FIXED. Это уменьшит размер DLL-файла, но тогда модуль должен грузить ся только по указанному базовому адресу) Во-вторых, системе приходится выполнять модификацию адресов (relocations) внутри DLL. В Windowы 98 эта операция осуществляется по мере подкачки сграниц в оперативную память. Но в Windows 2000 на это уходит дополнительная физическая память, выделяе мая из страничного файла, да и загрузка такой DLL займет больше времени.
Отмечает, что физическая память, связанная с зарезервированным регионом, — DLL-файл на диске, а не страничный файл. Если Windows 2000 пришлось вы полнять модификацию адресов из-за того, что DLL не удалось загрузить по желательному базовому адресу, она запоминает, что часть физической памяти для DLL связана со страничным файлом.
Если система почему-либо не свяжет ЕХЕ-файл с необходимыми сму DLL, на эк ране появится соответствующее сообщение, а адресное пространство процесса и объект "процесс" будут освобождены При этом CreateProcess вернет FALSE; прояснить причину сбоя поможет функция GetLastError.
После увязки EXE- и DLL-файлов с адресным пространством процесса начинает исполняться стартовый код EXE-файла. Подкачку страниц, буферизацию и кэширо вание система берет на себя. Например, если код в ЕХЕ-файле переходит к команде, не загруженной в память, возникает ошибка. Обнаружив ее, система перекачивает нужную страницу кода из образа файла на страницу оперативной памяти. Затем ото бражает страницу оперативной памяти на должный участок адресного пространства процесса, тем самым позволяя потоку продолжить выполнение кода Все эти опера ции скрыты от приложения и периодически повторяются при каждой попытке про цесса обратиться к коду или данным, отсутствующим в оперативной памяти.
Проецируемые файлы и когерентность
Система позволяет проецировать сразу несколько представлений одних и тех же файловых данных. Например, можно спроецировать в одно представление первые 10 Кб файла, а затем — первые 4 Кб того же файла в другое представление Пока Вы проецируете один и тот же объект, система гарантирует когерентность (согласован ность) отображаемых данных. Скажем, если программа изменяет содержимое файла в одном представлении, это приводит к обновлению данных и в другом. Так проис ходит потому, что система, несмотря па многократную проекцию страницы на вир туальное адресное пространство процесса, хранит данные на единственной страни це оперативной памяти Поэтому, ссли представления одного и того же файла дан ных создаются сразу несколькими процессами, данные по-прежнему сохраняют ко герентность — ведь они сопоставлены только с одним экземпляром каждой страни цы в оперативной памяти Bcc это равносильно тому, как если бы страницы опера тивной памяти были спроецированы на адресные пространства нескольких процес сов одновременно.
NOTE:
Windows позволяет создавать несколько объектов "проекция файла", связан ных с одним и тем же файлом данных. Но тогда у Вас не будет гарантий, что содержимое представлений этих объектов когерентно Такую гарантию Win dows дает только для нескольких представлений одного объекта "проекция файла".
Кстати, функция CreateFile позволяет Вашему процессу открывать файл, проеци руемый в память другим процессом После этого Ваш процесс сможет считывать или записывать данные в файл (с помощью функций ReadFite или WriteFile), Разумеется, при вызовах упомянутых функций Ваш процесс будет считывать или записывать дан ные не в файл, а в некий буфер памяти, который должен быть создан именно этим процессом; буфер не имеет никакого отношения к участку памяти, используемому для проецирования данного файла. Но надо учитывать, что, когда два приложения откры вают один файл, могут возникнуть проблемы. Дсло в том, что один процесс может вызвать ReadFile, считать фрагмент файла, модифицировать данные и записать их обратно в файл с помощью WriteFile, а объект "проекция файла", принадлежащий вто рому процессу, ничего об этом не узнает. Поэтому, вызывая для проецируемого фай ла функцию CreateFile, всегда указывайте нуль в параметре dwShareMode. Тем самым Вы сообщите системе, что Вам нужен монопольный доступ к файлу и никакой посто ронний процесс не должен его открывать.
Файлы с доступом "только для чтения" не вызывают проблем с когерентностью — значит, это лучшие кандидаты на отображение в память. Ни в коем случае не исполь зуйте механизм проецирования для доступа к записываемым файлам, размещенным на сетевых дискях, так как система не сможет гарантировать когерентность представ лений данных. Если один компьютер обновит содержимое файла, то другой, у кото рого исходные данные содержатся в памяти, не узнает об изменении информации.
Программа-пример Applnst
Эта программа, "17 AppInst.exe" (см листинг на рис 17-1), демонстрирует, как выяс нить, сколько экземпляров приложения уже выполняется в системе Файлы исходно го кода и ресурсов этои программы находятся в каталоге 17-AppInst на компакт-дис
ке, прилагаемом к книге. Погле запуска AppInst на экране появляется диалоговое окно, в котором сообщается, что сейчас выполняется только один cc экземпляр.

Если Вы запустите второй экземпляр, оба диалоговых окна сообщат, что теперь выполняется два экземпляра.

Вы можете запускать и закрывать сколько угодно экземпляров этой программы — окно любого из них всегда будет отражать точное количество выполняемых экземп ляров.
Где-то в начале файла AppInst.cpp Вы заметите следующие строки:
// указываем компилятору поместить эту инициализированную переменную
// в раздел Shared, чтобы она стала диступной всем окземплярам программы
#pragma data_seg("Shared")
volatile LONG g_lApplicationInstances = 0;
#pragma data_seg()
// указываем компоновщику, что раздел Shared должен быть
// читаемым, записываемым и разделяемым
#pragma comment(linker, "/Section.Shared,RWS")
В этих строках кода создается раздел Shared c атрибутами защиты, которые раз решают его чтение, запись и разделение. Внутри него находится одна переменная, g_lApplicationInstances, доступная всем экземплярам программы. Заметьте, что для этой переменной указан спецификатор vokitile, чтобы оптимизатор не слишком с ней ум ничал.
При выполнении функции _tWinMain каждого экземпляра значение переменной g_lApplicattonInstances увеличивается на 1, а перед выходом ич _tWinMain — уменьша ется на 1. Я изменяю ее знячение с помощью функции InterlockedExchangeAdd, так как эта переменная является общим ресурсом для нескольких потоков.
Когда на экране появляется диалоговое окпо каждого экземпляра программы, вызывается функция Dlg__OnJnitDialog. Она рассылает всем окнам верхнего уровня зарегиорированное оконное сообщение (идентификатор которого содержится в переменной g_aMsgAppInstCоuntUpdate).
PostMessage(HWND_BROADCAST, g_aMsgAppInstCountUpdate, 0, 0);
Это сообщение игнорируется всеми окнами в системе, кроме окон AppInst. Когда его принимает одно из окон нашей программы, код в DlgProc просто обновляет в диалоговом окнс значение, отражающее текущее количество экземпляров (а эта ве личина хранится в переменной g_lApplicattonInstances).

Программа-пример AWE
Эта программа,"15 AWE ехе" (см листинг на рис 15-3), демонстрирует, как создавать несколько адресных окон и связывать с ними разные блоки памяти. Файлы исходно го кода и ресурсов этой программы находятся в каталоге 15-AWE на компакт-диске, прилагаемом к книге. Сразу после запуска программы AWE создается два адресных окна и выделяется два блока памяти
Изначально первый блок занимает строка "Text in Storage 0", второй — строка "Text in Storage 1". Далее первый блок связывается с первым адресным окном, а второй — со вторым окном При этом окно программы выглядит так, как показано ниже.

Оно позволяет немного поэкспериментировать Во-первых, эти блоки можно на значить разным адресным окнам, используя соответствующие поля со списками. В них, кстати, предлагается и вариант No Storage, при выборе которого память отклю чается от адресного окна. Во-вторых, любое изменение текста немедленно отражает ся на блоке памяти, связанном с текущим адресным окном
Если Вы попытаетесь связать один и тот же блок памяти с двумя адресными окна ми одновременно, то, поскольку механизм AWE это не разрешает, на экране появится следующее сообщение

Исходный код этой программы-примера предельно ясен. Чтобы облегчить рабо ту с механизмом AWE, я создал три С++-класса, которые содержатся в файле AddrWin dows.h. Первый класс, CSystemInfo, — очень простая оболочка функции GetSystemInfo По одному его экземпляру создают остальные два класса
Второй С++-класс, CAddrWindow, инкапсулирует адресное окно Его метод Create резервирует адресное окно, метод Destroy уничтожает это окно, метод UnmapStorage отключает от окна связанный с ним блок памяти, я метод оператора приведения PVOID просто возвращает виртуальный адрес адресного окна.
Третий C++-класс, CAddrWindowStorage, инкапсулирует блок памяти, который можно назначить объекту класса CAddrWindow Метод Attocate разрешает блокировать страницы в памяти, выделяет блок памяти, а затем отменяет право на блокировку, Метод Free освобождает блок памяти Метод HowManyPagetAllocated возвращает ко личество фактически выделенных страниц. Наконец, метод MapStorage связывает блок памяти с объектом класса CAddrWmdow, a UnmapStorage отключает блок от этого объекта.
Применение C++ классов существенно упростило реализацию программы AWE Она создает по два объекта классов CAddrWindow и CAddrWindowStorage Остальной код просто вьзывает нужные методы в нужное время
Программа-пример CopyData
Эта программа, "26 CopyData.exe" (см. листинг иа рис 26-3), демонстрирует приме нение сообщения WM_COPYDAIA при пересылке блока данных из одной программы в другую Файлы исходного кода и ресурсов этой программы находятся в каталоге 26 CopyData на компакт-диске, прилагаемом к книге Чтобы увидеть программу CopyData в действии, запустите минимум две ее копии, при этом каждая копия открывает диа логовое окно, показанное ниже

Если Вы хотите посмотреть, как данные копируются из одного приложения в дру гое, то сначала измените содержимое полей Datal и Data2 Затем щелкните одну из двух кнопок Send Data* To Other Windows Программа отправит данные всем выпол няемым экземплярам CopyData, и в их полях появится новые данные
А теперь обсудим принцип работы программы. Щелчок одной из двух кнопок приводит к.
Инициализации элемента dwData структуры COPYDATASTRUCT нулевым зна чением (если выбрана кнопка Scnd Datal To Other Windows) или единицей (если выбрана кнопка Send Data2 To Other Windows)
Подсчету длины текстовой строки (в символах) из соответствующего поля с добавлением единицы, чтобы учесть нулевой символ в конце Полученное чис ло символов преобразуется в количество байтов умножением на sizeof(TCHAR), и результат записывается в элемент cbData структуры COPYDATASTRUCT
Вызову _alloca, чтобы выделить блок памяти, достаточный для хранения стро ки с учетом концевого нулевого символа Адрес этого блока записывается в элемент lpData все той же структуры
Копированию текста из поля в выделенный блок памяти
Теперь все готово для пересылки в другие окна Чтобы определить, каким окнам следует посылать сообщение WM_COPYDATA, программа вызывает FindWindowEx и передает заголовок своего диалогового окна - благодаря этому перечисляются толь ко другие экземпляры данной программы. Найдя окна всех экземпляров, программа пересылает им сообщение WM_COPYDATA, что заставляет их обновить содержимое своих полей.
Программа-пример Counter
Эта программа, "12 Counter.exe" (см. листинг на рис 12-1), демонстрирует примснс нис волокон для реализации фоновой обработки. Запустив се, Вы увидите диалого вое окно, показанное ниже (Настоятельно советую запустить программу Counter, тогда Вам будет легче понять, что происходит в ней и как она себя ведет)

Считайте эту программу свсрхминиатюрной электронной таблицей, состоящей всего из двух ячеек. В первую из них можно записывать — она реализована как поле, расположенное за меткой Count To. Вторая ячейка доступна только для чтения и ре ализована как статический элемент управления, размещенный за меткой Answer Из менив число в поле, Вы заставите программу пересчитать значение в ячейке Answer. В этом простом примере пересчет заключается в том, что счетчик, начальное значе ние которого равно 0, постепенно увеличивается до максимума, заданного в ячейке Count То. Для наглядности статический элемент управления, расположенный в ниж ней части диалогового окна, показывает, какое из волокон — пользовательского ин терфейса или расчетное — выполняется в данный момент
Чтобы протестировать программу, введите в поле число 5 — строка Currently Running Fiber будет заменена строкой Recalculation, а значение в поле Answer посте пенно возрастет с 0 до 5. Когда пересчет закончится, текущим волокном вновь станет интерфейсное, а поток заснет Теперь введите число 50 и вновь понаблюдайте за пе ресчегом — на этот paз перемещяя окно по экрану. При этом Вы заметите, что рас четное волокно вытесняется, а интерфейсное вновь получает процессорное время, благодаря чему программа продолжает реагировать на действия пользователя. Оставь те окно в покое, и Вы увидите, что расчетное волокно снова получило управление и возобновило работу с того значения, на котором было прервано
Остается проверить лишь одно. Давайте изменим число в поле ввода в момент пересчета Заметьте: интерфейс отреагировал на Ваши действия, но после ввода дан ных пересчет начинается заново. Таким образом, программа ведет себя как настоя щая электронная таблица.
Обратите внимание и на то, что в программе не задействованы ни критические секции, ни другие объекты, синхронизирующие потоки, — все сделано на основе двух волокон в одном потоке
Теперь обсудим внутреннюю реализацию программы Counter Когда первичный поток процесса приступает к выполнению _tWinMain, вызывается функция Convert ThreadToFiber, преобразующая поток в волокно, которое впоследствии позволит нам создать другое волокно. Затем мы создаем немодальнос диалоговое окно, выступаю щее в роли главного окна программы. Далее инициализируем переменную — инди катор состояния фоновой обработки (background processing stale, BPS) Она реализо вана как элемент bps в глобальной переменной g_FiberInfo Ее возможные состояния описываются в следующей таблице.
| Состояние | Описание |
| BPS_DONE | Пересчет завершен, пользователь ничего не изменял, новый пересчет не нужен |
| BPS_STARTOVER | Пользователь внес изменения, требуется пересчет с самою начала |
| BPS_CONTINUE | Пересчет еще продолжается, пользователь ничего не изменил, пере счет заново не нужен |
Если поступает оконное сообщение (активен пользовательский интерфейс), обрабатываем именно его. Своевременная обработка действий пользователя всегда приоритетнее пересчета.
Если пользовательский интерфейс простаивает, проверяем, не нужен ли пе ресчет (т. e. не присвоено ли переменной bfs значение BPS_STARTOVER или BPS_CONTINUE).
Если вычисления нс нужны (BPS_DONE), приостанавливаем поток, вызывая WaitMessage, — только событие, связанное с пользовательским интерфейсом, может потребовать пересчета.
Если интерфейсному волокну делать нечего, а пользователь только что изменил значение в поле ввода, начинаем вычисления заново (BPS_STARTOVER). Главное, о чем здесь надо помнить, — волокно, отвечающее за пересчет, может уже работать. Тогда это волокно следует удалить и создать новое, которое начнет все с начала.
Чтобы уничтожить выполняющее пересчет волокно, интерфейсное вызывает DeleteFiber. Именно этим и удобны волокна. Удаление волокна, занятого пересчетом, — операция вполне допустимая, стек волокна и его контекст корректно уничтожаются Если бы мы использовали потоки, а не волокна, интерфейсный поток не смог бы корректно уничтожить поток, занятый пересчетом, — нам пришлось бы задействовать какой нибудь механизм межпоточного взаимодействия и ждать, пока поток пересчета не завершится сам. Зная, что волокна, отвечающего за пересчет, больше нет, мы впра ве создать новое волокно для тех же целей, присвоив переменной bps значение BPS_CONTINUE.
Когда пользовательский интерфейс простаивает, а волокно пересчета чем-то за нято, мы выделяем ему процессорное время, вызывая SwitchToFiber, Последняя не вер пет управление, пока волокно пересчета тоже не обратится к SwitchToFiber, передав ей адрес контекста интерфейсного волокна.
FtberFunc является функцией волокна и содержит код, выполняемый волокном пересчета. Ей передается адрес глобальной структуры g_FiberInfo, и поэтому она зна ет описатель диалогового окна, адрес контекста интерфейсного волокна и текущее состояние индикатора фоновой обработки. Конечно, раз это глобальная переменная, то передавать ее адрес как параметр необязательно, но и решил показать, как в функ цию волокна передаются параметры. Кроме того, передача адресов позволяет добить ся того, чтобы код меньше зависел от конкретных переменных. - именно к этому и следует стремиться.
Первое, что делает функция волокна, — обновляет диалоговое окно, сообщая, что сейчас выполняется волокно пересчета. Далее функция получает значение, введенное в поле, и запускает цикл, считающий от 0 до указанного значения. Перед каждым приращением счетчика вызывается GetQueueStаtus — эта функция проверяет, не по
явились ли в очсрсди потока новые сообщения. (Все волокна, работающие в рамках одного потока, делят его очередь сообщений) Если сообщение появилось, значит, интерфейсному волокну есть чем заняться, и мы, считая его приоритетным по отно шению к расчетному, сразу же вызываем SwitchToFiber, давая ему возможность обра ботать поступившее сообщение Когда сообщение (или сообщения) будет обработа но, интерфейсное волокно передаст управление волокну, отвечающему за пересчет, и фоновая обработка возобновится.
Если сообщений нет, расчетное волокно обновляет поле Answer диалогового окна и засыпает на 200 мс. В коде настоящей программы вызов Sleep надо, естественно, убрать — я поставил его, только чтобы "потянуть" время.
Когда волокно, отвечающее за пересчет, завершает свою работу, статус фоновой обработки устанавливается как BPS_DONE, и управление передается (через Switch ToFiber) интерфейсному волокну. В этот момент ему делать нечего, и оно вызывает WaitMessage, которая приостанавливает поток, чтобы не тратить процессорное время понапрасну.
Программа-пример DelayLoadApp
Эта программа, "20 DelayLoadApp.exe" (см. листинг на рис. 20-6), показывает, как использовать все преимущества DLL отложенной загрузки. Для демонстрации нам понадобится небольшой DLL-файл; он находится в каталоге 20-DclayLoadLib на компактдиске, прилагаемом к книге.
Так как программа загружает модуль "20 DelayLoadLib" c задержкой, загрузчик не проецирует его на адресное пространство процесса при запуске. Периодически вызывая функцию IsModuleLoaded, программа выводит окно, которое информирует, загружен ли модуль в адресное пространство процесса. При первом запуске модуль "20 DelayLoadd.lib" не загружается, о чем и сообщается в окне (рис. 20-4).

Рис. 20-4. DelayLoadApp сообщает, что модуль "20 DelayLoadLib" не загружен
Далсс программа вызывает функцию, импортируемую из Dl.L, и это заставляет __delayLoadHelper автоматически загрузить нужную DLL. Когда функция всрнст управление, программа выведет окно, показанное на рис. 20-5.

Рис. 20-5. DelayLoadApp сообщает, что модуль "20 DelayLoadLib" загружен
Когда пользователь закроет это окно, будет вызвана другая функция из той же DLL. В этом случае DLL не перезагружается в адресное пространство, но перед вызовом новой функции придется определять ее адрес.
Далее вызывается __FUnloadDelayLoadedDLL, и модуль "20 DelayLoadLib" выгружается из памяти. После очередного вьиова IsModuleLoaded на экране появляется окно, показанное на рис. 20-4. Наконец, вновь вызывается импортируемая функция, что приводит к повторной загрузке модуля "20 DelayLoadLib", a IsModuleLoaded открывает окно, как на рис. 20-5.
Если все нормально, то программа будет работать, как я только что рассказал. Однако, если перед запуском программы Вы удалите модуль "20 DelayLoadLib" или если в этом модуле не окажется одной из импортируемых функций, будет возбуждено исключение. Из моего кода видно, как корректно выйти из такой ситуации.
Наконец, эта программа демонстрирует, как настроить функцию-ловушку из DLL отложенной загрузки. Моя схематическая функция DliHook не делает ничего интересного. Тем не менее она перехватывает различные уведомления и показывает их Вам.
Программа-пример ErrorShow
Эта программа, "01 ErrorShow.exe" (см. листинг на рис. 1 -2), демонстрирует, как получить текстовое описание ошибки no ee коду. Файлы исходного кода и ресурсов программы находятся в каталоге Ol-ErrorShow на компакт-диске, прилагаемом к книге.
Программа ErrorShow в основном предназначена для того, чтобы Вы увидели, как работают окно Watch отладчика и утилита Error Lookup. После запуска ErrorShow открывается следующее окно.

В поле Error можно ввести любой код ошибки. Когда Вы щелкнете кнопку Look Up, внизу, в прокручиваемом окне появится текст с описанием данной ошибки. Единственная интересная особенность программы заключается в том, как она обращается к функции FormatMessage. Я использую эту функцию так:
// получаем код ошибки
DWORD dwError = GetDlgItemInt(hwnd, IDC_ERRORCODE, NULL, FALSE);
HLOCAL hlocal = NULL; // буфер для строки с описанием ошибки
// получаем текстовое описание ошибки
BOOL fOk = FormatMessage(
FORMAT_MESSAGE_FROM_SYSTFM | FORMAT_MESSAGE_ALLOCATC_BUFFER,
NULL, dwError, MAKELANGID(LANG_ENGLISH, SUBLANG_ENGLISH_US).
(LPTSTR) &hlocal, 0, NULL);
if (hlocal != NULL) {
SetDlgItemText(hwnd, IDC_ERRORTEXT, (PCTSTR) LocalLock(hlocal));
LocalFree(hlocal);
} else {
SetDlgItemText(hwnd, IDC ERRORTEXT, TEXT("Error number not found "));
}
Первая строка считывает код ошибки из текстового поля. Далее я создаю экземпляр описателя (handle) блока памяти и инициализирую его значением NULL. Функция FormatMessage сама выделяет нужный блок памяти и возвращает нам его описатель.
Вызывая FormatMessage, я передаю флаг FORMAT_MESSAGE_FROM_SYSTEM Он сообщает функции, что мне нужна строка, соответствующая коду ошибки, определенному в системе. Кроме того, я передаю флаг FORMAT_MESSAGE_ALLOCATE_BUFFER, чтобы функция выделила соответствующий блок памяти для хранения текста Описатель этого блока будет возвращен в переменной hlocal. Третий параметр указывает код интересующей нас ошибки, а четвертый — язык, на котором мы хотим увидеть ее описание.
Если выполнение FormatMessage заканчивается успешно, описание ошибки помещается в блок памяти, и я копирую его в прокручиваемое окно, расположенное в нижней части окна программы. А если вызов FormatMessage оказывается неудачным, я пытаюсь найти код сообщения в модуле NetMsg.dll, чтобы выяснить не связана ли ошибка с сетью Используя описатель NetMsg.dll, я вновь вызываю FormatMessage. Дело в том, что у каждого DLL или ЕХЬ-модуля может быть собственный набор кодов ошибок, который включается в модуль с помощью Message Compiler (MC.exe) Как раз это и позволяет делать утилита Error Lookup через свое диалоговое окно Modules.
Программа-пример FileRev
Эта программа, "17 FileRev.exe" (см. листинг на рис. 17-2), демонстрирует, как с помо щью механизма проецирования записать в обратном порядке содержимое текстово го ANSI- или Unicode-файла. Файлы исходного кода и ресурсов чтой программы на ходятся в каталоге 17-FileRev на компакт-диске, прилагаемом к книге. После запуска FileRev на экране появляется диалоговое окно, показанное ниже.

Выбрав имя файла и щелкнув кнопку Reverse File Contents, Вы активизируете фун кцию, которая меняет порядок символов в файле на обратный, Программа коррект но работает только с текстовыми файлами. В какой кодировке создан текстовый файл (ANSI или Unicode), FileRev определяет вызовом IsTextUnicode (см. главу 2).
WINDOWS 98
В Windows 98 функция IsTextUnitode определена, но не реализована, она про сто возвращает FALSE, а последующий вызов GetLastError дает ERROR_CALL_ NOT_IMPLEMENTED. Это значит, что программа FileRev, выполняемая в Win dows 98, всегда считает, что файл содержит текст в ANSI-кодировке.
После щелчка кнопки Reverse File Contents программа создает копию файла с именем FileRev.dat, Делается это для того, чтобы не испортить исходный файл, изме нив порядок следования байтов на обратный. Далее программа вызывает функцию FileReverse — она меняет порядок байтов на обратный и после этого вызывает Create File, открывая FileRev.dat для чтения и записи
Как я уже говорил, простейший способ "перевернуть* содержимое файла — выз вать функцию _strrev из библиотеки С. Но для этого последний символ в строке дол жен быть нулевой. И поскольку текстовые файлы не заканчиваются нулевым симво лом, программа FileRev подписывает его в конец файла. Для этого сначала вызывает ся функция GetFileSize:
dwFileSize = GetFileSize(hFile, NULL);
Теперь, вооружившись знанием длины файла, можно создать объект "проекция файла", вызвав CreateFileMapping. При этом размер объекта равен dwFileSize плюс размер "широкого" символа, чтобы учесть дополнительный нулевой символ в конце файла.
Создав объект "проекция файла", программа проецирует на свое адресное пространство представление этого объекта. Переменная pvFile содержит значение, возвращенное функцией MapViewOfFile, и указывает на первый байт текстового файла.
Следующий шаг — запись нулевого символа в конец файла и реверсия строки:
PSTR pchANSI = (PSFR) pvFile;
pchANSI[dwFileSize / sizeof(CHAR)] = 0;
// "переворачиваем" содержимое файла
_strrev(pchANSI);
В текстовом файле каждая строка завершается символами возврата каретки ("\r") и перевода строки ('\n') К сожалению, после вызова функции _strrev эти символы тоже меняются местами. Поэтому для загрузки преобразованного файла в текстовый ре дактор придется заменить все пары "\n\r" на исходные "\r\n". B программе этим за нимается следующий цикл.
while (pchANSI != NULL)
{
// вхождение найдено
*pchANSI++ = '\r ; // заменяем '\n' на '\r'
*pchANSI++ = '\n', // заменяем '\r на \n'
pchANSI = strchr(pchANSI, \n');
// ищем следующее вхождение
}
Закончив обработку файла, программа прекращает отображение на адресное про странство представления объекта "проекция файла" и закрывает описатель всех объ ектов ядра Кроме того, программа должна удалить нулевой символ, добавленный в конец файла (функция strrev не меняет позицию этого символа) Если бы програм ма не убрала нулевой символ, то полученный файл оказался бы на 1 символ длиннее, и тогда повторный запуск программы FileRev не позволил бы вернуть этот файл в исходное состояние Чтобы удалить концевой нулевой символ, надо спуститься на уровень ниже и воспользоваться функциями, предназначенными для работы непос редственно с файлами на диске.
Прежде всего установите указатель файла в требуемую позицию (в данном слу чае — в конец файла) и вызовите функцию SetEndOfFile:
SetFilePointer(hFile, dwFileSize, NULL, FILE_BEGIN);
SetEndOfFile(hFile);

NOTE:
Функцию SetEndOfFile нужно вызывать после отмены проецирования представ ления и закрытия объекта "проекция файла", иначе она вернет FALSE, а функ ция GetLastError — ERROR_USER_MAPPED_FILE.Данная ошибка означает, что операция перемещения указателя в конец файла невозможна, пока этот файл связан с объектом "проекция файла".
Последнее, что делает FileRev, — запускает экземпляр Notepad, чтобы Вы могли увидеть преобразованный файл. Вот как выглядит результат работы программы FileRev применительно к собственному файлу FileRev.cpp.
Программа-пример Handshake
Программа ("09 Handshake.exe"), изображенная на рис 9-1, демонстрирует применение событий с автосбросом. Файлы исходного кода и ресурсов этой программы находятся в каталоге "09-Handshake" на компакт-диске, прилагаемом к книге. После запуска Handshake открывается окно, показанное ниже.

Handshake принимает строку запроса, меняет в ней порядок всех символов и по казывает результат в поле Result. Самое интересное в программе Handshake — то, как она выполняет эту героическую задачу
Программа решает типичную проблему программирования. У Вас есть клиент и сервер, которые должны как-то общаться друг с другом. Изначально серверу делать нечего, и он переходит в состояние ожидания Когда клиент готов передать ему зап рос, он помещает этот запрос в разделяемый блок памяти и переводит объект-собы тие в свободное состояние, чтобы поток сервера считал этот блок памяти и обрабо тал клиентский запрос Пока серверный поток занят обработкой запроса, клиентский должен ждать, когда будет готов результат Поэтому клиент переходит в состояние ожидания и остается в нем до тех пор, пока сервер не освободитдругой объект-со бытие, указав тем самым, что результат готов Вновь пробудившись, клиент узнает, что результат находится в разделяемом блоке памяти, и выводит готовые данные пользо вателю.
При запуске программа немедленно создает два объекта-события с автосбросом в занятом состоянии Один ит них, g_hevtRequestSubmitted, используется как индика тор готовности запроса к серверу. Этo собьпие ожидается серверным потоком и ос вобождается клиентским. Второй обьект-событие, g_hevtRequestSubmitted, служит инди катором готовности данных для клиента. Это событие ожидается клиентским пото ком, а освобождается серверным.
После создания событий программа порождает серверный поток и выполняет функцию ServerThread Эта функция немедленно заставляет серверный поток ждать запроса от клиента. Тем временем первичный поток, который одновременно являет ся и клиентским, вызывает функцию DialogBox, отвечающую за отображение пользо вательского интерфейса программы Вы вводите какой-нибудь текст в поле Request и, щелкнув кнопку Subrnit Request To Server, заставляете программу поместить строку запроса в буфер памяти, разделяемый между клиентским и серверным потоками, а также перевести событие g_hevtRequestSubmitted в свободное состояние Далее клиен тский поток ждет результат от сервера, используя объект-событие g_hevtResultReturned
Теперь пробуждается серверный поток, обращает строку в блоке разделяемой па мяти, освобождает событие g_hevtResultReturned и вновь засыпает, ожидая очередно го запроса от клиента. Заметьте, что программа никогда не вызывает ResetEvent, так как в этом нет необходимости; события с автосбросом автоматически восстанавли вают свое исходное (занятое) состояние в результате успешного ожидания Клиентс кий поток обнаруживает, что событие g_hevtResultReturned освободилось, пробужда ется и копирует строку из общего буфера памяти в поле Result.
Последнее, что заслуживает внимания в этой программе, — то, как она заверша ется Вы закрываете ее окно, и это приводит к тому, что DialogBox в функции _tWinMain возвращает управление. Тогда первичный поток копирует в общий буфер специаль ную строку и пробуждает серверный поток, чтобы тот ее обработал Далсс первич ный поток ждет от сервера подтверждения о приеме этого специального запроса и
завершения его потока Серверный поток, получив от клиента специальный запрос, выходит из своего цикла и сразу же завершается
Я предпочел сделать так, чтобы первичный поток ждал завершения серверного вызовом WаittForMultipleObjects, - просто из желания продемонстрировать, как исполь зуется эта функция На самом делс я мог бы вызвать и WaitForStngleObject, передав ей описатель серверного потока, и все работало бы точно так же
Как только первичный поток узнает о завершении серверного, он трижды вызы вает CloseHandle для корректного закрытия всех объектов ядра, которые использова лись программой Конечно, система могла бы закрыть их за меня, но как-то спокой нее, когда делаешь это сам Я предпочитаю полностью контролировать все, что про исходит в моих программах
Программа-пример JobLab
Эта программа, "05_КJobLab.ехе"(см листинг на рис 5-6),позволяет легко экспериментировать с заданиями. Ее файлы исходного кода и ресурсов находятся в каталоге 05-JobLab на компакт-диске, прилагаемом к книге. После запуска JobLab открывается окно, показанное на рис 5-5.

Рис. 5-5. Программа-пример JobLab
Когда процесс инициализируется, он создает объект "задание". Я присваиваю ему имя JobLab, чтобы Вы могли наблюдать за ним с помощью MMC Performance Monitor. Моя программа также создает порт завершения ввода-вывода и связывает с ним объект-задание. Это позволяет отслеживать уведомления от задания и отображать их в списке в нижней части окна.
Изначально в задании нет процессов, и никаких ограничений для него не установлено. Поля в верхней части окна позволяют задавать базовые и расширенные ограничения. Все, что от Вас требуется, — ввести в них допустимые значения и щелкнуть кнопку Арр1у Limits. Если Вы оставляете поле пустым, соответствующие ограничения не вводятся. Кроме базовых и расширенных, Вы можете задавать ограничения по пользовательскому интерфейсу. Обратите внимание помечая флажок PreserveJob Time When Applymg Limits, Вы не устанавливаете ограничение, а просто получаете возможность изменять ограничения, не сбрасывая значения элементов ThisPeriod-
TotalUserTime и ThisPeriodTotalKemelTime при запросе базовой учетной информации. Этот флажок становится недоступен при наложении ограничений на процессорное время для отдельных заданий.
Остальные кнопки позволяют управлять заданием по-другому. Кнопка Terminate Processes уничтожает все процессы в задании. Кнопка Spawn CMD In Job запускает командный процессор, сопоставляемый с заданием. Из этого процесса можно запускать дочерние процессы и наблюдать, как они ведут себя, став частью задания. И последняя кнопка, Put PID In Job, позволяет связать существующий свободный процесс с заданием (т. e. включить его в задание).
Список в нижней части окна отображает обновляемую каждые 10 секунд информацию о статусе задания, базовые и расширенные сведения, статистику ввода-вывода, а также пиковые объемы памяти, занимаемые процессом и заданием.
Кроме этой информации, в списке показываются уведомления, поступающие от задания в порт завершения ввода-вывода. (Кстати, вся информация обновляется и при приеме уведомления.)
И еще одно: если Вы измените исходный код и будете создавать безымянный объект ядра "задание", то сможете запускать несколько копий этой программы, создавая тем самым два и более объектов-заданий на одной машине. Это расширит Ваши возможности в экспериментах с заданиями.
Что касается исходного кода, то специально обсуждать его нет смысла — в нем и так достаточно комментариев. Замечу лишь, что в файле Job.h я определил С++-класс CJob, инкапсулирующий объект "задание" операционной системы. Эти избавило меня от необходимости передавать туда-сюда описатель задания и позволило уменьшить число операций приведения типов, которые обычно приходится выполнять при вызове функций QuerylnformationJobObject и SetInformationJobObject.
Программа-пример LastMsgBoxlnfo
Эта программа, "22 LabtMsgBoxInfo.exe" (см листинг на рис. 22-5), демонстрирует перехват API-вызовов. Она перехватывает все обращения к функции MessageBox из User32.dll. Для этого программа внедряет DLL с использованием ловушек. Файлы исходного кода и ресурсов этой программы и DLL находятся в каталогах 22-LastMsgBoxInfo и 22-LastMsgBoxIntoLib на компакт-диске, прилагаемом к книге*
После запуска LastMsgBoxInfo открывает диалоговое окно, показанное ниже.

В этот момент программа находится в состоянии ожидания. Запустите какое-нибудь приложение и заставьте его открыть окно с тем или иным сообщением Тестируя свою программу, я запускал Notepad, набирал произвольный текст, а затем пытался закрыть его окно, не сохранив набранный текст Это заставляло Notepad выводить вот такое окно с предложением сохранить документ.

DWORD dwOummy;
VirtualProtect(ppfn, Sizeof(ppfn), PAGE_EXECUTE_READWRITE, &dwDummy);
После отказа от сохранения документа диалоговое окно LastMsgBoxInfo приобретает следующий вид

Как видите, LastMsgBoxlnfo позволяет наблюдать за вызовами функции MessageBox из других процессов
Код, отвечающий за вывод диалогового окна LastMsgBoxInfo и управление им весьма прост. Трудности начинаются при настройке перехвата API-вызовов. Чтобы упростить эту задачу, я создал С++-класс CAPIHook, определенный в заголовочном файле APTHook.h и реализованный в файле APIHook.cpp. Пользоваться им очень легко, так как в нем лишь несколько открытых функций-членов: конструктор, деструктор и метод, возвращающий адрес исходной функции, на которую Вы ставите ловушку
Для перехвата вызова какой-либо функции Вы просто создаете экземпляр этого класса:
CAPIHook g_MessageBoxA( "User32 dll", "MessageBoxA", (PROC) Hook_MessageBoxA, TRUE);
CAPIHook g_MessageBoxW("User32 dll", "MessageBoxW", (PROC) Hook_MessageBoxW, TRUE);
Мне приходится ставить ловушки на две функции; MessageBoxA и MessageBoxW. Обе эти функции находятся в User32.dll.
Я хочу, чтобы при обращении к MessageBoxA вызывалась Hook_MessageBoxA, а при вызове MessageBoxW— Hook_MessageBoxW.
Конструктор класса CAPIHook просто запоминает, какую API-функцию нужно перехватывать, и вызывает ReplaceMTEntryInAllMods, которая, собственно, и выполняет эту задачу.
Следующая открытая функция-член — деструктор. Когда объект CAPlHook выходит за пределы области видимисти, деструктор вызывает ReplacelATEntryInAllMods для восстановления исходного адреса идентификатора во всех модулях, т. e. для снятия ловушки.
Третий открытый член класса возвращает адрес исходной функции Эта функция обычно вызывается из подставной функции для обращения к перехватываемой функции. Вот как выглядит код функции Hook_MessageBoxA:
int WTNAPI Hook_MessageBoxA(HWND hWnd, PCSTR pszText, PCSIR pszCaption, UINT uType)
{
int nResult = ((PFNMESSAGEBOXA)(PROC) q_MessageBoxA) (hWnd, pszText, pszCaption, uType);
SendLastMsgBoxInfo(FALSE, (PVOTD) pszCaption, (PVOID) pszText, nResult);
return(nResult);
}
Этот код ссылается на глобальный объекту MessageBoxA класса CAPIHook. Приведение его к типу PKOC заставляет функцию-член вернуть адрес исходной функции MessageBoxA в User32.dll.
Всю работу по установке и снятию ловушек этот С++-класс берет на себя. До конца просмотрев файл CAPIIIook.cpp, Вы заметите, что мой С++-класс автоматически создает экземпляры объектов CAPIHook для перехвата вызовов LoadLibraryA, LoadLibraryW, LoadLibraryExA, LoadLibraryExW и GetProcAddress. Так что он сам справляется с проблемами, о которых я расскаяывал в предыдущем разделе.
Программа-пример LISLab
Эта программа, "27 LISLab.exe" (см. листинг на рис 27-4), — своего рода лаборатория, в которой Вы сможете поэкспериментировать с локальным состоянием ввода. Файлы исходного кода и ресурсов этой программы находятся в каталоге 27-LISLab на ком пакт-диске, прилагаемом к книге.
В качестве подопытных кроликов нам понадобятся два потока Один поток есть в нашей LISLab, a вторым будет Notepad Если на момент запуска LISLab программа Notepad не выполняется, LISLab сама запустит эту программу. После инициализации LISLab Вы увидите следующее диалоговое окно.

В левом верхнем углу окна — раздел Windows, его поля обновляются дважды в секунду, т. e дважды в секунду диалоговое окно получает сообщение WM_TIMER и в ответ вызывает функции GefFocus, GetActiveWtndow, GetForegroundWindow, GetCapture и GetClipCursor Первые четыре функции возвращают описатели окна (считываемые из переменных локального состояния ввода моего потока), через которые я могу определить класс и заголовок окна и вывести эту информацию на экран
Если я активизирую другое приложение (тот же Notepad), названия полей Focus и Activc меняются на (No Window), ц поля Foreground — на [Notepad] Umitled - Notepad Обратите внимание, что активизация Notepad заставляет LISLab считать, что ни ак тивных, ни находящихся в фокусе окон нет
Теперь поэкспериментируем со сменой фокуса. Выберем SetFocus в списке Func tion — в правом верхнем углу диалогового окна. Затем в поле Delay введем время (в секундах), в течение которого LISLab будет ждать, прсжде чем вызвать SetFocus B дан ном случае, видимо, лучше установить пулевое время задержки Позже я объясню, как используется поле Delay.
Выберем окно (описатель которого мы хотим передать функции SetFocus) в спис ке Notepad Windows And Self, расположенном в левой части диалогового окна Для эксперимента укажем [Notepad] Untitled - Notepad. Теперь все готово к вызову SetFocus.
Щелкните кнопку Delay и понаблюдайте, что произойдет в разделе Windows Ничего. Система отказалась менять фокус.
Если Вы действительно хотите перевести фокус на Notepad, щелкните кнопку Attach To Notepad, что заставит LISLab вызвать:
AttachThreadinput(GetWindowThreadProcessId(g_hwnrtNotepad, NULL), GetCurrentThreadId(), TRUE);
В результате этого вызова поток LISLab станет использовать ту же очередь вирту ального ввода, что и Notepad Кроме того, поток LISLab "разделит" переменные локаль ного состояния ввода Notepad
Если после щелчка кнопки Attach To Notepad Вы щелкнете окно Notepad, диало говое окно LISLab примет следующий вид.

Теперь, когда очереди ввода соединены друг с другом, LISLab способна отслежи вать изменения фокуса, происходящие в Notepad R приведенном выше диалоговом окне показано, что в данный момент фокус установлен на поле ввода А если мы от кроем в Notepad диалоговое окно File Opеn, то LISLab, продолжая следить за Notepad, покажет нам, какое окно Notepad получило фокус ввода, какое окно активно и т. д.
Теперь можно вернуться в LISLab, щелкнуть кнопку Delay и вновь попытаться зас тавить SetFocus перевести фокус на Notepad На этот раз всс пройдет успешно, пото му что очереди ввода соединены
Если хотите, поэкспериментируйте с SelActiweWindow, SetForegroundWtndow, Bring WindowToTop и SetWindowPos, выбирая нужную функцию в списке Function Попробуй те вызывать их и когда очереди соединены, и когда они разъединены; при этом обра щайте внимяние на различия в поведении функций
А сейчас я поясню, зачем предусмотрена задержка. Она заставляет LISLab вызывать указанную функцию только по истечении заданного числа секунд. Для иллюстрации возьмем такой пример. Но прежде отключите LISLab от Notcpad, щелкнув кнопку Detach From Notepad Затем в списке Notepad Windows And Self выберите —>This Dialog Box<—, a в списке Function — SerFocus и установите задержку на 10 секунд. На конец "нажмите" кнопку Delay и быстро щелкните окно Notepad, чтобы оно стало ак тивным Вы должны активизировать Notepad до того, как истекут заданные 10 секунд.
Пока идет отсчет времени задержки, справа от счетчика высвечивается слово Pending lIo истечении 10 секунд слово Pending меняется на Executed, и появляется
результат вызова функции Если Вы внимательно следите за работой программы, то увидите, что фокус теперь установлен на окно списка Function. Но ввод с клавиатуры по-прежнему направляется в Notepad. Таким образом, и поток LISLab, и поток Note pad — оба считают, что в фокусе находится одно из их окон Но на самом деле RIT остается связанным с потоком Notepad.
И последнее замечание в этой связи: SetFocus и SetActiveWindow возвращают опи сатель окна, которое изначально находилось в фокусе или было активным Инфор мация об этом окне отображается в поле PrevWnd. Кроме того, непосредственно пе ред вызовом SetForegroundWindow программа обращается к GetForegroundWindow, что бы получить описатель окна, которое располагалось "поверх" остальных окон. Эта информация также отображается в поле PrevWnd.
Далее поэкспериментируем с курсором мыши. Всякий раз, когда курсор проходит над диалоговым окном LISLab (но нс над каким-либо из его дочерних окон), он изоб ражается в виде вертикальной стрелки. По мере поступления диалоговому окну сооб щения от мыши добавляются в список Mouse Messages Received. Таким образом, Вы всегда в курсе того, когда диалоговое окно получает сообщения от мыши. Сдвинув курсор за пределы основного окна или поместив его на одно из дочерних окон, Вы увидите, что сообщения больше не вносятся в список.
Теперь переместите курсор в правую часть диалогового окна, установив его над текстом Click Right Mouse Button To Set Capture, а затем нажмите и удерживайте пра вую кнопку мыши. После этого LISLab вызовет функцию SctCapture, передав ей опи сатель своего диалогового окна. Заметьте: факт захвата мыши программой LISLab от разится в разделе Windows
Не отпуская правую кнопку, проведите курсор над дочерними окнами LISLab и понаблюдайте за сообщениями от мыши, добавляемыми к списку. Если курсор выве ден за пределы диалогового окна LISLab, программа по-прсжнему получает сообще ния от мыши. Курсор сохраняет форму вертикальной стрелки независимо от того, над каким участком экрана Вы его перемещаете.
Теперь мы можем увидеть другой эффект. Отпустите правую кнопку и следите, что произойдет. Окно, в свое время захватившее мышь, показывает, что LISLab по-прежне му считает мышь захваченной. Но сдвиньте курсор за пределы диалогового окна LISLab, и он больше нс останется вертикальной стрелкой, а сообщения от мыши пере станут появляться в списке Mouse Messages Received. Установив же курсор на какое-либо из дочерних окон LISLab, Вы сразу увидите: захват по-прежнему действует, потому что все эти окна используют один набор переменных локального состояния ввода.
Закончив эксперименты, отключите режим захвата одним из двух способов:
двойным щелчком правой кнопки мыши в любом месте диалогового окна LISLab (чтобы программа вызвала функцию ReleaseCapture);
щелчком окна, созданного любым другим потоком (отличным от потока LISLab). В этом случае система автоматически передаст диалоговому окну LISLab сооб щения о нажатии и отпускании кнопки мыши.
Какой бы способ Вы ни выбрали, обратите внимание на поле Capture в разделе Win dows — теперь оно отражает тот факт, что больше ни одно окно не захватывает мышь.
И еще два эксперимента, связанных с мышью в одном мы ограничим поле пере мещения курсора заданным прямоугольником, а в другом — изменим "видимость" курсора. Если Вы щелкнете кнопку "Top, Left", программа LISLab выполнит такой код:
RECT rc;
...
SetRect(&rc, 0, 0, GetSystemMetrics(SM_CXSCREEN) / 2, GetSystemMetrics(SM_CYSCREEN) / 2);
Это ограничит поле перемещения курсора верхней левой четвертью экрана. Пе реключившись в окно другого приложения нажатием клавиш Alt+Tab Вы заметите, что ограничение по-прежнемудействует Но система автоматически снимет его в резуль тате одного из таких действий:
Windows 98 щелчка заголовка окна другого приложения и последующего пере мещения этого окна;
Windows 2000 щелчка заголовка окна другого приложения (последующего переме щения этого окна не требуется),
Windows 2000 активизации Task Manager нажатием клавиш Ctrl+Shifl+Еsc и после дующей его отмены.
Для снятия ограничения ня перемещение курсора можно также щелкнуть кнопку Remove в диалоговом окне LISLab (если эта кнопка находится в пределах текущего поля перемещения курсора).
Щелчок кнопки Hide или Show вызывает выполнение соответственно.
ShowCursor(FALSE);
или
ShowCursor(TRUE);
Когда курсор скрыт, его не видно при перемещении над диалоговым окном LISLab. Но как только курсор оказывается за пределами окна, он снова видим. Для нейтрали зации действия кнопки Hide используйте кнопку Show. Заметьте, что скрытие курсо ра носит кумулятивный характер пять раз щелкнув кнопку Hide, придется столько же раз щелкнуть кнопку Show, прежде чем курсор станет видимым.
И последний эксперимент — с кнопкой Infinite Loop При ее щелчке выполняется код:
SetCursor(LoadCursor(NULL, IDC_NO));
for (,,)
Первая строка меняет форму курсора на перечеркнутый круг, а вторая выполняет бесконечный цикл. После щелчка кнопки Infinite Loop программа перестает реагиро вать на какой-либо ввод. Перемещая курсор в пределах диалогового окна LISLab, Вы увидите, что курсор остается перечеркнутым кругом. Если же Вы сместите его в дру гое окно, он получит форму, заданную в текущем окне.
Если теперь вернуть курсор в диалоговое окно LlSLab, система обнаружит, что программа не отвечает, и автоматически восстановит прежнюю форму курсора — перечеркнутый круг. Так что вошедший в бесконечный цикл поток хоть и не вызывает положительных эмоций, но пользоваться другими окнами не мешает.
Заметьте: если Вы переместите на окно зависшей программы LISLab другое окно, а потом уберете его, система отправит LISLab сообщение WM_PAINT и обнаружит, что данный поток не отвечает. Из этой ситуации система выходит элементарно: перерисовывает окно нереагирующего приложения. Конечно, перерисовать окно правильно она не в состоянии, так как ей не известно, что именно делало приложение, и поэтому она просто затирает окно цветом фона и перерисовывает рамку его окна.
Проблема теперь в том, что на экране есть ни на что не отвечающее окно.
Как от него избавиться? Под управлением Windows 98 нужно сначала нажать клавиши Ctrl+Alt+Del, чтобы на экране появилось окно Close Program.

B Windows 2000 можно либо щелкнуть правой кнопкой мыши кнопку приложе ния на панели задач, либо открыть окно Task Manager

Затем следует выбрать из списка название программы, которую нужно завершить (в данном случае — Local Input State Lab), и щелкнуть кнопку End Task Система попытается завершить LISLab "по-хорошему" (послав сообщение WM_CLOSE), но обнаружит, что приложение не отвечает Это заставит ее вывести одно из окон первое — в Windows 08 второе — в Windows 2000


Если Вы выберете кнопку End Task (в Windows 98) или End Now (в Windows 2000), система завершит LISLab принудительно Кнопка Cancel сообщит системе, что Вы передумали завершать приложение. Так что щелкните кнопку End Task или End Now, чтобы удалить LISLab из системы.
Общий смысл этих экспериментов — продемонстрировать отказоустойчивость системы. Ни одно приложение практически не способно привести систему в такое состояние, когда работа с другими приложениями станет невозможной. Кроме того, и Windows 98, и Windows 2000 автоматически освобождают все ресурсы, выделявшиеся потокам завершенного процесса, — утечки памяти не происходит!
Программа-пример LISWatch
Эта программа, "27 LISWatch.exe" (см. листинг на рис. 27-5), полезная утилита, ко торая отслеживает следующие окна: активное, находящееся в фокусе и захватившее мышь. Файлы исходного кода и ресурсов этой программы находятся в каталоге 27 LISWatch на компакт-диске, прилагаемом к книге. После запуска LISWatch открывает диалоговое окно, показанное ниже.

Получив сообщение WM_INITDIALOG, это окно вызывает SetTimer, чтобы создать таймер, срабатывающий два раза в секунду. А когда от таймера поступает сообщение WM_TIMER, обновляется содержимое диалогового окна — сведения об активном окне, окне в фокусе и окне, захватившем мышь В нижней части диалогового окна также сообщается, какое окно находится сейчас на переднем плане. Поэкспериментируйте с этой утилитой, просто щелкая окна, созданные различными приложениями. При этом Вы заметите, что LISWatch корректно сообщает информацию об окнах независимо от того, какой поток создал то или иное окно
Самая интересная часть кода этой программы выполняется при приеме сообще ния. WM_TIMER, поэтому, когда я буду давать пояснения, посматривайте на исходный код функции Dlg_ОпТimеr. И пока считайте, что глобальная переменная g_dwThread IdAttachTo равна 0. Ее назначение я объясню позже.
Так как у каждого потока свой набор переменных локалыюго состояния ввода, Dlg_OnTimer сначала вызывает GetForegroundWindow для определения окна, с которым имеетдело пользователь. GetForegroundWindow всегда возвращаетдействичелышй описатель окна независимо от того, какой поток создал это окно или вызвал эту функцию
Полученный таким образом описатель передается в GetWindowThreadProcessId, чтобы выяснить, какой поток связан с RIT. Далее LISWatch, вызвав AttachThreadInput, подключяется к переменным локального состояния ввода потока, связанного с RIT. После этого поток LISWatch может вызывать GetFocus, GetActiveWindow и GetCapture — любая и,з них возвращает действительный описатель окна. Вспомогательная функция CalcWndText формирует строки с именами классов и заголовками окон Потом эти строки показываются в диалоговом окне LISWatch И, наконец, перед самым возвратом управления Dlg_OnTimer снова вызыват: AttachThreadInput, на этот раз передавая FALSE в последнем параметре и тем самым отключая два потока друг от друга.
Ну вот, общее представление о программе LISWatch Вы получили. Однако она поддерживает и другую функциональность, о которой я хочу сейчас рассказать. После запуска LISWatch отслеживает активизацию окон во всех частях системы. На это и указывает надпись System-wide в верхней части диалогового окна. Но LISWatch может наблюдать за локальным состоянием ввода и только в одном потоке. Если Вы выберете именно этот режим, LISWatch будет сообщать Вам о том, что "думает" поток о своем состоянии ввода.
Чтобы LISWatch контролировала состояние ввода лишь одного потока, щелкните окно LISWatch левой кнопкой мыши и, не отпуская кнопку, переместите курсор мыши в окно, созданное другим потоком, а затем отпустите кнопку. Как только Вы это сде лаете, LISWarch присвоит глобальной переменной g_dwThreadIdAttachTo идентифика тор выбранного потока, значение которого заменит надпись System-wide в верхней части окна LISWatch. При ненулевом значении этой переменной функция Dlg_OnTimer ведет себя несколько иначе: теперь она подключает LISWatch к переменным локального состояния ввода выбранного Вами потока.
Проделаем один эксперимент. Зяпустите Calculator и выберите его окно в LISWatch. Активизировав окно Calculator, Вы увидите следующую информацию.

В моей системе идентификатор потока Calculator получил значение 0x000004ec. В данном случае LISWatch настроена на наблюдение зa локальным состоянием ввода этого потока если я щелкну любую кнопку или флажок в Calculator, LISWatch моментально отреагирует на это, сообщив о соответствующей смене фокуса
Однако, если Вы теперь активизируете окно, созданное другим приложением (у меня — Notepad), окно LISWatch будет выглядеть так, как показано ниже

Как видите, поток Calculator считает, что нет ни одного окна, которое находилось бы в фокусе, было бы активно или захватило бы мышь
Чтобы по-настоящему разобраться в концепции локального состояния ввода, запустите несколько копий LISWatch и настройге их на мониторинг отдельных потоков. После этого щелкайте в их окнах и следите, что происходит с локальным состоянием ввода каждого из потоков
Программа-пример lnjLib
Эта программа, "22 InjLib.exe" (см. листинг на рис. 22-3), внедряет DLL с помощью функции CreateRemoteThread Файлы исходного кода и ресурсов этой программы и DLL находятся в каталогах 22-InjLib и 22-ImgWalk на компакт-диске, прилагаемом к книге, После запуска InjLib на экране появляется диалоговое окно для ввода идентификатора выполняемого процесса, в который будет внедрена DLL. ,

Вы можете выяснить этот идентификатор через Task Manager Получив его, программа попытается открыть описатель этого процесса, вызвав OpenProcess и запросив соответствующие права доступа.
hProcess = OpenProcess(
PROCESS_CREATE THREAD | // для CreateRemoteThread
PROCESS_VM_OPERATION | // для VirtualAllocEx/VirtualFreeEx
PROCESS_VM_WRITE, // для WriteProcessMemory
FALSE, dwProcessId);
Если OpenProcess вернет NULL, значит, программа выполняется в контексте защиты, в котором открытие описателя этого процесса не разрешено Некоторые процессы вроде WinLogon, SvcHost и Csrss выполняются по локальной системной учетной записи, которую зарегистрированный пользователь не имеет права изменять. Описатель такого процесса можно открыть, только если Вы получили полномочия на отладку этих процессов. Программа ProcessInfo из главы 4 демонстрирует, как это делается.
При успешном выполнении OpenProcess записывает в буфер полное имя внедряемой DLL. Далее программа вызывает lnject!ib и передает сй описатель удаленного процесса. И, наконец, после возврата из InjectLib программа выводит окно, где сообщает, успешно ли внедрена DLL, а потом закрывает описатель процесса.
Наверное, Вы заметили, что я специально проверяю, нс равен ли идентификатор процесса нулю. Если да, то вместо идентификатора удаленного процесса я передаю идентификатор процесса самой InjLib.exe, получаемый вызовом GetCurrenlProtessId. Тогда при вызове Injectlib библиотека внедряется в адресное пространство процесса InjLib. Я сделал это для упрощения отладки. Сами понимаете, при возникновении ошибки иногда трудно определить, в каком процессе она находится: локальном или удаленном. Поначалу я отлаживал код с помощью двух отладчиков: один наблюдал за InjLib, другой — за удаленным процессом Это оказалось стратттно неудобно Потом меня осенило, что InjLib способна внедрить DLL и в себя, т. e. в адресное пространство вызывающего процесса. И это сразу упростило отладку.
Просмотрев начало исходного кода модуля, Вы увидите, что InjectLib — на самом деле макрос, заменяемый на InjectLibA или InjectLibW в зависимости от того, как компилируется исходный код. В исходном коде достаточно комментариев, и я добавлю лишь одно. Функция lnjectLibA весьма компактна. Она просто преобразует полное имя DLL из ANSI в Unicode и вызывает lnjetlLibW, которая и делает всю работу. Тут я придерживаюсь того подхода, который я рекомендовал в главе 2.
Программа-пример lnterlockedType
Эта программа, "10_IntertockedType ехе" (см. листинг на рис. 10-2), предназначена для тестирования только что описанных классов. Файлы исходного кода и ресурсов этой программы находятся в каталоге l0-InterlockedType на компакт-диске, прилагаемом к книге. Как я уже говорил, такие приложения я всегда запускаю под управлением отладчика, чтобы наблюдать за всеми функциями и переменными — членами классов.
Программа иллюстрирует типичный сценарий программирования, который выглядит так. Поток порождает несколько рабочих потоков, а затем инициализирует блок памяти. Далее основной поток пробуждает рабочие потоки, чтобы они начали обработку содержимого этого блока памяти. В данный момент основной поток должен приостановить себя до тсх пор, пока все рабочие потоки не выполнят свои задачи. После этого основной поток записывает в блок памяти новые данные и вновь пробуждает рабочие потоки.
На примере этого кода хорошо видно, насколько тривиальным становится реше ние этой распространенной задачи программирования при использовании С++. Класс CWhenZero дает нам гораздо больше возможностей — не один лишь инверсный семафор. Мы получаем теперь безопасный в многопоточной среде объект данных, ко торый переходит в свободное состояние, когда его значение обнуляется! Вы можете не только увеличивать и уменьшать счетчик семафора на 1, но и выполнять над ним любые математические и логические операции, в том числе сложение, вычитание, умножение, деление, вычисления по модулю! Так что объект CWhenZero намного функциональнее, чем объект ядра "семафор".
С этими классами шаблонов С++ можно много чего придумать. Например, создать класс CInterlockedString, производный от CInterlockedType, и с его помощыо безопасно манипулировать символьными строками. А потом создать класс CWhenCertain String, производный от CInterlockedString, чтобы освобождать объект ядра "событие", когда строка принимает определенное значение (или значения). В общем, возможности безграничны.
Программа-пример MemReset
Эта программа, "15 MemReset.exe" (см. листинг на рис. 15-2), демонстрирует, как ра ботает флаг MEM_RESET. Файлы исходного кода и ресурсов этой программы находятся в каталоге 15-McmReset на компакт-диске, прилагаемом к книге
Первое, что делает код этой программы, — резервирует регион и передает ему физическую память. Поскольку размер региона, переданный в VirtualAlloc, равен 1024 байтам, система автоматически округляет это значение до размера страницы. Затем функция lstrcpy копирует в этот буфер строку, и содержимое страницы оказывается измененным. Если система впоследствии сочтет, что ей нужна страница, содержащая наши данные, она запишет эту страницу в страничный файл Когда наша программа попытается считать эти данные, система автоматически загрузит страницу из стра ничного файла в оперативную память
После записи строки в страницу памяти наша программа спрашивает у пользо вателя, понадобятся ли еще эти данные. Если пользователь выбирает отрицательный
ответ (щелчком кнопки No), программа сообщает системе, что страница не изменя лась, для чего вызывает VirtualAlloc с флагом MEM_RESET
Для демонстрации того факта, что память действительно сброшена, смоделируем высокую нагрузку на оперативную память, для чего:
Получим общий размер оперативной памяти на компьютере вызовом Global MemoryStatus
Передадим эту память вызовом VirtualAlloc. Данная операция выполняется очень быстро, поскольку система не выделяет оперативную память до тех пор, пока процесс нс изменит какие-нибудь страницы.
Изменим содержимое только что переданных страниц через функцию Zero Memory. Это создает высокую нагрузку на оперативную память, и отдельные страницы выгружаются в страничный файл.
Если пользователь захочет оставить данные, сброс нс осуществляется, и при пер вой же попытке доступа к ним соответствующие страницы будут подгружаться в опе ративную память из с граничного файла. Если же пользователь откажется от этих дан ных, мы выполняем сброс памяти, система нс записывает их в страничный файл, и это ускоряет выполнение программы.
После вызова ZeroMemory я сравниваю содержимое страницы данных со строкой, Которая была туда записана. Если данные не сбрасывались, содержимое идентично, а если сбрасывались — то ли идентично, то ли нет. В моей программе содержимое никогда не останется прежним, посколькуя заставляю сиоему выгрузить все страни цы оперативной памяти в страничный файл. Но если бы размер выгружаемой облас ти был меньше общего объема оперативной памяти, то не исключено, что исходное содержимое все равно осталось бы в памяти. Так что будьте осторожны!
Программа-пример MMFShare
Эта программа, "17 MMFShare.exe" (см. листинг на рис. 17-3), демонстрирует, как про исходит обмен данными между двумя и более процессами с помощью файлов, про ецируемых в память. Файлы исходного кода и ресурсов этой программы находятся в каталоге 17-MMFShare на компакт-диске, прилагаемом к книге.
Чтобы понаблюдать за происходящим, нужно запустить минимум две копии MMFShare. Каждый экземпляр программы создаст свое диалоговое окно.
Чтобы переслать данные из одной копии MMFShare в другую, наберите какой нибудь текст в поле Data. Затем щелкните кнопку Create Mapping Of Data. Программа вызовет функцию CreateFileMapping, чтобы создать объект "проекция файла" разме ром 4 Кб и присвоить ему имя MMFSharedData (ресурсы выделяются объекту из стра
ничного файла) Увидев, что объект с таким именем уже существует, программа вы даст сообщение, что не может создать объект. Л если такого объекта нет, программа создаст объект, спроецирует представление файла на адресное пространство процесса и скопирует данные из поля Data в проецируемый файл.

Далее MMFShare прекратит проецировать представление файла, отключит кнопку Create Mapping Of Data и активизирует кнопку Close Mapping Of Data. На этот момент проецируемый в память файл с именем MMFSharedData будет просто "сидеть" где-то в системе. Никакие процессы пока не проецируют представление на данные, содер жащиеся в файле.
Если Вы теперь перейдете в другую копию MMFShare и щелкнете там кнопку Open Mapping And Get Data, программа попытается найти объект "проекция файла" с име нем MMFSharedData через функцию OpenFileMapping, Если ей не удастся найли объект с таким именем, программа выдаст соответствующее сообщение В ином случае она спроецирует представление объекта на адресное пространство своего процесса и скопирует данные из проецируемого файла в поле Data. Вот и все! Вы переслали дан ные из одного процесса в другой
Кнопка Close Mapping OfData служит для закрытия объекта "проекция файла", что высвобождает физическую память, занимаемую им в страничном файле. Если же объект "проекция файла" не существует, никакой другой экземпляр программы MMFShare не сможет открыть зтот объект и получить от него данные Кроме того, если один экземпляр программы создал объект "проекция файла", то остальным повторить его создание и тем самым перезаписать данные, содержащиеся в файле, уже не удастся.
Программа-пример MMFSparse
Эта программа, "17 MMFSparseexe" (см листинг на рис. 17-4), демонстрирует, как создать проецируемый в память файл, связанный с разреженным файлом NTFS 5 Файлы исходного кода и ресурсов этой программы находятся в каталоге 17-MMFSparse на компакт-диске, прилагаемом к книге После запуска MMFSparse па экране появля ется окно, показанное ниже.

Когда Вы щелкнсте кнопку Create а 1 MB (1024 KB) Sparse MMF, программа попы тается создать разреженный файл "C:\MMFSpanse". Если Ваш диск С не является томом NTFS 5, у программы ничего не получится, и ее процесс завершится А если Вы созда ли том NTFS 5 на каком-то другом диске, модифицируйте мою программу и переком пилируйте ее, чтобы посмотреть, как она работает
После создания разреженный файл проецируется на адресное пространство про цесса. В поле Allocated Kangcs (внизу окна) показывается, какие части файла действи тельно связаны с дисковой памятью. Изначально файл не связан ни с какой памятью, и в этом поле сообщается "No allocated ranges in the file" ("В файле нет выделенных диапазонов").
Чтобы считать байт, просто введите число в поле Offset и щелкните кнопку Read Byte. Введенное Вами число умножается на 1024 (1 Кб), и программа, считав байт по полученному адресу, выводит его значение в поле Byte Если адрес попадает в область, не связанную с физической памятью, в этом поле всегда показывается нулевой байт.
Для записи байта введите число в поле Offset, a значение байта (0-255) — в поле Byte. Потом, когда Вы щелкнете кнопку Wrice Byte, смещение будет умножено на 1024, и байт по соответствующему адресу получит новое значение Операция записи мо жет заставить файловую систему передать физическую память какой-либо части фай ла Содержимое поля Allocated Ranges обновляется после каждой операции чтения или записи, показывая, какие части файла связаны с физической памятью на данный мо мент. Вот как вьплядит окно программы после записи всего одного байта по смеще нию 1 024 000 (1000 x 1024).

На этой иллюстрации видно, что физическая память выделена только одномуди апазону адресов — размером 65 536 байтов, начиняя с логического смещения 983 040 от начала файла С помощью ExpIorer Вы можете просмотреть свойства файла C:\MMFSparbe, как показано ниже.

Заметьте: на этой странице свойств сообщается, что длина файла равна 1 Мб (это виртуальный размер фаЙла), по на деле он занимает на диске только 64 Кб.
Последняя кнопка, Free All Allocated Regions, заставляет программу высвободить всю физическую память, выделенную для файла; таким образом, соответствующее дисковое пространство освобождается, а все байты в файле обнуляются.
Теперь поговорим о том, как работает эта программа. Чтобы упростить ее исход ный код, я создал С++-класс CSparseStream (который содержится в файле Sparse Stream.h) Этот класс инкапсулирует поддержку операций с разреженным файлом или потоком данных (stream). В файле MMFSparse.cpp я создал другой С++-класс, CMMFSparse, производный от CSparseStream. Так что объект класса CMMFSparse обла дает не только функциональностью CSparseStream, но и дополнительной, необходи мой для использования разреженного потока данных как проецируемого в память файла. В процессе создается единственный глобальный экземпляр класса CMMF Sparse — переменная g_mmf. Манипулируя разреженным проецируемым файлом, про грамма часто ссылается на эту глобальную переменную.
Когда пользователь щелкает кнопку Create а 1MB (1024 KB) Sparse MMF, програм ма вызывает CreateFile для создания нового файла в дисковом разделе NTFS 5. Пока что это обычный, самый заурядный файл Но потом я вызываю метод Initialize гло бального объекта g_mmf, передавая ему описатель и максимальный размер файла (1 Мб). Метод Initialize в свою очередь обращается к CreateFileMapping и создает объект ядра "проекция файла" указанного размера, а затем вызывает MapViewOfFile, чтобы сделать разреженный файл видимым в адресном пространстве данного процесса
Когда Initialize возвращает управление, вызывается функция Dlg_ShowAllocated Ranges Используя Windows-функции, она перечисляет диапазоны логических адре сов в разреженном файле, которым передана физическая память.
Начальное смеще ние и длина каждого такого диапазона показываются в нижнем поле диалогового окна В момент инициализации объекта g_mmf файлу на диске еще не выделена физичес кая память, и данное поле отражает этот факт.
Теперь пользователь может попытаться считать или записать какие-то байты в пределах разреженного проецируемого файла При записи программа извлекает зна чение байта и смещение из соответствующих полей, а затем помещает этот байт по вычисленному адресу в объект g_mmf. Такая операция может потребовать от файло вой системы передачи физической памяти логическому блоку файла, но программа не принимает в этом участия.
При чтении объекта g_mmf возвращается либо реальное значение байта, если дан ному диапазону адресов передана физическая память, либо 0, если память не передана,
Моя программа также демонстрирует, как вернуть файл в исходное состояние, высвободив все выделенные сму диапазоны адресов (после этого он фактически не занимает места ня диске) Реализуется это так. Пользователь щелкает кнопку Free All Allocated Regions. Однако освободить все диапазоны адресов, выделенные файлу, ко торый проецируется в память, нельзя Поэтому первое, что делает программа, — вы зывает метод ForceClose объекта g_mmf Этот метод обращается к UnmapViewOfFile, а потом — к CloseHandle, передавая описатель объекта ядра "проекция файла".
Далее вызывается метод DecommitPortionOfStream, который освобождает всю па мять, выделенную логическим байтам в файле. Наконец, программа вновь обращает ся к методу Initialize объекча g_mmf, и тот повторно инициализирует файл, проеци руемый на адресное пространство данного процесса. Чтобы подтвердить освобожде ние всей выделенной памяти, программа вызывает функцию Dlg_ShowAllocatedRanges которая выводит в поле строку "No allocated ranges in the file".
И последнее. Используя разреженный проецируемый файл в реальном приложе нии, Вы, наверное, захотите при закрытии файла урезать его логический размер до фактического Отсечение концевой части разреженного файла, содержащей нулевые
байты, не влияет на занимаемый им объем дискового пространства, но позволяет Explorer и команде dir сообщать точный размер файла С этой целью Вы должны пос ле вызова метода ForceClose использовать функции SetFilePointer и SetEndOfFile.
Программа-пример Optex
Эта программа, "10 Optex.exe" (см.листинг на рис, 10-1), предназначенадля проверки того, что класс COptex работает корректно. Файлы исходного кода и ресурсов этой программы находятся в каталоге 10-Optex на компакт-диске, прилагаемом к книге. Я всегда запускаю такие приложения под управлением отладчика, чтобы наблюдать за всеми функциями и переменными — членами классов.
При запуске программа сначала определяет, является ли она первым экземпляром. Для этого я создаю именованный объект ядра "событие". Реально я им не пользуюсь, а просто смотрю, вернет ли GetLastError значение ERROR_ALREADY_EXISTS. Если да, значит, это второй экземпляр программы. Зачем мне два экземпляра этой программы, я объясню позже.
Если же это первый экземпляр, я создаю однопроцессный объект COptex и вызываю свою функцию FirstFunc. Она выполняет серию операций с объектом-оптексом и создает второй поток, который манипулирует тем же оптексом. На этом этапе с оптексом работают два потока из одного процесса. Что именно они делают, Вы узнаете, просмотрев исходный код. Я пытался охватить все мыслимые сценарии, чтобы дать шанс на выполнение каждому блоку кода в классе COptex.
После тестирования однопроцессного оптекса я начинаю проверку межпроцессного оптекса. В функции _tWinMain по завершении первого вызова FirstFunc я создаю другой объект-оптекс COptex. Но на этот раз я присваиваю ему имя — CrossOptexTest. Простое присвоение оптексу имени в момент создания превращает этот объект в межпроцессный. Далее я снова вызываю FirstFunc, передавая сй адрес межпроцессного оптекса. При этом FirstFunc выполняет в основном тот же код, что и раньше. Но теперь она порождает не второй поток, а дочерний процесс.
Этот дочерний процесс представляет собой всего лишь второй экземпляр той же программы. Однако, создав при запуске объект ядра "событие", она обнаруживает, что такой объект уже существует. Тем самым она узнает, что является вторым экземпляром, и выполняет другой код (отличный от того, который выполняется первым экземпляром). Первое, что делает второй экземпляр, — вызывает DebugBreak:
VOID DebugBreak();
Эта удобная функция инициирует запуск отладчика и его подключение к данному процессу. Это здорово упрощает мне отладку обоих экземпляров данной программы. Далее второй экземпляр создает межпроцессный оптекс, передавая конструктору строку с тем же именем. Поскольку имена идентичны, оптекс становится разделяемым между обоими процессами. Кстати, один оптекс могут разделять более двух процессов.
Наконец, второй экземпляр программы вызывает функцию SecondFunc, передавая сй адрес межпроцессного оптекса, и с этого момента выполняется тот же набор тестов. Единственное, что в них меняется, — два потока, манипулирующие оптексом, принадлежат разным процессам.
Программа-пример Processlnfo
Эта программа, "04 ProcessInfo.exe" (см листинг на рис. 4-6), демонстрирует, как со здать очень полезную утилиту на основе ToolHelp-функций. Файлы исходного кода и ресурсов программы находятся в каталоге 04-ProcessInfo на компакт-диске, прилага емом к книге. После запуска Processlnfo открывается окно, показанное на рис. 4-4.
ProcessInfo сначала перечисляет все процессы, выполняемые в системе, а затем выводит в верхний раскрывающийся список имена и идентификаторы каждого про цесса. Далее выбирается первый процесс и информация о нем показывается в боль шом текстовом поле, доступном только для чтения. Как видите, для текущего процес са сообщается его идентификатор (вместе с идентификатором родительского процес са), класс приоритета и количество потоков, выполняемых в настоящий момент в контексте процесса. Объяснение большей части этой информации выходит за рамки данной главы, но будет рассматриваться в последующих главах.
При просмотре списка процессов становится доступен элемент меню VMMap. (Он отключается, когда Вы переключаетесь на просмотр информации о модулях.) Выб рав элемент меню VMMap, Вы запускаете программу-пример VMMap (см. главу 14). Эта программа "проходит" по адресному пространству выбранного процесса.
В информацию о модулях входит список всех модулей (EXE- и DLL-файлов), спро~ ецированных на адресное пространство текущего процесса. Фиксированным моду лем (fixed module) считается тот, который был неявно загружен при инициализации процесса. Для явпо загруженных DLL показываются счетчики числа пользователей этих DLL. Во втором столбце выводится базовый адрес памяти, на который спроеци
рован модуль. Если модуль размещен не по заданному для нсго базовому адресу, в скобках появляется и этот адрес. В третьем столбце сообщается размер модуля в бай тах, а в последнем — полное (вместе с путем) имя файла этого модуля. И, наконец, внизу показывается информация о потоках, выполняемых в данный момент в контек сте текущего процесса. При этом отображается идентификатор потока (thread ID, TID) и его приоритет.

Рис. 4-4. ProcessInfo в действии
В дополнение к информации о процессах Вы можете выбрать элемент меню Modu les. Это заставит ProcessInfo перечислить все модули, загруженные в системе, и поме стить их имена в верхний раскрывающийся список Далее ProcessInfo выбирает пер вый модуль и выводит информацию о нем (рис. 4-5).
В этом режиме утилита ProcessInfo позволяет легко определить, в каких процес сах задействован данный модуль. Как видите, полное имя модуля появляется в верх ней части текстового поля, а в разделе Process Information перечисляются все процес сы, содержащие этот модуль. Там же показываются идентификаторы и имена процес сов, в которые загружен модуль, и его базовые адреса в этих процессах.
Всю эту информацию утилита ProcessInfo получает в основном от различных ToolHelp-функций. Чтобы чуточку упростить работу с ToolHelp-функциями, я создал С++-класс CToolhelp (содержащийся в файле Toolhelp.h). Он инкапсулирует все, что связано с получением "моментального снимка" состояния системы, и немного облег чает вызов других TooIHelp-функций.
Особый интерес представляет функция GetModulePreferredBaseAddr в файле Pro cessInfo.cpp:
PVOID GetModulePreferredBaseAddr( DWORD dwProcessId, PVOID pvModuleRemote);

Рис. 4-5. Processlnfo перечисляет все процессы, в адресные пространства которых загружен модуль User32.dll
Принимая идентификатор процесса и адрес модуля в этом процессе, она просмат ривает его адресное пространство, находит модуль и считывает информацию из заго ловка модуля, чтобы определить, какой базовый адрес для него предпочтителен. Мо дуль должен всегда загружаться именно по этому адресу, а иначе приложения, исполь зующие данный модуль, потребуют больше памяти и будут инициализироваться мед леннее. Поскольку такая ситуация крайне нежелательна, моя утилита сообщает о слу чаях, когда модуль загружен не по предпочтительному базовому адресу. Впрочем, на эти темы мы поговорим в главе 20 (в разделе "Модификация базовых адресов модулей").
Программа-пример Queue
Эта программа, "09 Queue.exe" (см. листинг па рис. 9-2), управляет очередью обраба тываемых элементов данных, используя мьютекс и семафор. Файлы исходного кода и ресурсов этой программы находятся в каталоге 09-Queue на компакт-диске, прилд гасмом к книге. После запуска Queue открывается окно, показанное ниже.

При инициализации Queue создает четыре клиентских и два серверных потока. Каждый клиентский поток засыпает на определенный период времени, а затем поме щает в очередь элемент данных. Когда в очередь ставится новый элемент, содержи мое списка Client Threads обновляется Каждый элемент данных состоит из номера клиентского потока и порядкового номера запроса, выданного этим потоком. Напри мер, первая запись в списке сообщает, что клиентский поток 0 поставил в очередь свой первый запрос. Следующие записи свидетельствуют, что далее свои первые зап росы выдают потоки 1-3, потом поток 0 помещает второй запрос, то же самое дела ют остальные потоки, и все повторяется.
Серверные потоки ничего не делают, пока в очереди не появится хотя бы один элемент данных. Как только он появляется, для его обработки пробуждается один из серверных потоков. Состояние серверных потоков отражается в списке Server Threads Первая запись говорит о том, что первый запрос от клиентского потока 0 обрабаты вается серверным потоком 0, вторая запись — что первый запрос от клиентского потока 1 обрабатывается серверным потоком 1, и т. д.
В этом примере серверные потоки не успевают обрабатывать клиентские запро сы и очередь в конечном счете заполняется до максимума. Я установил максималь ную длину очереди равной 10 элементам, что приводит к быстрому заполнению этой очереди. Кроме того, на четыре клиентских потока приходится лишь два серверных. В итоге очередь полностью заполняется к тому моменту, когда клиентский поток 3 пытается выдать свой пятый запрос.
О'кэй, что делает программа, Вы поняли-, теперь посмотрим — как она это делает (что гораздо интереснее). Очередью управляет С++-класс CQueue:
class CQueue
{
public:
Struct ELEMENT
{
int m_nThreadNum, m_nRequestNum;
// другие элементы данных должны быть определены здесь
};
typedef ELEMENT* PELEMENT;
private:
PELEMENT m_pElements; // массив элементе, подлежащих обработке
int m_nMaxElements; // количество элементов в массиве
HANDLE m_h[2]; // описатели мьютекса и семафора
HANDLE &m_hmtxQ; // ссылка на m_h[0]
HANDLE &rn_hsemNumElemenls; // ссылка на rc_h[1]
public:
COueue(int nMaxElements);
~CQueue();
BOOL Append(PELtMLNT pElement, DWORD dwMilHseconds);
BOOL Remove(PELEMENT pElement, DWORD dwMilliseconds);
};
Открытая структура ELEMENT внутри этого класса определяет, что представляет собой элемент данных, помещаемый в очередь. Его реальное содержимое в данном случае не имеет значения. В этой программе-примере клиентские потоки записыва ют в элемент данных собственный номер и порядковый номер своего очередного запроса, а серверные потоки, обрабатывая запросы, показывают эту информацию в списке. В реальном приложении такая информация вряд ли бы понадобилась.
Что касается закрытых элементов класса, мы имеем т_pElements, который указы вает на массив (фиксированного размера) структур ELEMENT. Эти данные как раз и нужно защищать от одновременного доступа к ним со стороны клиентских и сервер ных потоков. Элемент m_nMaxElements определяет размер массива при создании объекта CQueue. Следующий элемент, m_h, — это массив из двух описателей объек тов ядра. Для корректной защиты элементов данных в очереди нам нужно два объек та ядра: мьютекс и семафор. Эти дня объекта создаются в конструкторе CQueuc; в нем же их описатели помещаются в массив m_h.
Как Вы вскоре увидите, программа периодически вызывает WaitForMultipleObjectS, передавая этой функции адрес массива описателей. Вы также убедитесь, что програм ме время от времени приходится ссылаться только на один из этих описателей. Что бы облегчить чтение кода и его модификацию, я объявил два элемента, каждый из которых содержит ссылку на один из описателей, — m_bmtxQ и m_hsemNumElements. Конструктор CQueue инициализирует эти элементы содержимым m_h[0] и m_h[l] соответственно.
Теперь Вы и сами без труда разберетесь в методах конструктора и деструктора CQueue, поэтому я перейду сразу к методу Append. Этот метод пытается добавить ELEMENT в очередь. Но сначала он должен убедиться, что вызывающему потоку раз решен монопольный доступ к очереди. Для этого метод Append вызывает WaitFor~ SingleObject, передавая ей описатель объекта-мьютекса, m_hmlxQ. Если функция воз вращает WAIT_OBJECT_0, значит, поток получил монопольный доступ к очереди.
Далее метод Append должен попытаться увеличить число элементов в очереди, вызвав функцию ReleaseSemaphore и передав ей счетчик числа освобождений (release count), равный 1. Если вызов ReleaseSemaphore проходит успешно, в очереди еще есть место, и в нее можно поместить новый элемент. К счастью, ReleaseSemapbore возвра щает в переменной lPreviousCount предыдущее количество элементов в очереди. Бла годаря этому Вы точно знаете, в какой элемент массива следует записать новый эле
мент данных. Скопировав элемент в массив очсрсди, функция возвращает управле ние. По окончании этой операции Append вызывает ReleaseMutex, чтобы и другие потоки могли получить доступ к очереди. Остальной код в методе Append отвечает за обработку ошибок и неудачных вызовов.
Теперь посмотрим, как серверный поток вызывает метод Remove для выборки эле мента из очереди. Сначала этот метод должен убедиться, что вызывающий поток по лучил монопольный доступ к очереди и что в ней есть хотя бы один элемент. Разуме ется, серверному потоку нст смысла пробуждаться, если очередь пуста. Поэтому ме- i тод Remove предварительно обращается к WaitForMultipleObjects, передавая ей описа тели мьютекса и семафора. И только после освобождения обоих объектов серверный поток может пробудиться.
Если возвращается WAIT_OBJECT_0, значит, поток получил-монопольный доступ к очереди и в ней есть хотя бы один элемент. В этот момент программа извлекает из массива элемент с индексом 0, а остяльные элементы сдвигает вниз на одну позицию. Это, конечно, не самый эффективный способ реализации очереди, так как требует слишком большого количества операций копирования в памяти, но наша цсль зак лючается лишь в том, чтобы продемонстрировать синхронизацию потоков.По окон чании этих операций вызывается ReleaseMutex, и очередь становится доступной дру гим потокам.
Заметьте, что объект-семафор отслеживает, сколько элементов находится в оче реди. Вы, наверное, сразу же поняли, что это значение увеличивается, когда метод Append вызывает ReleaseSemaphore после добавления нового элемента к очереди. Но как оно уменьшается после удаления элемента из очереди, уже не столь очевидно. Эта операция выполняется вызовом WaitForMultipleObjects из метода Remove. Тут надо вспомнить, что побочный эффект успешного ожидания семафора заключается в уменьшении его счетчика на 1. Очень удобно для нас.
Теперь, когда Вы понимаете, как работает класс CQueue, Вы легко разберетесь в остальном коде этой программы.
Программа-пример Scheduling Lab
Эта прогрдмма, "07 SchedLab ехе" (см листинг на рис 7-1), позволяет эксперименти ровать с классами приоритетов процессов и относительными приоритетами потоков
и исследовать их влияние на общую производительность системы. Файлы исходного кода и ресурсов этой программы находятся в каталоге 07-SchedLab нз компакт-диске, прилагаемом к книге После запуска SchedLab открывается окно, показанное ниже

Изначально первичный поток работает очень активно, и степень использования процессора подскакивает до 100% Все, чем он занимается, — постоянно увеличивает исходное значение на 1 и выводит текущее значение в крайнее справа окно списка Все эти числа не несут никакой смысловой информации; их появление просто демон стрирует, что поюк чем-то занят Чтобы прочувствовать, как повлияет на него изме нение приоритета, запустите по крайней мере два экземпляра программы. Можете также открыть Task Manager и понаблюдать за нагрузкой на процессор, создаваемой каждым экземпляром
В начале теста процессор будет загружен на 100%, и Вы увидите, что все экземп ляры SchedLab получают примерно равные кванты процессорного времени (Task Manager должен показать практически одинаковые процентные доли для всех ее эк земпляров.) Как только Вы поднимете класс приоритета одного из экземпляров до above normal или high, львиную долю процессорного времени начнет получать имен но этот экземпляр, а аналогичные показатели для других экземпляров резко упадут. Однако они никогда не опустятся до нуля — это действует механизм динамического повышения приоритета "голодающих" процессов Теперь Вы можете самостоятельно поиграть с изменением классов приоритетов процессов и относительных приорите тов потоков. Возможность установки класса приоритета real-time я исключил наме ренно, чтобы не нарушить paбoтy операционной системы. Если Вы все же хотите поэкспериментировать с этим приоритетом, Вам придется модифицировать исход ный текст моей программы
Используя поле Sleep, можно приостановить первичный поток на заданное число миллисекунд в диапазоне oт 0 до 9999 Попробуйте приостанавливать его хотя бы на 1 мс и посмотрите, сколько процессорного времени это позволит сэкономить.
На своем ноутбуке с процессором Pentium II 300 МГц, я выиграл аж 99% - впечатляет!
Кнопка Suspend заставляет первичный поток создать дочерний поток, который приостанавливает родительский и выводит следующее окно.
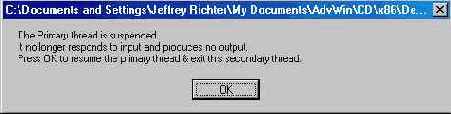
Пока это окно открыто, первичный поток полностью отключается от процессо ра, а дочерний тоже не требует процессорного времени, так как ждет от пользовате ля дальнейших действий Вы можете свободно перемещать это окно в пределах экра на или убрать его в сторону от основною окна программы. Поскольку первичный поток остановлен, основное окно не принимает оконных сообщений (в том числе
WM_PAINT). Это еще раз доказывает, что поток задержан Закрыв окно с сообщением. Вы возобновите первичный поток, и нагрузка на процессор снова возрастет до 100%. А теперь проведите еще один эксперимент. Откройте диалоговое окно Performance Options (я говорил о нем в предыдущем разделе) и выберите переключатель Back ground Services (или, наоборот, Application) Потом запустите несколько экземпляров мосй программы с классом приоритета normal и выберите один из них, сделав его активным процессом. Вы сможете наглядно убедиться, как эти переключатели влия ют на активные и фоновые процессы
Программа-пример SEHTerm
Эта программа, "23 SEHTerm.exe" (см. листинг на рис. 23-1), демонстрирует обработ чики завершения. Файлы исходного кода и ресурсов этой программы находятся в каталоге 23-SEHTerm на компакт-диске, прилагаемом к книге.
После запуска SEHTerm ее первичный поток входит в блок try. Из него открывает ся следующее окно.

В этом окне предлагается обратиться к памяти по недопустимому адресу. (Боль шинство приложений не столь тактично — они обращаются по недопустимым адре сам, никого не спрашивая.) Давайте обсудим, что случится, если Вы щелкнете кнопку Yes. B этом случае поток попытается записать значение 5 по нулевому адресу памяти. Запись по нулевому адресу всегда вызывает исключение, связанное с нарушением доступа. А когда поток возбуждает такое исключение, Windows 98 выводит окно, по казанное ниже.
В Windows 2000 аналогичное окно выглядит иначе

Если Вы теперь щелкнитe кнопку Сlоsе (в Windows 98) или OK (в Windows 2000), процесс завершится. Однако в исходном коде этой программы присутствует блок finally, который будет выполнен до того, как процесс завершится Из этого блока от крывается следующее окно.

Блок finаllу выполняется потому, что происходит ненормальный выход из связан ного с пим блока try. После закрытия этого окна процесс завершается.
О'кэй, а сейчас снова запустим эту программу. Но на этот раз попробуйте щелк нуть кнопку No, чтобы избежать обращения к памяти по недопустимому адресу. Тог да поток естественным образом перейдет из блока try в блок finаllу, откуда будет от крыто следующее окно.

Обратите внимание, что на этот раз в окне сообщается о нормальном выходе из блока try Когда Вы закроете это окно, поток выйдет из блока finаllу и покажет после днее окно.

Послетою как Вы скроете и это окно, процесс нормально завершится, посколь ку функция WinMain вернет управление. Заметьте, что данное окно не появляется при аварийном завершении процесса.
Программа-пример Spreadsheet
Этя программа, "25 Spreadsheet.exe" (см. листинг на рис. 25-1), демонстрирует, как передавать физическую память зарезервированному региону адресного простран ства — но не всему региону, а только его областям, нужным в данный момент. Алго ритм опирается на структурную обработку исключений. Файлы исходного кода и ре сурсов этой программы находятся в каталоге 25-Spreadshect на компакт-диске, при лагаемом к книге. После запуска Spreadsheet на экране появляется диалоговое окно, показанное ниже.

Программа Spreadsheet резервирует регион для двухмерной таблицы, содержащей 256 строк и 1024 колонки, с размером ячеек по 1024 байта Если бы программа за ранее передавала физическую память под всю таблицу, то ей понадобилось бы 268 435 456 байтов, или 256 Мб. Поэтому для экономии драгоценных ресурсов про грамма резервирует в своем адресном пространстве регион размером 256 Мб, нс пе редавая ему физическую память.
Допустим, пользователь хочет поместить значение 12345 в ячейку на пересечении строки 100 и колонки 100 (как на предыдущей иллюстрации) Кактолько он щелкнет кнопку Write Cell, программа попытается записать это значение в указанную ячейку таблицы. Естественно, это вызовет нарушение доступа. Но, так как я использую в про грамме SEH, мой фильтр исключений, распознав попытку записи, выведет в нижней части диалогового окна сообщение "Violation: Attempting to Write", передаст память под нужную ячейку и заставит процессор повторить выполнение команды, возбудив шей исключение Теперь значение будет сохранено в ячсйкс таблицы, поскольку этой ячейке нередана физическая память.
Проделаем еще один эксперимент. Попробуем считать значение из ячейки на пересечении строки 5 и колонки 20 Этим мы вновь вызовем нарушение доступа. На этот раз фильтр исключений не передаст память, а выведет в диалоговом окне сооб щение "Violation: Attempting to Read". Программа корректно возобновит свою работу после неудавшейся попытки чтения, очистив поле Value диалогового окна.
Третий эксперимент: попробуем считать значение из ячейки на пересечении стро ки 100 и колонки 100. Так как этой ячейке передана физическая память, никаких ис ключений не возбуждается, и фильтр не выполняется (что положительно сказывается на быстродействии программы). Диалоговое окно будет выглядеть следующим об разом.
Ну и последний эксперимент запишем значение 54321 в ячейку на пересечении строки 100 и колонки 101 Эта операция пройдет успешно, без исключений, потому что данная ячейка находится на тоЙ жс странице памяти, что и ячейка (100, 100) В подтверждение этого Вы увидите сообщение "No Violation raised" в нижней части диалогового окна




В своих проектах я довольно часто пользуюсь виртуальной памятью и SEH. Как то раз я решил создать шаблонный С++-класс CVMArray, который инкапсулирует все, что нужно для использования этих механизмов Его исходный код содержится в фай ле VMArrayh (он является частью программы-примера Spreadsheet) Вы можете рабо тать с классом CVMArray двумя способами Во-первых, просто создать экземпляр это го класса, передав конструктору максимальное число элементов массива Класс авто матически устанавливает действующий на уровне всего процесса фильтр необрабо танных исключений, чтобы любое обращение из любого потока к адресу в виртуаль ном массиве памяти заставляло фильтр вызывать VirtualAlloc (для передачи физичес кой памяти новому элементу) и возвращать EXCEPTION_CONTINUE_EXFCUTION Ta кое применение класса CVMArray позволяет работать с разреженной памятью (sparse storage), не забивая SEH-фреймами исходный код программы Единственный недоста
ток в том, что Ваше приложение не сможет возобновить корректную работу, если по каким то причинам передать память не удается
Второй способ использования CVMArray — создание производного С++-класса Производный класс даст Вам все преимущества базового класса, и, кроме того, Вы сможете расширить его функциональность — например, заменив исходную виртуаль ную функцию OnAccessViolation собственной реализацией, более аккуратно обрабаты вающей нехватку памяти Программа Spreadsheet как раз и демонстрирует этот спо соб использования класса CVMArray.
Программа-пример Summation
Эта программа, "16 Summation.exe" (см. листинг на рис. 16-6), демонстрирует использование фильтров и обработчиков исключений для корректного восстановления после переполнения стека. Файлы исходного кода и ресурсов этой программы находятся в каталоге l6-Summation на компакт-диске, прилагаемом к книге. Возможно, Вам придется сначала прочесть главы по SEH, чтобы понять, как работает эта программа. Она суммирует числа от 0 до x, где x - число, введенное пользователем. Конечно, проще было бы написать функцию с именем Sum, которая вычисляла бы по формуле:
Sum = (x * (x + 1)) / 2;
Но для этого примера я сделал функцию Sum рекурсивной, чтобы она использовала большое стековое пространство.
При запуске программы появляется диалоговое окно, показанное ниже.

В этом окне Вы вводите число и щелкаете кнопку Calculate. Программа создает поток, единственная обязанность которого - сложить все числа от 0 до x. Пока он выполняется, первичный поток программы, вызвав WaitForSingleOhject, просит систему не выделять ему процессорное время. Когда новый поток завершается, система вновь выделяет процессорное время первичному потоку. Тот выясняет сумму, получая код завершения нового потока вызовом GetExitCodeThread, и — это очень важно — закрывает свой описатель нового потока, так что система может уничтожить объект ядра "поток", и утечки ресурсов не произойдет.
Далее первичный поток проверяет код завершения суммирующего потока. Если он равен UINT_MAX, значит, произошла ошибка: суммирующий поток переполнил стек при подсчете суммы; тогда первичный поток выведет окно с соответствующим сообщением. Если же код завершения отличен от UINT_MAX, суммирующий поток отработал успешно; код завершения и есть искомая сумма. Б этом случае первичный поток просто отображает результат суммирования в диалоговом окне.
Теперь обратимся к суммирующему потоку, Его функция — SumThreadFunc. При создании этого потока первичный поток передает ему в единственном параметре pvParam количество целых чисел, которые следует просуммировать.
Затем его функция инициализирует переменную uSum значением UINT_MAX, т.e. изначально предполагается, что работа функции не завершится успехом. Далее SumThreadFunc активизирует SEH так, чтобы перехватывать любое исключение, возникающее при выполнении потока. После чего для вычисления суммы вызывается рекурсивная функция Sum.
Если сумма успешно вычислена, SumThreadFunc просто возвращает значение переменной uSum, оно и будет кодом завершения потока. Но, если при выполнении Sum возникает исключение, система сразу оценивает выражение в фильтре исключений. Иначе говоря, система вызывает FilterFunc, передавая ей код исключения. R случае переполнения стека этим кодом будет EXCEPTION_STACK_OVERFLOW. Чтобы увидеть, как программа обрабатывает исключение, вызванное переполнением стека, дайте ей просуммировать числа от 0 до 44000.
Моя функция FilterFunc очень проста. Сначала она проверяет, произошло ли исключение, связанное с переполнением стека. Если нет, возвращает EXCEPTION_CONTINUE_SEARCH, а если да — EXCEPTION_EXECUTE_HANDLER. Это подсказывает системе, что фильтр готов к обработке этого исключения и что надо выполнить код в блоке except. В данном случае обработчик исключения ничего особенного не делает, просто закрывая поток с кодом завершения UINT_MAX. Родительский поток, получив это специальное значение, выводит пользователю сообщение с предупреждением.
И последнее, что хотелось бы обсудить; почему я выделил функцию Sum в отдельный поток вместо того, чтобы просто создать SEH-фрейм в первичном потоке и вызывать Sum из его блока try. На то есть три причины.
Во-первых, всякий раз, когда создается поток, он получает стек размером 1 Мб. Если бы я вызывал Sum из первичного потока, часть стекового пространства уже была бы занята, и функция не смогла бы использовать весь объем стека. Согласен, моя программа очень проста и, может быть, не займет слишком большое стековое пространство. А если программа посложнее? Легко представить ситуацию, когда Sum подсчитывает сумму целых чисел от 0 до 1000 и стек вдруг оказывается чем-то занят, — тогда его переполнение произойдет, скажем, еще при вычислении суммы от 0 до 750.
Таким образом, работа функции Sum будет надежнее, если предоставить ей полный стек, не используемый другим кодом.
Вторая причина в том, что поток уведомляется об исключении "переполнение стека" лишь однажды. Если бы я вызывал Sum из первичного потока и произошло бы переполнение стека, то это исключение было бы перехвачено и корректно обработано. Но к тому моменту физическая память была бы передана под все зарезервированное адресное пространство стека, и в нем уже не осталось бы страниц с флагом защиты. Начни пользователь новое суммирование, и функция Sum переполнила бы стек, а соответствующее исключение не было бы возбуждено. Вместо этого возникло бы исключение "нарушение доступа", и корректно обработать эту ситуацию уже не удалось бы.
И последнее, почему я использую отдельный поток: физическую память, отведенную под его стек, можно освободить. Рассмотрим такой сценарий: пользователь просит функцию Sum вычислить сумму целых чисел от 0 до 30 000. Это требует передачи региону стека весьма ощутимого объема памяти. Затем пользователь проводит несколько операций суммирования — максимум до 5000. И окажется, что стеку передан порядочный объем памяти, который больше не используется. А ведь эта физическая память выделяется из страничною файла. Так что лучше бы освободить её и вернуть системе. И поскольку программа завершает поток SumThreadFunc, система автоматически освобождает физическую память, переданную региону стека.
Программа-пример SWMRG
Эта программа, "10_SWMRG.exe" (см. листинг на рис. 10-3), предназначена для тестирования С++-класса CSWMRG. Файлы исходного кода и ресурсов этой программы находятся в каталоге l0-SWMRG на компакт-диске, прилагаемом к книге, Я запускаю это приложение под управлением отладчика, чтобы наблюдать за всеми функциями и переменными — членами классов.
При запуске программы первичный поток создает несколько потоков, выполняющих одну и ту же функцию. Далее первичный поток вызывает WaitForMultipleObjects и ждет завершения этих потоков. Когда все они завершаются, их описатели закрываются и процесс прекращает свое существование.
Каждый вторичный поток выводит на экран такое сообщение:

Чтобы данный поток имитировал чтение ресурса, щелкните кнопку Yes, a чтобы оптимитировал запись в ресурс — кнопку No. Эти действия просто заставляют его вызвать либо функцию WaitToRead, либо функцию WaitToWrite объекта CSWMRG.
После вызова одной из этих функций поток выводит соответствующее сообщение.


Пока окно с сообщением открыто, программа приостанавливает поток и делает вид, будто он сейчас работает с ресурсом.
Конечно, если какой-то поток читает данные из ресурса и Вы командуете другому потоку записать данные в ресурс, окно с сообщением от последнего на экране не появится, так как поток-"писатель" ждет освобождения ресурса, вызвав WaitToWrite. Аналогичным образом, если Вы скомандуете потоку считать данные из ресурса в то время, как показывается окно с сообщением от потока-"писателя", первый поток будет ждать в вызове WaitToRead, и его окно не появится до тех пор, пока все потоки-"писатели" не закончат имитировать свою работу с ресурсом.
Закрыв окно с сообщением (щелчком кнопки OK), Вы заставите поток, получивший доступ к ресурсу, вызвать Done, и объект CSWMRG переключится на другие ждущие потоки.
Программа-пример SysInfo
Эта программа, "14 SysInfo.exe" (см. листинг на рис. 14-1), весьма проста; она вызывает функцию GetSystemInfo и выводит на экран информацию, возвращенную в структуре SYSTEM_INFO. Файлы исходного кода и ресурсов этой программы находятся в каталоге 14-SysInfo на компакт-диске, прилагаемом к книге. Диалоговые окна с результатами выполнения программы SysInfo на разных процессорных платформах показаны ниже.


Windows 98 на процессоре x86 и 32-разрядная Windows 2000 на процессоре x86


32-разрядная Windows2000 на процессоре А1рhа и 64 разрядная Windows 2000 на процессоре Alpha
Программа-пример TimedMsgBox
Эта программа, "11 TimedMsgBox.exe" (см листинг на рис 11-1), показывает, как пользоваться таймерными функциями пула потоков для создания окна, автоматичес ки закрываемого через заданное время в отсутствие реакции пользователя Файлы исходного кода и ресурсов этой программы находятся в каталоге 11 TimedMsgBox на компакт-диске, прилагаемом к книге
При запуске программа присваивает глобальной переменной g_nSecLeft значение 10 Этa переменная определяет, сколько времени (в секундах) программа ждет реакции пользователя на сообщение, показанное в окнс Далее вьпывается CreateTtmerQueue Timer, настраивающая пул на ежесекундный вызов MsgBoxTimeout Инициализировав все необходимые переменные, программа обращается к MessageBox и выводит окно, показанное ниже

Пока ожидается ответ от пользователя, один из потоков пула каждую секунду вы зывает функцию MsgBoxTimeout, которая находит описатель этого окна, уменьшает значение глобальнй переменной g_nSecLeft на 1 и обновляет строку в окне При пер вом вызове MsgBoxTimeout окно выглядит так

Десятый вызов MsgBoxTimeout обнуляет g_nSecLeft, и тогда MsgBoxTimeout вызыва ет EndDialog, чтобы закрыть окно После этого функция MessageBox, вызванная пер вичным потоком, возвращает управление, и вызывается DeletelimerQueueTtmer, застав ляющая пул прекратить вызовы MsgBoxTimeout В результате открывается другое окно, где сообщается о том, что никаких действий в отведенное время не предпринято

Если же пользователь успел отреагировагь на первое сообщение, на экране появ ляется то же окно, но с другим текстом

Программа-пример VMAIloc
Эта программа, "15_VMAllocexe" (см листинг на рис 15-1), демонстрирует применение механизма виртуальной памяти для управления массивом структур. Файлы исходного кода и ресурсов этой программы находятся в каталоге 15-VMAlloc на компакт диске, прилагаемом к книге После запуска VMAlloc на экране появится диалоговое окно, показано ниже.

Изначально для массива не резервируется никакого региона, и все адресное пространство, предназначенное для нею, свободно, что и отражено па карте памяти. Если щелкнуть кнопку Reserve Region (50,2KB Structures), программа VMAlloc вызовет VtrtualAlloc для резервирования региона, что сразу отразится на карте памяти. После этого сланут активными и остальные кнопки в диалоговом окне.
Теперь к поле можно ввести индекс и щелкнуть кнопку Use. При этом по адресу, где должен располагаться указанный элемент массива, передается физическая память. Долее карта памяти вновь перерисовывается и уже отражает состояние региона, за резервированного под весь массив. Когда Вы, зарезервировав регион, вновь щелкнете кнопку Use, чтобы пометить элементы 7 и 46 как занятые, окно (при выполнении программы на процессоре с размером страниц по 4 Кб) будет выглядеть так:

ЛюбоЙ элемент массива, помеченный как занятый, можно освободить щелчком кнопки Clear. Но это не приведет к возврату физической памяти, переданной под элемент массива. Дело в том, что каждая страница содержит несколько структур и освобождение одной структуры не влечет за собой освобождения других. Если бы память была возвращена, то пропали бы и данные, содержащиеся в остальных структурах. И поскольку выбор кнопки Clear никак не сказывается на физической памяти региона, карта памяти после освобождения элемента не меняется.
Однако освобождение структуры приводит к тому, что ее элемент fInUse устанавливается в FALSE. Это нужно для того, чтобы функция сбора мусора могла вернуть неиспользуемую больше физическую память. Кнопка Garbage Collect, если Вы еще не догадались, заставляет программу VMAlloc выполнить функцию сбора мусора.
Для упрощения программы я не стал выделять эту функцию в отдельный поток.
Чтобы посмотреть, как работает функция сбора мусора, очистите элемент массива с индексом 46. Заметьте, что карта памяти пока не изменилась. Теперь щелкните кнопку Garbage Collect. Программа освободит страницу, содержащую 46-й элемент, и карта памяти сразу же обновится, как показано ниже. Заметьте, что функцию Garbage Collect можно легко использовать в любых других приложениях. Я реализовал ее так, чтобы она работала с массивами структур данных любого размера; при этом структура не обязательно должна полностью умещаться на странице памяти. Единственное требование заключается в том, что первый элемент структуры должен быть значением типа BOOL, которое указывает, задействована ли данная структура.

И, наконец, хоть это и не видно на экране, закрытие окна приводит к возврату всей переданной памяти и освобождению зарезервированного региона.
Но есть в этой программе еще одна особенность, о которой я пока не упоминал. Программе приходится определять состояние памяти в адресном пространстве региона в трех случаях:
После изменения индекса. Программе нужно включить кнопку Use и отклю чить кнопку Clear (или наоборот). В функции сбора мусора. Программа, прежде чем проверять значение флага fInUse, должна определить, была ли передана память. При обновлении карты памяти. Программа должна выяснить, какие страницы свободны, какие — зарезервированы, а какие — переданы.
Все эти проверки VMAlloc осуществляет через функцию VirtualQuery, рассмотренную в предыдущей главе.
Программа-пример VMMap
Эта программа, "14_VMMap.exe" (см. листинг на рис 14-4), просматривает свое адресное пространство и показывает содержащиеся в нем регионы и блоки, присутствующие в регионах Файлы исходного кода и ресурсов этой программы находятся в каталоге 14-VMMap на компакт-диске, прилагаемом к книге. После запуска VMMap на экране появляется следующее окно:

Карты виртуальной памяти, представленные в главе 13 в таблицах 13-2, 13-3 и 13-4, созданы с помощью именно этой программы.
Каждый злемент в списке — результат вызова моей функции VMQuery. Основний цикл программы VMMap (в функции Refresb) выглядит так:
BOOL fOk = TRUE;
PVOID pvAddress = NULL;
...
while (fOk)
{
VMQUERY vmq;
fOk = VMQuery(hProcess, pvAddress, &vmq);
if (fOk)
{
// формируем строку для вывида на экран
// и добавляем ее в окно списка
TCHAR szLine[1024];
ConstructRgnInfoLine(hProcess. &vmq, szLine, sizeof(szLine});
LisTBox_AddString(hwndLB, szLine);
if (fExpandRegions)
{
for (DWORD dwBlock = 0; f0k && (dwBlock < vmq.dwRgnBlocks); dwBlock++)
{
ConstructBlkInfoLine(&vmq, szLine, sizeof(szLine));
ListBox_AddString(hwndLB, szLine);
// получаем адрес следующего региона
pvAddress = ((PBYTE) pvAddress + vmq BlkSize);
if (dwBlock < vmq dwRgnBlocks - 1)
{
// нельзя запрашивать информацию о памяти за последним блоком
fOk = VMQuery(liProcess, pvAddress, &vmq);
}
}
}
// получаем адрес следующего региона
pvAddress = ((PBYTE) vmq pvRgnBaseAddress + vmq.RgnSize);
}
}
Этот цикл начинает работу с виртуального адреса NULL и заканчивается, когда VMQuery возвращает FALSE, что указывает на невозможность дальнейшего просмотра адресного пространства процесса. На каждой итерации цикла вызывается функция ConstructRgnlnfoLine; она заполняет символьный буфер информацией о регионе. По том эти данные вносятся в список.
В основной цикл вложен еще один цикл — он позволяет получать информацию о каждом блоке текущего региона. На каждой итерации из данного цикла вызывается функция ConstructBlklnfoLine, заполняющая символьный буфер информацией о блоках региона. Эти данные тоже добавляются к списку. В общем, с помощью функции VMQuery просматривить адресное пространство процесса очень легко.
Программа-пример VMStat
Эта программа, "14_VMStat.exe" (см. листинг на рис. 14-2), выводит на экран окно с результатами вызова GlobalMemoryStatus. Информация в окне обновляется каждую секунду, так что VMStat вполне пригодна для мониторинга памяти в системе. Файлы исходного кода и ресурсов этой программы находятся в каталоге 14-VMStat на компакт-диске, прилагаемом к книге. Окно этой программы после запуска в Windows 2000 на машине с процессором Intel Pentium II и 128 Мб оперативной памяти показано ниже.

Элемент dwMemoryLoad (показываемый как Memory Load) позволяет оценить, насколько занята подсистема управления памятью. Это число может быть любым в диапазоне от 0 до 100. В Windows 98 и Windows 2000 алгоритмы, используемые для его подсчета, различны. Кроме того, в будущих версиях операционных систем этот алгоритм почти наверняка придется модифицировать. Но, честно говоря, на практике от значения этого элемента толку немного.
Элемент dwTotalPhys (показываемый как TotalPhys) отражает общий объем физической (оперативной) памяти в байтах. На данной машине с Pentium II и 128 Мб оперативной памяти его значение составляет 133 677 056, что на 540 672 байта меньше 128 Мб. Причина, по которой GlobalMemoryStatus не сообщает о полных 128 Мб, кроется в том, что система при загрузке резервирует небольшой участок оперативной памяти, недоступный даже ядру. Этот участок никогда не сбрасывается на диск. А элемент dwAvailPhys (показываемый как AvailPhys) дает число байтов свободной физической памяти.
Элемент dwTotalPageFile (показываемый как TotalPagcFile) сообщает максимальное количество байтов, которое может содержаться в страничном файле (файлах) на жестком диске (дисках). Хотя VMStat показывает, что текущий размер страничного файла составляет 318 574 592 байта, система может варьировать его по своему усмотрению. Элемент dwAvailPageFile (показываемый как AvailPageFile) подсказывает, что в данный момент 233 046 0l6 байтов в страничном файле свободно и может быть пе редано любому процессу.
Элемент dwTotalVirtual (показываемый как TotalVirtual) отражает общее количество байтов, отведенных под закрытое адресное пространство процесса.
Значение 2 147 352 576 ровно на 128 Кб меньше 2 Гб. Два раздела недоступного адресного пространства — от 0x00000000 до 0x0000FFFF и от 0x7FFF0000 до 0x7FFFFFFF — как раз и составляют эту разницу в 128 Кб. Запустив VMStat в Windows 98, Вы увидите, что значение этого элемента поменялось на 2 143 289 344 (2 Гб за вычетом 4 Мб). Разница в 4 Мб возникает из-за того, что Windows 98 блокирует нижний раздел от 0x00000000 до 0x003FFFFF (размером в 4 Мб).
И, наконец, dwAvailVirtual (показываемый как AvailVirtual) — единственный элемент структуры, специфичный для конкретного процесса, вызывающего GlobalMemoryStatus (остальные элементы относятся исключительно к самой системе и не зависят от того, какой именно процесс вызывает эту функцию). При подсчете значения dwAvaiWirtual функция суммирует размеры всех свободных регионов в адресном пространстве вызывающего процесса. В данном случае его значение говорит о том, что в распоряжении программы VMStat имеется 2 136 846 336 байтов свободного адресного пространства. Вычтя из значения dwTotalVirtual величину dwAvailVirtual, Вы получите 10 506 240 байтов — такой объем памяти VMStat зарезервировала в своем виртуальном адресном пространстве. Отдельного элемента, который сообщал бы количество физической памяти, используемой процессом в данный момент, не предусмотрено.
Программа-пример WaitForMultExp
Эта программа, "10 WaitForMultExp.exe" (см. листинг на рис. 10-4), предназначена для тестирования функции WaitForMultipleExpressions. Файлы исходного кода и ресурсов этой программы находятся в каталоге l0-WaitForMultExp на компакт-диске, прилагаемом к кпиге. После запуска WaitForMultExp открывается диалоговое окно, показанное ниже.

Если Вы нс станете изменять предлагаемые параметры, а просто щелкнете кнопку Wait For Multiple Expressions, диалоговое окно будет выглядеть так, как показано на следующей иллюстрации.
Программа создаст четыре объекта ядра "событие" в занятом состоянии и помещает в многоколоночный список (с возможностью выбора сразу нескольких элементов) по одной записи для каждого объекта ядра. Далее программа анализирует содержимое поля Expression и формирует массив описателей. По умолчанию я предлагаю объекты ядра и выражение, как в предыдущем примере.
Поскольку я задал время ожидания равным 30000 мс, у Вас есть 30 секунд на внесение изменений. Выбор элемента в нижнем списке приводит к вызову SetEvent, которая освобождает объект, а отказ от его выбора — к вызову ResetEvent и соответственно к переводу объекта в занятое состояние. После выбора достаточного числа элементов (удовлетворяющего одному из выражений) WaitForMultipleExpressions возвращает управление, и в нижней части диалогового окна показывается, какому выражению удовлетворяет Ваш выбор. Если Вы не уложитесь в 30 секунд, появится слово "Timeout".

Теперь обсудим мою функцию WaitForMultipleExpressions. Реализовать ее было не просто, и ее применение, конечно, приводит к некоторым издержкам. Как Вы знаете, в Windows есть функция WaitForMultipleObjects, которая позволяет потоку ждать по единственному AND-выражснию.
DWORD WaitForMultipleObjects( DWORD dwObjects, CONST HANDLE* pliObjects, BOOL fWaitAll, DWORD dwMimseconds);
Чтобы расширить ее функциональность для поддержки выражений, объединяемых OR, я должен создать несколько потоков — по одному на каждое такое выражение.
Каждый из этих потоков ждет в вызове WaitForMultipleObjectsEx по единственному AND-выражснию (Почему я использую эту функцию вместо более распространенной WaitForMultipleObjects - станет ясно позже). Когда какое-то выражение становится истинным, один из созданных потоков пробуждается и завершается.
Поток, который вызвал WaitForMultipleExpressions (и который породил все OR-пoтоки), должен ждать, пока одно из OR-выражений пе станет истинным. Для этого он вызывает функцию WaitForMultipleQbjeclsEx. В параметре dwObjects передается количество порожденных потоков (OR-выражений), а параметр phObjects указывает на массив описателей этих потоков. В параметр fWaitAll записывается FALSE, чтобы основной поток пробудился сразу после того, как станет истинным любое из выражений. И, наконец, в параметре dwMilliseconds передается значение, идентичное тому, которое было указано в аналогичном параметре при вызове WaitForMultipleExpressions.
Если в течение заданного времени ни одно из выражений не становится истинным, WaitForMultipleObjectsEx возвращает WAIT_TIMEOUT, и это же значение возвpaщается функцией WaitForMiltipleExpressions. А если какое-нибудь выражение становится истинным, WaitForMultipleObjectsEx возвращает индекс, указывающий, какой поток завершился. Так как каждый поток представляет отдельное выражение, этот индекс сообщает и то, какое выражение стало истинным; этот же индекс возвращается и функцией WaitForMultipleExpressions.
На этом мы, пожалуй, закончим рассмотрение того, как работает функция WaitForMultipleExpressions. Но нужно обсудить еще три вещи. Во-первых, нельзя допустить, чтобы несколько OR-потоков одновременно пробудились в своих вызовах WaitFor MultipleObjectsEx, так как успешное ожидание некоторых объектов ядра приводит к изменению их состояния (например, у семафора счетчик уменьшается на 1). WaitFor MultipleExpressions ждет лишь до тех пор, пока одно из выражений не станет истинным, а значит, я должен предотвратить более чем однократное изменение состояния объекта.
Решить эту проблему на самом деле довольно легко. Прежде чем порождать OR-потоки, я создаю собственный объект-семафор с начальным значением счетчика, равным 1. Далее каждый OR-поток вызывает WaitForMultipleObjectsEx и передает ей не только описатели объектов, связанных с выражением, но и описатель этого семафора. Теперь Вы понимаете, почему в каждом наборе не может быть более 63 описателей? Чтобы OR-поток пробудился, должны освободиться все объекты, которые он ждет, — в том числе мой специальный семафор. Поскольку начальное значение его счетчика равно 1, более одного OR-потока никогда не пробудится, и, следовательно, случайного изменения состояния каких-либо других объектов не произойдет.
Второе, на что нужно обратить внимание, - как заставить ждущий поток прекра тить ожидание для корректной очистки. Добавление семафора гарантирует, что пробудится не более чем один поток, но, раз мне уже известно, какое выражение стало истинным, я должен пробудить и остальные потоки, чтобы они корректно завершились. Вызова TerminateThread следует избегать, поэтому нужен какой-то другой механизм. Поразмыслив, я вспомнил, что потоки, ждущие в "тревожном" состоянии, принудительно пробуждаются, когда в АРС-очереди появляется какой-нибудь элемент.
Моя реализация WaitForMultipleExpressions для принудительного пробуждения по токов использует QueueUserAPC. После того как WaitForMultipleObjects, вызванная основным потоком, возвращает управление, я ставлю АРС-вызов в соответствующие очереди каждого из все еще ждущих OR-потоков:
// выводим все еще ждущие потоки из состояния сна,
// чтобы они могли корректно завершиться
for (dwExpNum = 0; dwExpNum < dwNumExps; dwExpNum++)
{
if ((WAIT_TIMEOUT == dwWaitRet) || (dwExpNum != (dwWaitRet - WAIT_OBJECT_0)))
{
QueueUserAPC(WFME_ExpressionAPC, ahThreads[dwExpNum], 0);
}
}
Функция обратного вызова, WFMEExpressionAPC, выглядит столь странно потому, что на самом деле от нее не требуется ничего, кроме одного: прервать ожидание потока.
// это АРС-функция обратного вызова
VOID WINAPI WFHE_ExpressionAPC(DWORD dwData}
{
// в тело функции преднамеренно не включено никаких операторов
}
Третье (и последнее) — правильная обработка интервалов ожидания. Если ника кие выражения так и не стали истинными в течение заданного времени, функция WaitForMultipleObjects, вызванная основным потоком, возвращает WAIT_TIMEOUT. В этом случае я должен позаботиться о том, чтобы ни одно выражение больше не ста ло бы истинным и тем самым не изменило бы состояние объектов. За это отвечает следующий код:
// ждем, когда выражение станет TRUE или когда истечет срок ожидания
dwWaitRet = WaitForMultiplcObjects(dwExpNum, ahThreads, FALSE, dwMilliseconds);
if (WAIT_TIMEOUT == dwWaitRet)
{
// срок ожидания истек, выясняем, не стало ли какое-нибудь выражение
// истинным, проверяя состояние семафора hsemOnlyOne
dwWaitRet = WaitForSingleObject(hsemOnlyOne, 0);
if (WAIT_TIMEOUT == dwWaitRet}
{
// если семафор не был переведен в свободное состояние,
// какое-то выражение дало TRUE, надо выяснить - какое
dwWaitRet = WaitForMultipleObjects(dwExpNum, ahThreads, FALSE. INFINITE);
}
else
{
// ни одно выражение не стало TRUE,
// и WaitForSingleObject просто отдала нам семафор
dwWaitRet = WAIT_TIMbOUT;
}
}
Я не даю другим выражениям стать истинными за счет ожидания на семафоре. Это приводит к уменьшению счетчика семафора до 0, и никакой OR-поток не может пробудиться. Но где-то после вызова функции WaitForMultipleObjects из основного потока и обращения той к WaitForSingleObject одно из выражений может стать истинным. Вот почему я проверяю значение, возвращаемое WaitForSingleQbject. Если она возвра щает WAIT_OBJECT_0, значит, семафор захвачен основным потоком и ни одно из выражений не стало истинным. Но если она возвращает WAIT_TIMEOUT, какое-то выражение все же стало истинным, прежде чем основной поюк успел захватить семафор. Чтобы выяснить, какое именно выражение дало TRUE, основной поток снова вызывает WaitForMultipleObjects, но уже с временем ожидания, равным INFINITE; здесь все в порядке, так как я знаю, что семафор захвачен OR-потоком и этот поток вот-вот завершится.
Теперь я должен пробудить остальные OR-потоки, чтобы корректно завершить их. Это делается в цикле, из которого вызывается QueueUserAPC (о ней я уже рассказывал).
Поскольку реализация WaitForMultipleExpressions основана на использовании группы потоков, каждый из которых ждет на своем наборе объектов, объединяемых по AND, мьютексы в ней неприменимы. В отличие от остальных объектов ядра мьютексы могут передаваться потоку во владение. Значит, если какой-нибудь из моих AND потоков заполучит мьютекс, то по его завершении произойдет отказ от мьютекса. Вот когда Microsoft добавит в Windows API функцию, позволяющую одному потоку передавать права на владение мьютексом другому потоку, тогда моя функция WaitForMultipleExpressions и сможет поддерживать мьютексы. А пока надежного и корректного способа ввести в WaitForMultipleExpressions такую поддержку я не вижу.
Программирование приоритетов
Так как же процесс получает класс приоритета? Очень просто Вызывая CreateProcess, Вы можете указать в ее параметр fdwCreate нужный класс приоритета. Идентифика торы этих классов приведены в следующей таблице.
| Класс приоритета | Идентификатор | ||
| Real-time | RFALTIME_PRIORITY_CLASS | ||
|
High | HIGH_PRIORITY_CLASS | ||
| Above normal | ABOVE_NORMAL_PRIORITY_CLASS | ||
| Normal | NORMAL_PRIORITY_CLASS | ||
| Below normal | BELOW_NORMAL_PRIORITY_CLASS | ||
| Idle | IDLE_PRIORITY_CLASS |
Вам может показаться странным, что, создавая дочерний процесс, родительский сам устанавливает ему класс приоритета. За примером далеко ходить не надо — возь мем все тот же Explorcr При запуске из него какого-нибудь приложения новый про цесс создается с обычным приоритетом Но Explorer ведь не знает, что делает этот процесс и как часто его потокам надо выделять процессорное время. Поэтому в сис теме предусмотрена возможность изменения класса приоритета самим выполняемым процессом — вызовом функции SetPriontyClass-
BOOL SetPriontyClass( HANDLE hProcess, DWORD fdwPriority);
Эта функция меняет класс приоритета процесса, определяемого описателем hPro cess, в соответствии со значением параметра fdwPriority. Последний должен содержать одно из значений, указанных в таблице выше. Поскольку SetPriorityClass принимает описатель процесса, Вы можете изменить приоритет любого процесса, выполняемо го в системе, — если его описатель известен и у Вас есть соответствующие права дос тупа.
Обычно процесс пытается изменить свой класс приоритета. Вот как процесс может сам себе установить класс приоритета idle:
BOOL SetPriorityClass(GetCurrentProcess(), IDLE_PRIORITY_CLASS);
Парная ей функция GetPriorityClass позволяет узнать класс приоритета любого процесса.
DWORD GetPriorityClass(HANDLE hProcess);
Она возвращает, как Вы догадываетесь, один из ранее перечисленных флагов.
При запуске из оболочки командного процессора начальный приоритет програм мы тоже обычный. Однако, запуская ее командой Start, можно указать ключ, опреде ляющий начальный приоритет Так, следующая команда, введенная в оболочке коман дного процессора, заставит систему запустить приложение Calculator и присвоить ему приоритет idle:
C:\>START /LOW CALC.EXE
Команда Start допускает также ключи /BELOWNORMAL, /NORMAL, /ABOVENORMAL, /HIGH и /REALTIME, позволяющие начать выполнение программы с соответствующим классом приоритета. Разумеется, после запуска программа может вызвать SetPriorrty Class и установить себе другой класс приоритета.
WINDOWS 98
В Windows 98 команда Start не поддерживает ни один из этих ключей. Из обо лочки командного процессора Windows 98 процессы всегда запускаются с классом приоритета normal.
Task Manager в Windows 2000 дает возможность изменять класс приоритета про цесса. На рисунке ниже показана вкладка Processes в окне Task Manager co списком выполняемых на данный момент процессов. В колонке Base Pri сообщается класс приоритета каждого процесся Вы можете изменить его, выбрав процесс и указав другой класс в подменю Set Priority контексшого меню.

Только что созданный поток получает относительный приоритет normal Почему CreateThoread не позволяет задать относительный приоритет — для меня так и остает ся загадкой. Такая операция осуществляется вызовом функции:
BOOL SetThreadPriority( HANDLE hThread, int nPriority);
Разумеется, параметр bThread указывает на поток, чей приоритет Вы хотите из менить, а через nPriority передается один из идентификаторов (см. таблицу ниже)
| Относительный приоритет потока | Идентификатор |
| Time-critical | THREAD_PRIORITY_TIME_CRITICAL |
| Highest | THREAD_PRIORITY_HIGHEST |
| Above normal | THREAD_PRIORITY_ABOVE_NORMAL |
| Normal | THREAD_PRIORITY_NORMAL |
| Below normal | THREAD_PRIORITY_BELOW_NORMAL |
| Lowest | THREAD_PRIORITY_LOWEST |
| Idle | THREAU_PRIORITY_IDLE |
int GetThreadPriority(HANDLE hThread);
Она возвращает один из идентификаторов, показанных в таблице выше.
Чтобы создать поток с относительным приоритетом idle, сделайте, например, так:
DWORD dwThreadID;
HANDLE hThread = CreateThread(NULL, 0, ThreadFunc, NULL, CREATE_SUSPENDED, &dwThreadID); SetThreadPriority(hThread, THREAD_PRIORITY_IDLE); ResumeThread(hThread); CloseHandle(hThread);
Заметьте, что CreateThread всегда создает поток с относительным приоритетом normal. Чтобы присвоить потоку относительный приоритет idle, создайте приоста новленный поток, передав в CreateThread флаг CREATE_SUSPENDED, а потом вызови те SetThreadPriority и установите нужный приоритет. Далее можно вызвать Resume Thread, и поток будет включен в число планируемых. Сказать заранее, когда поток получит процессорное время, нельзя, но планировщик уже учитывает его новый при оритет Выполнив эти операции, Вы можете закрыть описатель потока, чтобы соот ветствующий объект ядра был уничтожен по завершении данного потока.
NOTE:
Ни одна Windows-функция не возвращает уровень приоритета потока. Такая ситуация создана преднамеренно. Вспомните, что Microsoft может в любой момент изменить алгоритм распределения процессорного времени. Поэтому при разработке приложений не стоит опираться на какие-то нюансы этого алгоритма. Используйте классы приоритетов процессов и относительные при оритеты потоков, и Ваши приложения будут нормально работать как в нынеш них, так и в следующих версиях Windows
Программные исключения
До сих пор мы рассматривали обработку аппаратных исключений, когда процессор перехватывает некое событие и возбуждает исключение. Но Вы можете и сами гене рировать исключения. Это еще один способ для функции сообщить о неудаче выз вавшему ее коду, Традиционно функции, которые могут закончиться неудачно, воз вращают некое особое значение — признак ошибки. При этом предполагается, что код, вызвавший функцию, проверяет, не вернула ли она это особое значение, и, если да, выполняет какие-то альтернативные операции. Как правило, вызывающая функция проводит в таких случаях соответствующую очистку и в свою очередь тоже возвра щает код ошибки. Подобная передача кодов ошибок по цепочке вызовов резко услож няет написание и сопровождение кода.
Альтернативный подход заключается в том, что при неудачном вызове функции возбуждают исключения. Тогда написание и сопровождение кода становится гораздо проще, а программы работают намного быстрее. Последнее связано с тем, что та часть кода, которая отвечает за контроль ошибок, вступает в действие лишь при сбоях, т. e. в исключительных ситуациях.
К сожалению, большинство разработчиков не привыкло пользоваться исключени ями для обработки ошибок. На то есть двс причины Во-первых, многие просто не знакомы с SEH. Если один разработчик создаст функцию, которая генерирует исклю чение, а другой не сумеет написать SEH-фрейм для перехвата этого исключения, его приложение при неудачном вызове функции будет завершено операционной системой
Вторая причина, по которой разработчики избегают пользоваться SEH, — невоз можность его переноса на другие операционные системы. Ведь компании нередко выпускают программные продукты, рассчитанные на несколько операционных сис тем, и, естественно, предпочитают работать с одной базой исходного кода для каж дого продукта. А структурная обработка исключений — это технология, специфич ная для Windows.
Если Вы все же решились на уведомление об ошибках через исключения, я аппло дирую этому решению и пишу этот раздел специально для Вас.
Давайте для начала посмотрим на семейство Неар-функции (HeapCreate, НеарАllос и т. д.). Наверное, Вы помните из главы 18, что они предлагают разработчику возможность выбора. Обыч но, когда их вызовы заканчиваются неудачно, они возвращают NULL, сообщая об ошибке. Но Вы можете передать флаг HEAP_GENERATE_EXCEPTIONS, и тогда при не удачном вызове Неар-функция не станет возвращать NULL; вместо этого она возбу дит программное исключение STATUS_NO_MEMORY, перехватываемое с помощью SEH-фрейма.
Чтобы использовать это исключение, напишите код блока try так, будто выделе ние памяти всегда будет успешным; затем — в случае ошибки при выполнении дан ной операции Вы сможете либо обработать исключение в блоке except, либо зас тавить функцию провести очистку, дополнив блок try блоком finally. Очень удобно!
Программные исключения перехватываются точно так же, как и аппаратные, Ина че говоря, все, что я рассказывал об аппаратных исключениях, в полной мере отно сится и к программным исключениям.
В этом разделе основное внимание мы уделим тому, как возбуждать программные исключения в функциях при неудачных вызовах. В сущности, Вы можете реализовать свои функции по аналогии с Heap-функциями: пусть вызывающий их код передаст специальный флаг, который сообщает функциям способ уведомления об ошибках.
Возбудить программное исключение несложно — достаточно вызвать функцию RaiseException:
VOTD RaiseException( OWORD dwExceptionCode, DWORD dwExceptionFlags, DWORD nNumberOfArguments, CONST ULONG_PTR *pArguments);
Ее первый параметр, dwExceptionCode, — значение, которое идентифицирует ге нерируемое исключение. HeapAlloc передает в нем STATUS_NO_MEMORY. Если Вы определяете собственные идентификаторы исключений, придерживайтесь формата, применяемого для стандартных кодов ошибок в Windows (файл WinError.h) Не забудь те, что каждый такой код представляет собой значение типа DWORD, его поля описа ны в таблице 24-1. Определяя собственные коды исключений, заполните все пять его полей
биты 31 и 30 должны содержать код степени "тяжести";
бит 29 устанавливается в 1 ( 0 зарезервирован для исключений, определяемых Microsoft, вроде STATUS_NO_MEMORY для HeapAlloc);
бит 28 должен быть равен 0;
биты 27-l6 должны указывать один из кодов подсистемы, предопределенных Microsoft;
биты 15-0 Moгут содержать произвольное значение, идентифицирующее ту часть Вашего приложения, которая возбуждает исключение.
Второй параметр функции RaiseException — dwExceptionFlags — должен быть либо 0, либо EXCEPTION_NONCONTINUABLE. В принципе этот флаг указывает, может ли фильтр исключений вернуть EXCEPTION_CONTINUE_EXECUTION в ответ на дан ное исключение. Если Вы передаете в этом параметре нулевое значение, фильтр мо жет вернуть EXCEPTION_CONTlNTJE_EXECUTION В нормальной ситуации это заста вило бы поток снова выполнить машинную команду, вызвавшую программное исклю чение Однако Microsoft пошла на некоторые ухищрения, и поток возобновляет вы полнение с оператора, следующего за вызовом RaiseExcepiton
Но, передав функции RaiseException флаг EXCEPTION_NONCONTINUABLE, Вы со общаете системе, что возобновить выполнение после данного исключения нельзя. Операционная система использует этот флаг, сигнализируя о критических (фаталь ных) ошибках. Например, HeapAlloc устанавливает этот флаг при возбуждении про граммного исключения STATUS_NO_MEMORY, чтобы указать системе: выполнение продолжить нельзя Ведь если вся память занята, выделить в нсй новый блок и про должить выполнение программы не удастся.
Если возбуждается исключение EXCEPTION_NONCONTINUABLE, а фильтр все же возвращает EXCEPTION_CONTINUE EXECUTION, система генерирует новое исключе ние EXCEPTION_NONCONTINUABLE_EXCEPTION.
При обработке программой одного исключения вполне вероятно возбуждение нового исключения И смысл в этом есть. Раз уж мы остановились на этом месте, за мечу, что нарушение доступа к памяти возможно и в блоке finally, и в фильтре исклю чений, и в обработчике исключений. Когда происхидит нечто подобное, система со здает список исключений. Помните функцию GetExceptionlnformation? Она возвращает адрес структуры EXCEPTION_POINTERS Ее элемент ExceptionRecord указывает на струк туру EXCEPTION_RECORD, которая в свою очередь тоже содержит элемент Exception-
Record. Он указывает на другую структуру EXCEPTION_RECORD, где содержится ин формация о предыдущем исключении.
Обычно система единовременно обрабатывает только одно исключение, и эле мент ExceptionRecord равен NULL. Ho если исключение возбуждается при обработке другого исключения, то в первую структуру EXCEPTION_RECORD помещается инфор мация о последнем исключении, а ее элемент ExecptionRecord указывает на аналогич ную структуру с аналогичными данными о предыдущем исключении. Если есть и дру гие необработанные исключения, можно продолжить просмотр этого связанного списка структур EXCEPTION_RECORD, чтобы определить, как обработать конкретное исключение.
Третий и четвертый параметры (nNumberOfArguments и pArguments) функции Raise Exception позволяют передать дополнительные данные о генерируемом исключении Обычно это не нужно, и pArguments передается NULL; тогда RaiseException игнори рует параметр nNumberOfArguments. А если Вы передаете дополнительные аргументы, nNumberOfArguments должен содержать число элементов в массиве типа ULONGPTR, на который указываетр pArguments. Значение nNumberOfArguments не может быть боль ше EXCEPTION_MAXIMUM_PARAMETERS (в файле WinNT.h этот идентификатор опре делен равным 15).
При обработке исключения написанный Вами фильтр — чтобы узнать значения nNumberOfArguments и pArguments — может ссылаться на элементы NumberParameters и Exceptionlnformation структуры EXCEPTION_RECORD
Собственные программные исключения генерируют в приложениях по целому ряду причин. Например, чтобы посылать информационные сообщения в системный журнал событий. Как только какая-нибудь функция в Вашей программе столкнется с той или иной проблемой, Вы можете вызвать RaiseException; при этом обработчик исключений следует разместить выше по дереву вызовов, тогда — в зависимости от типа исключения — он будет либо заносить его в журнал событий, либо сообщать о нем пользователю. Вполне допустимо возбуждать программные исключения и для уведомления о внутренних фатальных ошибках в приложении.
Проверьте себя: FuncaDoodleDoo
Посмотрим, отгадаете ли Вы, что именно возвращает следующая функция
DWORD FuncaDoodleDoo()
{
DWORD dwTerrip = 0;
while (dwTemp < 19)
{
__try
{
if (dwTemp == 2) continue;
if (dwTemp == 3) break;
}
__finally { dwTernp++; }
dwTemp++;
}
dwTemp += 10;
return(dwTemp);
}
Проанализируем эту функцию шаг за шагом. Сначала dwTemp приравнивается 0. Код в блоке try выполняется, но ни одно из условий в операторах if не дает TRUE, и поток управления естественным образом переходит в блок finаllу, где dwTemp увели чивается до 1. Затем инструкция после блока finаllу снова увеличивает значение dwTemp, приравнивая его 2.
На следующей итерации цикла dwTemp равно 2, поэтому выполняется оператор continue в блоке try, Без обработчика завершения, вызывающего принудительное вы полнение блока finаllу перед выходом из try, управление было бы передано непосред ственно в начало цикла while, значение dwTemp больше бы не менялось — и мы в бесконечном цикле! В присутствии же обработчика завершения система обнаружи вает, что оператор continue приводит к преждевременному выходу из try, и передает управление блок finаllу. Значение dwTemp в нем увеличивается до 3, но код за этим
блоком не выполняется, так как управление снова передается оператору continue, и мы вновь в начале цикла.
Теперь обрабатываем третий проход цикла. На этот раз значение выражения в первом if равно FALSE, а во втором — TRUE. Система снова перехватывает нашу по пытку прервать выполнение блока try и обращается к коду finаllу. Значение dwTemp увеличивается до 4. Так как выполнен оператор break, выполнение возобновляется после тела цикла. Поэтому код, расположенный за блоком finаllу (но в теле цикла), не выполняется. Код, расположенный за телом цикла, добавляет 10 к значению dwTemp, что дает в итоге 14, — это и есть результат вызова функции. Даже не стану убеж дать Вас никогда не писать такой код, как в FuncaDoodleDoo. Я-то включил continue и break в середину кода, только чтобы продемонстрировать поведение обработчика завершения.
Хотя обработчик завершения справляется с большинством ситуаций, в которых выход из блока try был бы преждевременным, он не может вызвать выполнение бло ка finally при завершении потока или процесса. Вызов ExitThread или ExitProcess сра зу завершит поток или процесс — без выполнения какого-либо кода в блоке finаllу. То же самое будет, если Ваш поток или процесс погибнут из-за того, что некая програм ма вызвала TerminateThread или TerminateProcess. Некоторые функции библиотеки С (вроде abort). в свою очередь вызывающие ExitProcess, тоже исключают выполнение блока finаllу. Раз Вы не можете запретитьдругой программе завершение какого-либо из своих потоков, или процессов, так хоть сами не делайте преждевременных вызо вов ExitThread и ExitProcess.
Работа с волокнами
Во-первых, потоки в Windows реализуются на уровне ядра операционной системы, которое отлично осведомлено об их существовании и "коммутирует" их в соответствии с созданным Microsoft алгоритмом В то же время волокня реализованы на уровне кода пользовательского режима, ядро ничего не знает о них, и процессорное время распределяется между волокнами по алгоритму, определяемому Вами. А раз так, то о вытеснении волокон говорить не приходится — по крайней мере, когда дело касается ядра
Второе, о чем следует помнить, — в потоке может быть одно или несколько воло кон. Для ядра поток — все то, что можно вытеснить и что выполняет код. Единовременно поток будет выполнять код лишь одного волокна — какого, решать Вам (соответствующие концепции я поясню позже).
Приступая к работе с волокнами, прежде всего преобразуйте существующий по ток в волокно. Это делает функция ConvertThreadToFiber
PVOID ConvertThreadToFiber(PVOID pvParam);
Она создает в памяти контекст волокна (размером около 200 байтов). В него входят следующие элементы:
определенное программистом значение; оно получает значение параметра pvParam, передаваемого в ConvertThreadToFiber,
заголовок цепочки структурной обработки исключений,
начальный и конечный адреса стека волокна; при преобразовании потока в волокно он служит и стеким потока;
В регистры процессора, включая указатели стека и команд.
Создав и инициализировав контекст волокна, Вы сопоставляете его адрес с потоком, преобразованным в волокно, и теперь оно выполняется в этом потоке Convert ThreadToFiber возвращает адрес, по которому расположен контекст волокна. Этот ад pcc сщe понадобится Вам, но ни считывать, ни записывать по нему напрямую ни в коем случае нельзя — с содержимым этой структуры работают только функции, уп равляющие волокнами При вызове ExitThread завершаются и волокно, и поток
Нет смысла преобразовывать поток в волокно, если Вы не собираетесь создавать дополнительные волокна в том же потоке Чтобы создать другое волокно, поток (вы полняющий в данный момент волокно), вызывает функцию CreateFiber:
PVOID CreateFiber( DWORD dwStackSize, PFIBER_START_ROUTINE pfnStartArtrtress, PVOID pvParam);
Сначала она пытается создать новый стек, размер которого задан в параметре dwStackSize. Обычно передают 0, и тогда максимальный размер стека ограничивается 1 Мб, а изначально ему передается две страницы памяти. Если Вы укажете ненулевое значение, то для стека будет зарезервирован и передан именно такой объем памяти.
Создав стек, CrealeFiber формирует новую структуру контекста волокна и инициализирует ее. При этом первый ее элемент получает значение, переданное функции как параметр pvParam, сохраняются начальный и конечный адреса стека, а также адрес функции волокна (переданный как аргумет pfnStartAddress)
У функции волокна, реализуемой Вами, должен бьпь такой прототип;
VOID WINAPI FiberFunc(PVOID pvParam);
Она выполняется, когда волокно впервые получает управление В качестве параметра ей передается значение, изначально переданное как аргумент pvParam функции CreateFtber Внутри функции волокна можно делать что угодно. Обратите внима ние на тип возвращаемого значения — VOID Причина не в том, что это значение несущественно, а в том, чго функция никогда не возвращает управление! А иначе поток и все созданные внутри него волокна были бы тут же уничтожены.
Как и ConvertThreadToFiber, CreateFiber возвращает адрес контекста волокна, но с тем отличием, что новое волокно начинает работать не сразу, поскольку продолжается выполнение текущего. Единовременно поток может выполнять лишь одно волокно. И, чтобы новое волокно стало работать, надо вызвать SwitchToFiber
VOID SwitchToFiber(PVOID pvFiberExeculionContext);
Эта функция принимает единственный параметр (pvFiberExecutionContext) — адрес контекста волокна, полученный в предшествующем вызове ConvertThreadToFiber или CreateFiber По этому адресу она определяет, какому волокну предоставить про цессорное время SwitchToFiber осуществляет такие операции
Сохраняет в контексте выполняемого в данный момент волокна ряд текущих регистров процессора, включая указатели команд и стека
Загружает в регистры процессора значения, ранее сохраненные в контексте волокна, подлежащею выполнению В их число входит указатель стска, и по этому при переключении на другое волокно используется именно его стек
Связывает контекст волокна с потоком, и тот выполняет указанное волокно
Восстанавливает указатель команд Поток (волокно) продолжает выполнение с того места, на каком волокно было прервано в последний раз
Применение SwitchToFiber — единственный способ выделить волокну процессорное время Поскольку Ваш код должен явно вызывать эту функцию в нужные моменты, Вы полностью управляете распределением процессорного времени для волокон. Помните такой вид планирования не имеет ничего общего с планированием потоков Поток, в рамках которого выполняются волокна, всегда может быть вытеснен операционной системой Когда поток получает процессорное время, выполняется только выбранное волокно, и никакое другое не получит управление, пока Вы сами не вызовете SwitchToFiber
Для уничтожения волокна предназначена функция DeleteFiber
VOID DeleteFiber(PVOID pvFiberExecutionContext);
Она удаляет волокно, чей адрес контекста определяется параметром pvFtberExecu tionContext, освобождает память, занятую стеком волокна, и уничтожает его контекст Но, если Вы передаете адрес волокна, связанного в данный момент с потоком, Delete Fiber сама вызывает ExitThread — в результате поток и все созданные в нем волокна "погибают"
DeleteFiber обычно вызывается волокном, чтобы удалить другое волокно Стек уда ляемого волокна уничтожается, а его контекст освобождается И здесь обратите вни мание на разницу между волокнами и потоками потоки, как правило, уничтожают себя сами, обращаясь к ExitThread Использование с этой целью TerminateThread счи тается плохим тоном — ведь тогда система не уничтожает стек потока Так вот, спо собность волокна корректно уничтожать другие волокна нам еще пригодится — как именно, я расскажу, когда мы дойдем до программы-примера
Для удобства предусмотрено еще две функции, управляющие волокнами В каж дый момент потоком выполняется лишь одно волокно, и операционная система все гда знает, какое волокно связано сейчас с потоком Чтобы получить адрес контекста текущего волокна, вызовите GetCurrentFiber
PVOID GetCurrentFiber();
Другая полезная функция — GetFiberData
PVOID GetFiberData();
Как я уже говорил, контекст каждого волокна содержит определяемое програм мистом значение Оно инициализируется знячением параметра pvParam, передавае мого функции ConvertThreadToFiber или CreateFiber, и служит аргументом функции во локна GetFtberData просто "заглядывает" в контекст текущего волокна и возвращает хранящееся там значение
Обе функции — GetCurrentFiber и GetFiberData — работают очень быстро и обыч но реализуются компилятором как встраиваемые (т e. вместо вызовов этих функций он подставляет их код)
Раздел для кода и данных пользовательского режима (Windows 2000 и Windows 98)
В этом разделе располагается закрытая (неразделяемая) часть адресного пространства процесса. Ни один процесс не может получить доступ к данным другого процесса, размещенным в этом разделе. Основной объем данных, принадлежащих процессу, хранится именно здесь (это касается всех приложений) Поэтому приложения менее зависимы от взаимных "капризов", и вся система функционирует устойчивее
WINDOWS2000
В Windows 2000 сюда загружаются все EXE- и DLL-модули В каждом процессе эти DLL можно загружать по разным адресам в пределах данного раздела, но так делается крайне редко. На этот же раздел отображаются все проецируемые в память файлы, доступные данному процессу
WINDOWS 98
В Windows 98 основные 32-разрядные системные DLL (Kernel32.dll, AdvAPI32.dll, User32.dll и GDI32.dll) загружаются в раздел для общих MMF (проецируемых в память файлов), a EXE- и остальные DLL-модули — в раздел для кода и данных пользовательского режима. Общие DLL располагаются по одному и тому же виртуальному адресу во всех процессах, но другие DLL могут загружать их (общие DLL) по разным адресам в границах раздела для кода и данных пользовательского режима (хотя это маловероятно). Проецируемые в память файлы в этот раздел никогда не помещаются
Впервые увидев адресное пространство своего 32-разрядного процесса, я был удивлен тем, что его полезный объем чуть ли не вдвое меньше. Неужели раздел для кода и данных режима ядра должен занимать столько места? Оказывается — да .Это пространство нужно системе для кода ядра, драйверов устройств, кэш-буферов ввода-вывода, областей памяти, не сбрасываемых в файл подкачки, таблиц, используемых для контроля страниц памяти в процессе и т д По сути, Microsoft едва-едва втиснула ядро в эти виртуальные два гигабайта. В 64-разрядной Windows 2000 ядро наконец получит то пространство, которое ему нужно на самом деле.
Увеличение раздела для кода и данных пользовательского режима до 3 Гб на процессорах x86 (только Windows 2000)
Многие разработчики уже давно сетовали на нехватку адресного пространства для пользовательского режима.
Microsoft пошла навстречу и предусмотрела в версиях Windows 2000 Advanced Server и Windows 2000 Data Center для процессоров x86 возможность увеличения этого пространства до 3 Гб. Чтобы все процессы использовали раздел для кода и данных пользовательского режима размером 3 Гб, а раздел для кода и данных режима ядра — объемом 1 Гб, Вы должны добавить ключ /3GB к нужной записи в системном файле Boot.ini. Как выглядит адресное пространство процесса в этом случае, показано в графе "32-разрядная Windows 2000 (на x86 с ключом /3GB)" таблицы 13-1.
Раньше, когда такого ключа не было, программа не видела адресов памяти по указателю с установленным старшим битом. Некоторые изобретательные разработчики самостоятельно использовали этот бит как фляг, который имел смысл только в их приложениях. При обращении программы no адресам за пределами 2 Гб предварительно выполнялся специальный код, который сбрасывал старший бит указателя Но, как Вы понимаете, когда приложение на свой страх и риск создает себе трехгигабайтовую среду пользовательского режима, оно может с треском рухнуть.
Microsoft пришлось придумать решение, которое позволило бы подобным приложениям работать в трехгигабайтовой среде Теперь система в момент запуска приложения проверяет, не скомпоновано ли оно с ключом /LARGEADDRESSAWARE. Если да, приложение как бы заявляет, что обязуется корректно обращаться с этими адресами памяти и действительно готово к использованию трехгигабайтового адресного пространства пользовательского режима. А если пет, операционная система резервирует область памяти размером 1 Гб в диапазоне адресов от 0x80000000 до 0xBFFFFFFF. Это предотвращает выделение памяти по адресам с установленным старшим битом.
Заметьте, что ядро и так с трудом умещается в двухгигабайтовом разделе. Но при использовании ключа /3GB ядру остается Bceго 1 Гб. Тем самым уменьшается количество потоков, стеков и других ресурсов, которые система могла бы предоставить приложению. Кроме того, система в этом случае способна задействовать максимум 16 Гб оперативной памяти против 64 Гб в нормальных условиях — из-за нехватки виртуального адресного пространства для кода и данных режима ядра, необходимого для управления дополнительной оперативной памятью
NOTE:
Флаг LARGEADDRESSAWARE в исполняемом файле проверяется в тот момент, когда операционная система создает адресное пространство процесса. Для DLL этот флаг игнорируется При написании DLL Вы должны сами позаботиться об их корректном поведении в трехгигабайтовом разделе пользовательского режима18}
Уменьшение раздела для кода и данных пользовательского режима до 2 Гб в 64-разрядной Windows 2000
Microsoft понимает, что многие разработчики захотят как можно быстрее перенести свои 32-разрндные приложения в 64-разрядную среду Но в исходном кодс любых программ полно таких мест, где предполагается, что указатели являются 32-разрядными значениями Простая перекомпиляция исходного кода приведет к ошибочному усечению указателей и некорректному обращению к памяти
Однако, если бы система как-то гарантировала, что память никогда не будет выделяться по адресам выше 0x00000000 7FFFFFFF, приложение работало бы нормально. И усечение 64-разрядного адреса до 32-разрядного, когда старшие 33 бита равны 0, не создало бы никаких проблем. Так вот, система дает такую гарантию при запуске приложения в "адресной песочнице" (address space sandbox), которая ограничивает полезное адресное пространство процесса до нижних 2 Гб
По умолчанию, когда Вы запускаете 64-разрядное приложение, система резервирует все адресное пространство пользовательского режима, начиная с 0x0000000 80000000, что обеспечивает выделение памяти исключительно в нижних 2 Гб 64-разрядного адресного пространства. Это и есть "адресная песочница". Большинству приложений этого пространства более чем достаточно. А чтобы 64-разрядное приложение могло адресоваться ко всему разделу пользовательского режима (объемом 4 Тб), его следует скомпоновать с ключом /LARGEADDRESSAWARE.
NOTE:
Флаг LARGEADDRESSAWARE в исполняемом файле проверяется в тот момент, когда операционная система создает адресное пространство 64-разрядного процесса Для DLL этот флаг игнорируется. При написании DLL Вы должны сами позаботиться об их корректном поведении в четырехтерабайтовом разделе пользовательского режима.
Раздел для кода и данных режима ядра (Windows 2000 и Windows 98)
В этот раздел помещается код операционной системы, в том числе драйверы устройств и код низкоуровневого управления потоками, памятью, файловой системой, сетевой поддержкой. Все, что находится здесь, доступно любому процессу. В Windows 2000 эти компоненты полностью защищены Поток, который попытается обратиться по одному из адресов памяти в этом разделе, вызовет нарушение доступа, а это приведет к тому, что система в конечном счете просто закроет его приложение. (Подробнее на эту тему см. главы 23, 24 и 25.)
WINDOWS2000
В 64-разрядной Wmclows 2000 раздел пользовательского режима (4 Тб) выглядит непропорционально малым по сравнению с 16 777 212 Тб, отведенными под раздел для кода и данных режима ядра Дело не в том, что ядру так уж необходимо все это виртуальное пространство, a просто 64-разрядное адресное пространство настолько огромно, что его большая часть не задействована Система разрешает нашим программам использовать 4 Тб, а ядру — столько, сколько ему нужно. К счастью, какие-либо внутренние структуры данных для управления незадействованными частями раздела для кода и данных режима ядра не требуются.
WINDOWS98
В Windows 98 данные, размещенные в этом разделе, увы, не защищены — любое приложение может что-то считать или записать в нем и нарушить нормальную работу операционной системы.
Раздел для общих MMF (только Windows 98)
В этом разделе размером 1 Гб система хранитданные, разделяемые всеми 32-разрядными процессами. Сюда, например, загружаются все системные DLL (Kernel32.dll, | AdvAPI32 dll, User32.dll и GDI32 dll), и поэтому они доступны любому 32-разрядному I процессу Кроме того, эти DI.I. загружаются в каждом процессе по одному и тому же I адресу памяти. На этот раздел система также отображает все проецируемые в память я файлы. Об этих файлах мы поговорим в главе 17
Раздел для выявления нулевых указателей (Windows 2000 и Windows 98)
Этот раздел адресного пространства резервируется для того, чтобы программисты могли выявлять нулевые указатели. Любая попытка чтения или записи в память по этим адресам вызывает нарушение доступа.
Довольно часто в программах, написанных на С/С++, отсутствует скрупулезная обработки ошибок. Например, в следующем фрагменте кода такой обработки вообще нет:
int* pnSomeInteger = (int*) malloc(sizeof(int));
*pnSomeInteger = 5;
При нехватке памяти malloc вернет NULL. Ho код не учитывает эту возможность и при ошибке обратится к памяти по адресу 0x00000000 А поскольку этот раздел адресного пространства заблокирован, возникнет нарушение доступа и данный процесс завершится Эта особенность помогает программистам находить "жучков* в своих приложениях.
Реализация функции WaitForMultipleExpressions
Некогорое время назад я разрабатывал одно приложение и столкнулся с весьма не простым случаем синхронизации потоков. Функции WaitForMultipleObjects, заставляющей поток ждать освобождения одного или всех объектов, оказалось недостаточно. Мне понадобилась функция, которая позволяла бы задавать более сложные критерии ожидания. У меня было три объекта ядра процесс, семафор и событие. Мой поток должен был ждать до тех пор, пока не освободится либо процесс и семафор, либо процесс и событие.
Слегка поразмыслив и творчески использовав имеющиеся функции Windows, я создал именно то, что мне требовалось, — функцию WaitWorMulttpleExpressions. Ее прототип выглядит так:
DWORD WINAPI WaitForMultipleExpressions( DWORD nExpObjectS, CONST HANDLE* phExpObiects, DWORD dwMilliseconds);
Перед ее вызовом Вы должны создать массив описателей (HANDLE) и инициализировать всt cro элементы. Параметр nExpObjects сообщает число элементов в массиве, на который указывает параметр phExpObjects. Этот массив содержит несколько наборов описателей объектов ядра; при этом каждый набор отделяется элементом, равным NULL. Функция WaitForMultipleExpressions считает все объекты в одном наборе объединяемыми логической операцией AND, а сами наборы — объединяемыми логической операцией OR. Поэтому WaitForMultipleExpressions приостанавливает вызы вающий поток до тех пор, пока не освободятся сразу все объекты в одном из наборов.
Вот пример. Допустим, мы работаем с четырьмя объектами ядра (см. таблицу ниже).
| Обьект ядра | Значение описателя | ||
|
Поток | 0x1111 | ||
| Семафор | 0x2222 | ||
| Событие | 0x3333 | ||
| Процесс | 0x4444 |
Инициализировав массив описателей, как показано в следующей таблице, мы со общаем функции WaitForMultipleExpressions приостановить вызывающий поток до тех пор, пока не освободятся поток AND семафор OR семафор AND событие AND про цесс OR поток AND процесс,
| Индекс | Значение описателя | Набор | |||
| 0 | 0x1111 (поток) | 0 | |||
| 1 | 0x2222 (семафор) | ||||
| 2 | 0x0000 (OR) | ||||
| 3 | 0x2222 (семафор) | 1 | |||
| 4 | 0x3333 (событие) | ||||
| 5 | 0x4444 (процесс) | ||||
| 6 | 0x0000 (OR) | ||||
| 7 | 0x1 1 1 1 (поток) | 2 | |||
| 8 | 0x4444 (процесс) |
Вы, наверное, помните, что функции WaitForMultipleObjects нельзя передать массив описателей, число элементов в котором превышает 64 (MAXIMUM_WAIT_OBJECTS). Так вот, при использовании WaitForMultipleExpressions массив описателей может быть го раздо больше. Однако у Вас не должно быть более 64 выражений, а в каждом — более 63 описателей. Кроме того, WaitForMulttpleExpresstons будет работать некорректно, если Вы передадите ей хотя бы один описатель мыотекса. (Почему — объясню позже.)
Возвращаемые значения функции WaitForMultipleExpressions показаны в следующей таблице. Если заданное выражение становится истинным, WaitForMultipleExpressions возвращает индекс этого выражения относительно WAIT_OBJECT_0. Если взять тот же пример, то при освобождении объектов "поток" и "процесс" WaitforMultipleExpressions вернет индекс в виде WAIT_OBJECT_0 + 2.
| Возвращаемое значение | Описание |
| От WAIT_OBJECT_0 до (WAIT_OBJECT_0 + число выражений - 1) | Указывает, какое выражение стало истинным |
| WAIT_TIMEOUT | Ни одно выражение не стало истинным в течение заданного времени. |
| WAIT_FAILED | Произошла ошибка. Чтобы получить более подробную инфор мацию, вызовите GetLastError. Код ERROR_TOO_MANY_SECRETS означает, что Вы указали более 61 выражений, a ERROR_SEC RET_ТОО_LONG — что по крайней мере в одном выражении указано более 63 объектов. Могут возвращаться коды и других ошибок |
Реализация критической секции: объект-оптекс
Критические секции всегда интересовали меня. В конце концов, ссли это всего лишь объекты пользовательского режима, то почему бы мне не реализовать их самому? Разве нельзя заставить их работать бсз поддержки операционной системы? Кроме того, написав собственную критическую секцию, я мог бы расширить ее функциональность и в чем-то даже усовершенствовать. По крайней мере я сделал бы так, чтобы она отслеживала, какой поток захватывает защищаемый ею ресурс. Такая реализация критической секции помогла бы мне устранять проблемы с взаимной блокировкой потоков с помощью отладчика я узнавал бы, какой из них не освободил тот или иной ресурс.
Так что давайте без лишних разговоров перейдем к тому, как реализуются критические секции. Я все время утверждаю, что они являются объектами пользовательского режима. На самом дслс это не совсем так. Любой поток, который пытается войти в критическую секцию, уже захваченную другим потоком, переводится в состояние ожидания. А для этого он должен перейти из пользовательского режима в режим ядра. Поток пользовательского режима может остановиться, просто войдя в цикл ожидания, но это вряд ли можно назвать эффективной реализацией ждущего режима, и поэтому Вы должны всячески избегать ее.
Значит, в критических секциях есть какой-то объект ядра, умеющий переводить поток в эффективный ждущий режим. Критическая секция обладает высоким быстродействием, потому что этот объект ядра используется только при конкуренции потоков за вход в критическую секцию. И он не задействован, пока потоку удастся немедленно захватывать защищаемый ресурс, работать с ним и освобождать его без конкуренции со стороны других потоков, так как выходить из пользовательского режима потоку в этом случае не требуется. В большинстве приложений конкуренция двух (или более) потоков за одновременный вход в критическую секцию наблюдается нечасто.
Мой вариант критической секции содержится в файлах Optex.h и Optex.cpp (см, листинг на рис. 10-1). Я назвал её оптимизированным мьютексом — оптексом и реализовал в виде С++-класса.
Просмотрев файл Optex.h, Вы увидите, что в основном они являются элементами структуры SHAREDINFO, а остальные — членами самого класса. Назначение каждой переменной описывается в следующей таблице.
| Переменная | Описание |
| m_lLockCount | Сообщает, сколько раз потоки пытались занять оптекс Ее значение равно 0, если оптекс не занят ни одним потоком. |
| т dwThreadId | Сообщает уникальный идентификатор потока — владельца оптекса Ее значение равно 0, если оптекс не занят ни одним потоком |
| m_lRecurseCount | Указывает, сколько раз отеке был занят потоком- владельцем. Ее зна чение равно 0, если оптекс не занят ни одним потоком. |
| m_hevt | Содержит описатель объекта ядра "событие", используемого, только если поток пытается войти в оптекс в то время, как им владеет другой поток. Описатели объектов ядра специфичны для конкретных процес сов, и имении поэтому данная переменная не включена в структуру SHAREDINFO. |
| m_dwSpinCount | Определяет, сколько попыток входа в оптекс должен предпринять по ток до перехода в состояние ожидания на объекте ядра "событие". На однопроцессорной машине значение этой переменной всегда равно 0. |
| m_hfm | Содержит описатель объекта ядра "проекция файла", используемого при разделении оптекса несколькими процессами Описатели объек тов ядра специфичны для конкретных процессов, и именно поэтому данная переменная не включена в структуру SHAREDINFO. В однопро цессном оптексе значение этой переменной всегда равно NULL |
| m_psi | Содержит указатель на элементы данных оптекса, которые могут ис пользоваться несколькими процессами. Адреса памяти специфичны для конкретных процессов, и именно поэтому данная переменная не включена в структуру SHAREDINFO. В однопроцессном оптексе эта пе ременная указывает ни блок памяти, выделенный из кучи, а в межпро цессном — на файл, спроецированный в память. |
Регионы в адресном пространстве
Адресное пространство, выделяемое процессу в момент создания, практически все свободно (незарезервировано). Поэтому, чтобы воспользоваться какой-нибудь его частью, нужно выделить в нем определенные регионы через функцию WirtualAlloc (о ней — в главе 15) Операция выделения региона называется резервированием (reserving). При резервировании система обязательно выравнивает начало региона с учетом так называемой гранулярности выделения памяти (allocation granularity). Последняя величина в принципе зависит от типа процессора, но для процессоров, рассматриваемых в книге (x86, 32- и 64-разрядных Alpha и IA-64), — она одинакова и составляет 64 Кб.
Резервируя регион в адресном пространстве, система обеспечивает еще и кратность размера региона размеру страницы. Так называется единица объема памяти, используемая системой при управлении памятью. Как и гранулярность выделения ресурсов, размер страницы зависит от типа процессора В частности, для процессоров x86 он равен 4 Кб, а для Alpha (под управлением как 32-разрядной, так и 64-разядной Windows 2000) — 8 Кб. На момент написания книги предполагалось, что IA-64
тоже будет работать со страницами размером 8 Кб. Однако в зависимости от результатов тестирования Microsoft может выбрать для него страницы большего размера (от ( 16 Кб).
NOTE:
Иногда система сама резервирует некоторые регионы адресного пространства в интересах Вашего процесса, например, для хранения блока переменных окружения процесса (process environment block, PEB). Этот блок — небольшая структура данных, создаваемая, контролируемая и разрушаемая исключительно операционной системой. Выделение региона под РЕВ-блок осуществляется в момент создания процесса.
Кроме того, для управления потоками, существующими на данный момент в процессе, система создает блоки переменных окружения потоков (thread environment blocks, TEBs). Регионы под эти блоки резервируются и освобождаются по мере создания и разрушения потоков в процессе.
Но, требуя от Вас резервировать регионы с учетом гранулярности выделения памяти (а эта гранулярность на сегодняшний день составляет 64 Кб), сама система этих правил нс придерживается Поэтому вполне вероятно, что грапицы региона, зарезервированного под РЕВ- и ТЕВ-блоки, не будут кратны 64 Кб. Тем не менее размер такого региона обязательно кратен размеру страниц, характерному для данного типа процессора.
Если Вы попытаетесь зарезервировать регион размером 10 Кб, система автомати чески округлит заданное Вами значение до большей кратной величины. А зто значит что на x86 будет выделен регион размером 12 Кб, а на AIpha — 16 Кб.
И последнее в этой связи Когда зарезервированный регион адресного простран ства становится не нужен, ею следусч вернуть в общие ресурсы системы. Эта опера ция — освобождение (releasing) региона — осуществляется вызовом функции VirtualFree
Ресурсы
Компилятор ресурсов генерирует двоичное представление всех ресурсов, используемых Вашей программой. Строки в ресурсах (таблицы строк, шаблоны диалоговых окон, меню и др.) всегда записываются в Unicode Если в программе не определяется макрос UNICODE, Windows 98 и Windows 2000 сами проводят нужные преобразования Например, если при компиляции исходного модуля UNICODE не определен, вызов LoadString на самом деле приводит к вызову LoadStringA, которая читает строку из ресурсов и преобразует ее в ANSI. Затем Вашей программе возвращается ANSI-представление строки.